
課題・問題
時系列でプロダクト・顧客データを取得できないデータ基盤

貴社サービスと「TROCCO」導入以前のデータ活用について教えてください。
上田 健太郎様(以下、敬称略):弊社ではPark Directのプロダクトデータや顧客データに加え、月極駐車場の月額料金の参考になる不動産相場や賃料相場といった非プロダクト系のデータも取り扱っています。「TROCCO」導入以前はこれらの情報を可視化するためにオープンソースのBIツールであるRedashとPark Directのデータベースを直結して分析していました。
顧客データに関しては、カスタマーサービスソリューションであるZendeskからCSVとして抽出し、スプレッドシート上でカスタマーサクセスの各担当者がそれぞれ関数を組んでレポーティングするというシンプルな構成です。
弊社のPark Directは月極駐車場の貸主と借主をつなぐツーサイドプラットフォームです。貸主側のカスタマーサクセスでは主に月極駐車場の管理会社さんを顧客としており、スプレッドシート上のデータを参考にPark Directの活用支援などを行っていました。
「TROCCO」導入以前のデータ基盤で抱えていた課題をお聞かせください。
上田:以前のシステム基盤でも業務を進めることに問題はありませんでしたが、定期的かつ連続的に観測される時系列データを自動で取得する仕組みはない状態でした。そのため、以前のデータが履歴として保存されておらず、その時点での値しか確認できませんでした。しかし、YoYや月次推移といったデータは必要との判断から、Redashからデータを抽出してスプレッドシートに毎月記録して、時系列データを作成していました。
ただありがたいことにPark Directを利用してくださる貸主と借主は増加しているため、その方法だとスプレッドシートに残さなければならないデータのサイズが大きくなり、ついには大きくなりすぎて業務が止まってしまう懸念がありました。
スプレッドシート上で保管できるセル数は2024年11月現在、1,000 万セルが上限であり、それ以上は同じシート内でデータを残すことができません。実際に、「TROCCO」を導入する直前の頃はスプレッドシート上の計算処理の完了まで30分かかってしまうことも珍しくありませんでした。
またデータ以外の業務も忙しく、データ基盤の維持、運用にリソースを割けていなかったことも課題でした。実際に昨年には貸主と借主の急増によってシステム負荷と業務負荷が高まってしまい、データモデルを刷新したことがありました。それに伴い、大量のレポーティング用の集計クエリの修正も必要になり、さらに日々の分析依頼もこなす必要もあったため、今後ますますデータ基盤の運用にリソースを割くのは物理的に不可能と感じていたのです。
なぜ「TROCCO」を選んだのか
少人数のデータ基盤チームでも問題なく運用できることが導入の決め手に

「TROCCO」はどのようなきっかけでお知りになりましたか。
上田:企業規模が大きければオープンソースのETLツールで自社開発することがあります。しかし、当時のAnalyticsチームは私ひとりのチーム(その後、増員)でしたので、開発できたとしてもその後の運用が困難になるのは明白でした。そのため、マネージドなETLツールを導入したいという思いは以前よりずっと抱えていました。そうした中で弊社に出資していただいているVCの方のご紹介をきっかけに出会ったのが「TROCCO」でした。primeNumber社は弊社と同じくスタートアップ企業、かつ急成長中とのことでデータ基盤の刷新とともに導入を検討することになりました。
「TROCCO」を含むETLツールはどのように比較検討されましたか。
上田:国内国外問わず、複数のETLツールを比較検討しました。まず、外資系のETLツールと比較検討では、導入後の運用やサポート面を重視しました。当時比較検討していた外資系のETLツールは日本に拠点が置かれておらず、導入後のサポートに不安がありました。「TROCCO」の場合、日本の企業であるprimeNumber社から日本語の手厚いサポートを受けられることが魅力でした。
次に比較したのが対応しているコネクタ数で、特に必要としていたのが顧客データを管理しているZendeskとのコネクタでした。Zendeskには1日で数千件のチケット(問い合わせ)が届いており、一つひとつ効率的に対応していくために問い合わせ内容の傾向や効率化のヒントとなる情報を得ることは優先度の高い課題でした。外資系のETLツールでは、Zendeskに対応していないことが多かったのですが、導入検討をしていた当時から「TROCCO」ではZendesk Supportとのコネクタに対応していたため、魅力に感じていました。
コスト面でも比較検討をしています。検討当初は正直そこまで大きな差が出るとは思っていなかったのですが、他社ツールでは従量課金制の料金形態にもかかわらず、肝心の単価が「ASK」と表示されており、毎月の利用料を概算することができませんでした。一方で「TROCCO」は、データ転送時間に比例する従量課金制であることや各プランの料金、サービス内容がシンプルであったため、判断しやすいと感じました。
「TROCCO」導入の決め手をお聞かせください。
上田:少人数のデータ基盤チームでも問題なく運用できることです。導入を検討していた当時から国内企業での導入事例が掲載されており、さらにひとりデータチームのような少人数でも導入できているとの記事を拝見しました。
少人数のデータ基盤チームでも運用するためには、GUIベースのノーコードでデータ転送設定ができることと、担当者による手厚いサポートの2つが重要です。弊社の場合、「TROCCO」の導入の手順だけでなく、時系列データを蓄積していくためのアーキテクチャ設計についても密に相談に乗っていただけたので、大変ありがたかったです。

