
企業の財務戦略において、単なる数字の整理を超えた戦略的思考が求められる時代となりました。多くの経営者が「なぜ予算と実績に差が生じるのか」「どうすれば的確な経営判断ができるのか」という課題に直面しています。
その解決策として注目されているのがFP&A(Financial Planning & Analysis)です。FP&Aは財務計画と分析を通じて、企業の未来を見据えた意思決定を支援する重要な機能です。従来の経理業務とは異なり、過去の数字を整理するだけでなく、将来の事業展開を見据えた戦略的な分析と提案を行います。
本記事では、FP&Aの具体的な定義から業務内容、必要なスキル、そして実際の導入方法まで詳しく解説します。読み終える頃には、FP&Aが企業の競争力向上にどれほど貢献するかを明確に理解していただけるでしょう。
FP&Aの基本定義とは?
FP&Aは企業の財務機能における戦略的パートナーとして位置づけられます。単純な数値管理ではなく、ビジネスの成長を支える分析と計画立案が中核となります。従来の財務部門が「守り」の役割だったのに対し、FP&Aは「攻め」の財務として企業価値向上に直接貢献します。
出典元:日本CFO協会 FP&A(経営企画スキル検定)公式サイト https://www.cfo.jp/fp_and_a/
FP&Aの財務計画・分析
FP&AはFinancial Planning & Analysisの略称で、企業の財務計画策定と業績分析を担う専門機能です。具体的には予算編成、業績予測、財務分析、経営報告の4つの柱で構成されます。
海外の先進企業では、経営の意思決定を支える機能として「FP&A」という部門がCFOの傘下として確立されています。特にデジタル化によって月次決算プロセスや月次報告書が自動化されていく中で、「FP&A」という機能こそがCFO組織における重要な仕事というトレンドにあります。
近年、事業環境の変化が激しくなる中で、従来の年次予算だけでは対応が困難になっています。FP&Aでは四半期や月次での予測見直し、シナリオ分析による複数の将来像の検討を行います。また、KPI設定と継続的なモニタリングにより、事業の健全性を常に把握できます。
日本企業で注目される背景と理由
2023年3月に、東京証券取引所がPBR(株価純資産倍率)の低迷する上場企業に改善策を開示し、実行するように促したことに対応するなかで、FP&Aへの注目がさらに高まったことが大きな転換点となりました。
この要請の具体的な対象は、プライム市場及びスタンダード市場の全上場会社であり、実際の対応状況を見ると、プライム上場企業で自律的に取り組みを進める企業と今後の改善が期待される企業が86%(1406社)、開示に至っていない企業が14%(237社)という状況です。
特に上場企業では、四半期決算説明会での投資家との対話において、具体的な数値根拠と将来見通しの説明が求められます。単なる業績報告ではなく、戦略的な分析に基づいた成長ストーリーの提示が必要です。また、M&Aや事業再編が活発化する中で、財務面での統合効果測定や投資判断にFP&Aの専門性が欠かせません。
出典元:KPMG FP&A(Financial Planning & Analysis)が導く経営管理の未来形 https://kpmg.com/jp/ja/home/insights/2024/11/202411-fpa-financial-management.html
海外と日本のFP&Aの違いとグローバル展開の可能性
海外企業のFP&Aは職能として確立されており、CFOの直下に位置する戦略的部門として認識されています。欧米企業では予算策定から業績分析、投資判断まで一貫してFP&Aが担当し、経営会議での発言権も大きいのが特徴です。