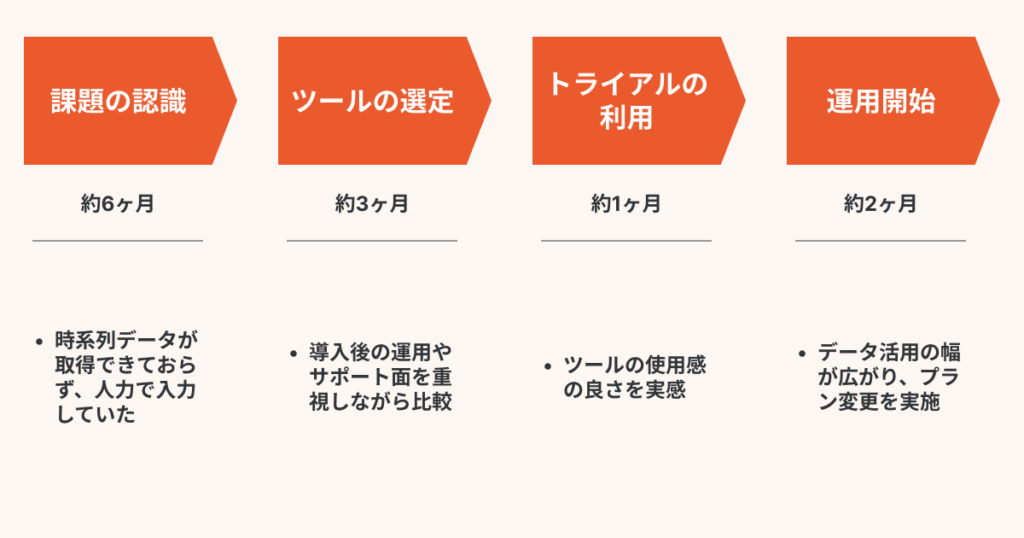
導入までのスケジュール・過程
少人数データチームを支えた導入サポート。スタートアップに「TROCCO」が最適な理由

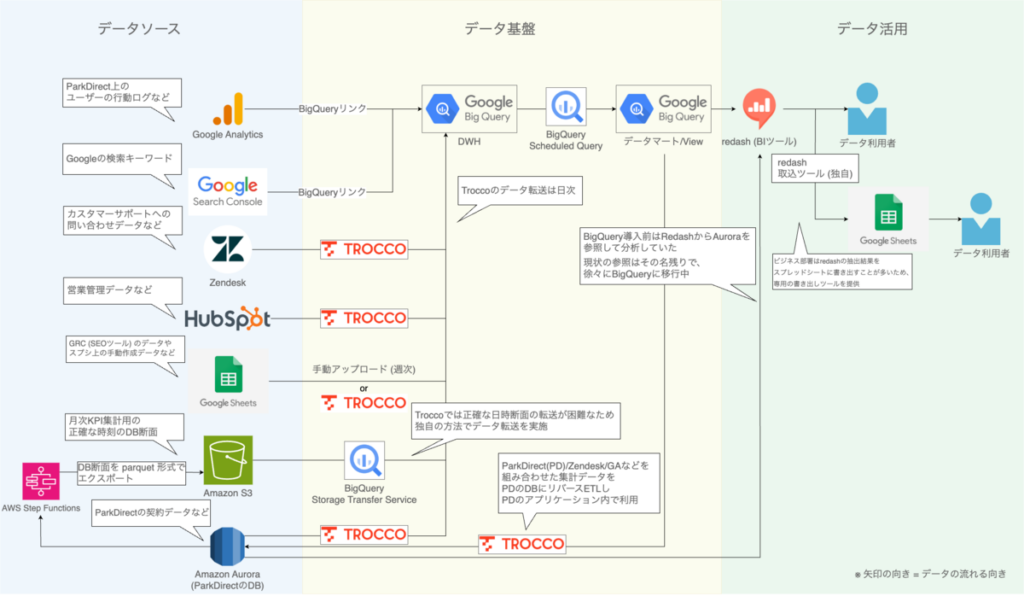
「TROCCO」導入後、どのようなデータ基盤を構築しましたか。
上田:Amazon RDS内のプロダクトデータやZendeskの顧客データ、スプレッドシート上の一部にマスタデータを「TROCCO」で集約し、DWHであるGoogle BigQueryに蓄積。その後は以前から導入しているBIツールにデータを流し、ダッシュボードで可視化するというデータ基盤を「TROCCO」導入後に構築しました。
現在ではプロジェクト管理ツールのJIRAのチケット、MAツールのHubspot上の顧客データについてもデータソースとして連携しています。
「TROCCO」導入のタイミングでは、弊社からはどのようなサポートがありましたか。
上田:Park Directのデータをヒストリカルに蓄積するという方針と実装パターンは弊社内である程度固まっていたので、その内容についての壁打ち相手となっていただきました。変更した方が良い設定にコメントいただいたり、同じような課題を解決した他社事例をご紹介いただいたりと、少人数のデータチームにとってありがたい存在でした。おかげさまで、時系列データを取得、蓄積するという目的は達成できました。
また、ミーティングのたびに最新の機能リリースについてご説明いただいたことも印象に残っています。たとえば、「TROCCO」によるデータ統合の方法にUPSERTという選択肢が増えた際にすぐご案内いただきました。これは転送データの各行に対し、マージキーの値が対象テーブルの該当列に存在していた場合はその行の値が更新され、存在しなかった場合は追記されるという機能です。定期的にデータを転送し、常に最新のデータに更新されていることが求められていたため、重宝している設定です。
スタートアップ視点で特に評価いただいているポイントがあればお聞かせください。
上田:料金プランを手軽に更新できることは、事業が急拡大して扱うデータ量もデータソースも増えていくスタートアップには適していると思います。弊社の場合は、事業規模が拡大したタイミングで新しいプランをご紹介いただきました。このプラン変更のご提案は、取り扱うデータが急増し、Analyticsチームからの要望が増えていた弊社にとってまさに渡りに船でした。
導入後の効果
時系列データを取得できるデータ基盤を構築。カスタマーサクセスや資金調達にデータで貢献

「TROCCO」の導入によって、どのような成果を得ることができましたか。
上田:もし今回構築したデータ基盤をオープンソースのETLツールで構築していた場合、構築・運用を当時のチーム体制で回すのはとても大変だったと思います。特に、Park Directのデータベースはモデルの変更が頻繁に発生するので、カラム追加削除への追従に多くのリソースを費やしていたと思います。
その他にも、データの取り込みフェーズの苦労が解消されたことで、Analyticsチームはデータを横つなぎにすること、そして分析業務に集中できるようになったことは大きな成果です。
「TROCCO」の導入後、ビジネスサイドの業務はどのように変化しましたか。
上田:プロダクトデータと顧客データを時系列で取得、蓄積するという目的を達成しただけでなく、SaaSビジネスとして当たり前に押さえておくべきKPI指標や数値を人力ではなく、仕組みとして集計できるようになりました。それによってヒューマンエラーによる数値の不一致や表記ミスがなくなり、より精度の高い数値で分析ができるようになっています。
また、ビジネスサイドから求められるデータを抽出し、取りまとめる時間が大きく短縮できました。以前は各チームが掲げるミッションに対する現在地を示す数値やデータを出すために30分から1時間ほどかかっていましたが、今ではBIツール上から確認できるようになっています。
カスタマーサクセスの各担当者はZendesk上の顧客データをより気軽に分析できるようになりました。具体的な施策としては、カスタマーサポートの健康状態をモニタリングし、特定のカスタマーサクセス担当者に案件が偏ってしまった場合は積極的に分散するようにオペレーションを改善しました。そのことによって、問い合わせの電話に対する応答率を改善する一助になっています。
「TROCCO」の導入によって、どのような成果を得ることができましたか。
上田:2024年8月に総額45.7億円のシリーズBラウンドの資金調達を実施させていただいたのですが、この裏側でも「TROCCO」を活用しています。以前の資金調達時には、毎月所定の時間にデータチームがスナップショットすることで作成した時系列データを使用していたのですが、今回の資金調達時に作成した投資家向けレポートは「TROCCO」で集約、蓄積したデータを活用しました。以前よりもデータの精度が高くなり、経営層の要望を満たす切り口のデータを提供できたことで、少なからず資金調達にも貢献できているものと考えています。
今後の展望
社内だけでなく駐車場オーナーへもデータを提供し、月極駐車場のDXを進めていきたい

今後のデータ活用の展望をお聞かせください。
上田:これまではデータ基盤にあるデータを活用する人が限られていましたが、「TROCCO」導入後の現在は社内にデータ基盤による恩恵を受ける担当者が増え、その先の管理会社のオーナーの方への提案にも活用できるシーンが増えてきました。
以前はオーナーの方からデータの問い合わせがあれば、各担当者が個別にデータを取得し、分析したものを提供していました。しかし、最新のデータではなかったり、レポート作成に手間と時間がかかったりと、さまざまな課題がありました。これらの課題についても「TROCCO」の活用で解決していくため、今後はオーナーさんへもBIツールのダッシュボードの一部を提供するといったデータ活用の範囲を広げていく取り組みも強化していきたいと考えています。
スタートアップ企業でデータ基盤を担当している方へアドバイスをお願いします。
上田:データ基盤を構築するのは手段であって目的ではありません。データの先にどのような事業課題があり、その解決にはどのようなデータが必要で、そのデータを得るためにはどのようなデータ基盤が必要なのかを整理し、「事業課題の解決に繋がるデータ基盤」を構築することが重要だと思います。
また、アウトカムを得るまでの速さが重視されるスタートアップ企業にとっては、データ基盤を長時間かけて整えることよりも、直接ビジネスに貢献できるデータ分析の方にリソースを割いた方が好ましい場合が多いです。だからこそ、少人数で運用可能なデータ基盤を手軽に構築できる「TROCCO」の導入は有力な選択肢だと思います。