日本でFP&Aを導入しているのは一部の企業のみで、導入している企業の多くは、外資系です。日本でFP&Aの導入があまり進んでいない理由として、欧米ではCFO(最高財務責任者)のもとにFP&Aが置かれている一方で、日本ではFP&Aに近い業務が財務・経理・経営企画などで行われていることが挙げられます。
しかし、グローバル展開を進める日本企業では、海外子会社の財務管理や統合報告においてFP&Aの重要性が増しています。現地法人の業績管理、為替リスクの分析、投資効果の測定など、複雑な財務課題への対応が必要です。
FP&Aの主な業務内容
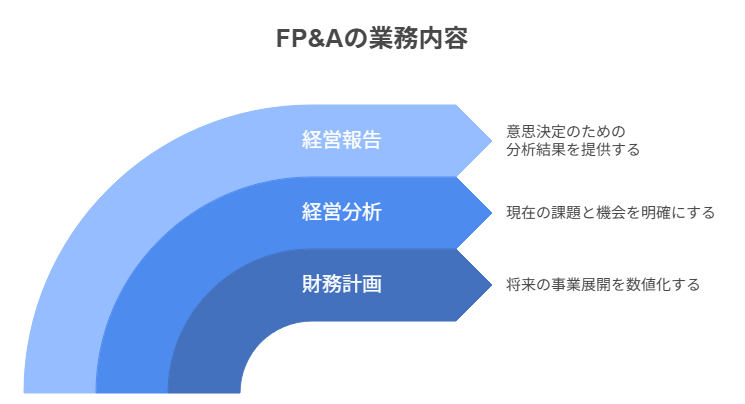
FP&Aの業務は企業の財務戦略を支える3つの主要領域で構成されます。財務計画では将来の事業展開を数値化し、経営分析では現状の課題と機会を明確化します。そして経営報告では、これらの分析結果を意思決定に活用できる形で提供します。
財務計画(Budgeting & Forecasting)の作成
財務計画の核となるのは予算編成と業績予測です。年次予算では各部門からの計画を統合し、全社的な収益目標と投資計画を策定します。しかし、変化の激しい事業環境では年次予算だけでは不十分であり、四半期や月次での見直しが重要になります。
ローリング・フォーキャストと呼ばれる手法では、常に12~18ヶ月先までの業績を予測し続けます。市場動向や競合状況の変化を迅速に計画に反映できます。また、ベースケース、楽観ケース、悲観ケースの複数シナリオを用意することで、リスク管理と機会創出の両面に対応します。
新規事業投資や設備投資においては、IRR(内部収益率)やNPV(正味現在価値)を用いた財務評価により、投資判断の客観性を確保します。予算達成に向けたアクションプランの策定と進捗管理も重要な業務です。
経営分析(Financial Analysis)と業績評価
経営分析では財務データを多角的に分析し、事業の健全性と成長性を評価します。売上分析では商品別、地域別、顧客別の収益構造を把握し、成長ドライバーを特定します。コスト分析では固定費と変動費を分離し、損益分岐点や限界利益率の改善余地を検討します。
KPI分析では売上高営業利益率、ROE、ROIC等の財務指標に加え、顧客満足度や従業員エンゲージメント等の非財務指標も含めて総合的に評価します。競合他社との比較分析により、業界内での位置づけと差別化ポイントを明確化します。
月次の業績レビューでは予算との差異分析を行い、差異の要因を定量的に説明し、対策の優先順位を示します。これにより、経営陣は迅速かつ的確な意思決定を行うことができます。
経営陣へのレポーティングと戦略立案支援
経営報告では複雑な財務データを経営陣が意思決定に活用できる形で整理・提示します。月次の経営会議では業績サマリー、主要KPIの推移、予算との差異分析を簡潔に報告します。四半期決算では投資家向けの説明資料作成も支援し、財務ストーリーの一貫性を確保します。
戦略立案支援では、M&A案件の財務デューデリジェンス、事業計画の妥当性検証、投資効果の事前・事後評価を担当します。新規事業立ち上げにおいては事業計画の財務面での実現可能性を検証し、必要な資金調達計画も策定します。
FP&Aは経営判断に直接的に寄与する管理会計制度や自由度の高い切り口での分析や予測を可能にする情報基盤を武器にして、事業ポートフォリオの組換えや企業の魅力を高めるように働きかける「社内投資家」というべき存在として機能します。
FP&A担当者に必要なスキルと資格
FP&A担当者には財務・会計の専門知識に加え、ビジネス感覚とコミュニケーション能力が求められます。技術的なスキルだけでなく、経営陣や各部門との協働により組織全体の成果向上に貢献する能力が重要です。
アナリティカルスキルと会計知識の重要性
FP&Aの基盤となるのは高度な分析スキルと会計知識です。財務会計では連結決算、税効果会計、リース会計等の複雑な処理を理解し、経営への影響を正確に把握する必要があります。管理会計では原価計算、予算管理、差異分析の手法を活用し、事業の収益構造を明確化します。
統計学の知識により回帰分析や時系列分析を用いて、売上予測の精度向上を図ります。ExcelやTableau等のツールを駆使したデータ可視化により、複雑な情報を経営陣にとって理解しやすい形で提示します。SQL等のデータベースクエリ言語の習得により、大量のデータから必要な情報を効率的に抽出できます。
また、事業戦略の理解により、財務分析を経営課題の解決に直結させる思考力も重要です。論理的思考力と仮説構築力により、データの背景にある事業の本質を見抜く洞察力が求められます。
コミュニケーション能力とプレゼンテーションスキル
FP&Aには経理・財務をバックグラウンドとした専門的なスキルに加えて、ビジネスパートナーとして経営者や事業部門のトップと対等にディスカッションし、人や組織を動かすことができるコミュニケーションスキルが求められます
FP&Aの成果は分析結果を組織に浸透させ、行動変容につなげることで測られます。経営陣への報告では複雑な財務情報を簡潔に要約し、意思決定に必要なポイントを明確に伝える能力が必要です。
プレゼンテーション資料の作成では、データの羅列ではなくストーリー性のある構成により、聞き手の理解と共感を得る技術が求められます。グラフや表の効果的な活用により、複雑な数値関係を直感的に理解できる形で表現します。
出典元:BlackLine FP&A(Financial Planning & Analysis) https://www.blackline.jp/resources/glossaries/FP&A.html
公認会計士やCMAなどの取得メリット
専門資格の取得はFP&Aキャリアにおいて大きなアドバンテージとなります。FP&A(経営企画スキル検定)は、一般社団法人日本CFO協会が提供するもので、アメリカのAFP(Association for Financial Professionals)が認定しているFP&Aのグローバル資格「FPAC」取得に向けた入門プログラムとして注目されています。
公認会計士資格では会計基準の深い理解と監査経験により、財務報告の信頼性確保と内部統制の構築に貢献できます。米国公認管理会計士(CMA)は管理会計と財務管理に特化した資格で、予算管理や業績評価の専門性を証明します。
MBA(Master of Business Administration)は、人的資源管理や情報・マーケティング、財務会計、経済学、統計学などの科目によって構成されています。取得に向けて経営学を学ぶことで経営に関する専門的な知識とスキルを習得でき、FP&Aで役立つ実践力も身に付けることが可能です。
これらの資格は転職市場での評価向上に加え、社内でのキャリアアップ においても重要な要素となります。
FP&A導入の進め方と成功のポイント
FP&A機能の導入は組織の財務管理レベルを飛躍的に向上させますが、成功には戦略的なアプローチが必要です。単なるシステム導入ではなく、組織文化の変革と人材育成を含めた総合的な取り組みが重要となります。
FP&A部門の組成と社内連携体制
FP&A(Financial Planning & Analysis)とは、CFOの直下にあり、会計・財務をバックグラウンドに持ちながら、CEOや事業部長の意思決定プロセスに貢献する、ファイナンス的知見と事業戦略に関する深いスキルが求められる専門的かつ戦略的な機能として位置づけることが重要です。
FP&A部門の立ち上げでは、CFO直下の独立した組織として位置づけることが重要です。経理部門から分離することで、過去の数値整理から未来志向の分析へと役割を明確に転換できます。初期メンバーは会計知識と分析スキルを併せ持つ人材を中心に、3~5名程度の小規模チームから開始するのが効果的です。
各事業部門との連携体制では、月次の業績レビュー会議を通じて定期的な情報交換を行います。営業部門からは受注状況や市場動向、製造部門からは生産計画やコスト変動要因、人事部門からは人員計画等の情報を収集します。
データ分析ツール・システム選定のポイント
FP&A業務を効率的に進めるためには、適切なツール選定が何より大切です。MGI Researchの調査を見ると、上場企業向けクラウド型FP&Aツール市場は2026年までに約85億ドル規模まで成長し、年成長率は28%という驚異的なペースで拡大すると予測されています。この急成長する市場の中で、自社に最適なソリューションを見つけることが企業の競争力を左右します。
既存システムとの連携を第一に考える
まず検討したいのが、既存システムとの相性です。ERPシステムと自動で連携できるツールを選べば、これまで手作業で行っていた転記作業によるミスを根本的になくすことができます。予算管理システムでは、各部門が使いやすい予算入力画面があること、承認プロセスが自動化されること、そして実績との差異をすぐに確認できる機能があることが選定の決め手となります。
データを「見える化」するBIツールの威力
リアルタイムで業績を把握し、必要に応じて詳細データまで掘り下げて分析するには、優れたBIツールが必要です。SAP Analytics Cloudのような最新の財務分析ソフトウェアには、高度な分析機能が最初から備わっているため、複雑な財務分析も効率よく実行できます。グラフや表で視覚的に表示されるため、経営陣への報告時にも説得力が増します。
柔軟な働き方を支えるクラウド環境
最近では、リモートワークが当たり前になってきましたが、クラウドベースのソリューションを選んでおけば、オフィスにいなくても高度な財務分析が可能です。場所を選ばずに重要な意思決定に必要なデータにアクセスできるため、ビジネスのスピードが格段に向上します。
運用プロセスの設計
FP&A業務の標準化により、一貫性のある分析と報告を実現します。月次クロージングでは経理部門との役割分担を明確にし、速報値による暫定分析から確定値による最終報告までのスケジュールを設定します。
FP&Aを効果的に機能させるためには、リアルタイムで財務データを分析できるシステムやツールが欠かせません。しかし、多くの日本企業では、依然として手作業や従来型のシステムに依存しており、そのためデータ分析のスピードや精度に課題が残っています。この課題を解決するため、自動化とプロセス標準化が重要となります。
KPI設定では、財務指標と非財務指標をバランス良く組み合わせ、事業戦略との整合性を確保します。レポーティング・テンプレートの標準化により、経営陣が必要とする情報を効率的に提供できます。
出典元:Zeem FP&Aコラム 第10回 日本におけるFP&Aの現状 https://www.zeem.jp/useful/column/fp_a_in_the_japan/
まとめ
FP&Aは企業の財務戦略を変革する重要な機能として、日本企業においても急速に注目が高まっています。2023年3月の東証PBR改善要請を契機に、多くの企業がFP&A導入を検討し始めており、従来の経理業務を超えた将来志向の分析と戦略立案が求められています。
FP&A導入成功の鍵は、専門人材の育成、適切なツール導入、そして信頼性の高いデータ基盤の構築にあります。特に、ERP、CRM、人事システムなど複数システムからのデータ統合は大きな課題となっています。
このようなデータ統合の課題において、TROCCO のようなクラウド型データ統合・分析基盤サービスが強力な支援を提供します。複雑なデータパイプライン構築を簡素化し、FP&A担当者の手作業時間を大幅に短縮することで、より高度な分析や戦略的思考に集中できる環境を実現します。
データドリブンな経営判断の実現こそが、変化の激しいビジネス環境において企業の競争優位性と持続的成長を支える原動力となるでしょう。






