
大量かつクリーンなデータが強みの「@cosme」
山本 泰毅様(以下、敬称略):本セッションでは、弊社のデータ基盤のこれまでとこれからにおける「TROCCO®」の位置づけ、今後の大規模なデータ基盤に求めることをお話しさせていただきます。
まず、弊社のデータ基盤がどのような事業ドメインの中で運用されているかを説明させていただきます。私達アイスタイルグループは、生活者視点で未来を見据え、マーケットのあり方そのものをデザインする会社です。主なサービスとして、23年前にスタートした「@cosme(アットコスメ)」という化粧品の口コミメディアを運営しています。
2022年11月現在でMAUが1,400万人と、20〜30代の女性を中心に長く愛され、リアルの店舗やEC、グローバルにも事業を広げています。会員数は680万人、口コミ件数は1,840万件(会員数・口コミ件数ともに2022年11月24日時点の数値)、さらに登録されている化粧品メーカー様やブランド様からいただける情報を持っており、非常に大量かつクリーンなデータの宝庫となっていることが特徴です。
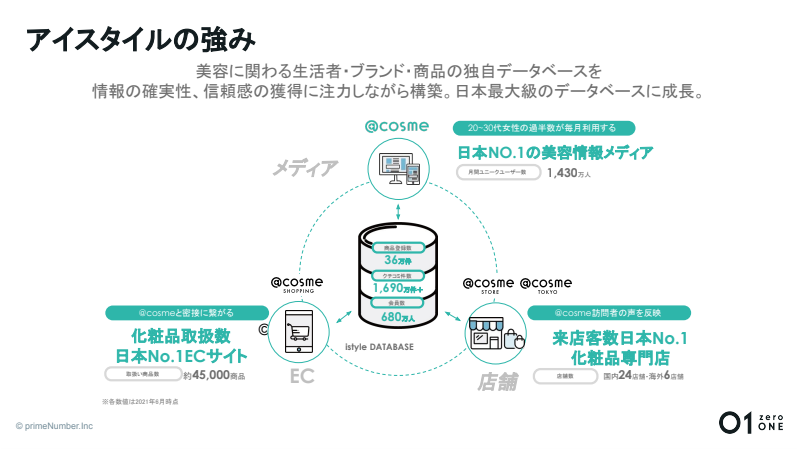
我々の事業の強みは、ユーザー情報、メディア、EC、小売りから構築されているプラットフォーム内で、このクリーンな化粧品に関するマスター情報を共有する仕組みを構築していること。サービス同士の結びつきが事業の根底にあるため、あらゆるサービスプロダクトはデータの同期やID連携を前提に設計されています。これらの「ヒト・モノ・コト・バショ」のデータは、認知から購買までのマーケティングプロセスを一気通貫で分析できるデータベースになっています。
これらのデータから、ユーザーとブランドの繋がりを可視化するマーケティング支援のSaaS「ブランドオフィシャル」を提供しています。ただ分析するだけでなく、データからターゲティングされたメールの送付や、「@cosme」内の記事フィードへのレコメンドなど、具体的なアクションにまで繋がることを強みにしています。
Phase①:これまでのデータアナリストの改善
1. データ活用の遍歴

山本(泰):ここからはデータ基盤の話として、データアナリスト目線でデータ活用の遍歴をまずは振り返らせていただきます。
①データ専売の時代
当初はエンジニア部門の一部が企画やセールスからの依頼を受け、データ抽出のみを行う状態でした。そのため、抽出したデータがどのように活用されるかまでは重要視はされていません。この状況ではSQLで書いたクエリに再現性がなく、少し条件が違うだけでクエリをコピペし、また作成するということの繰り返しでした。
この時代の課題は、属人的な対応によって、より深い洞察ができなかったことや、品質が不揃いなデータが多く生成されていたことです。
②編纂・再編の時代
この時代では、データ基盤と活用部門の部隊が立ち上がり、フルカスタマイズのSQLを減らすことから着手しました。
データ基盤がシンプルなものかつ、クエリの行数を減らすパターンの網羅性を早期に高めるため、ビューでの実装を行いました。共通ビューを参照することで提供データの品質が安定し、あわせてBIツールも導入しています。データを利用するユーザーが手元で条件変更の対応ができるようになり、上昇傾向だった依頼件数を減少させることに成功しました。
③データ民主化の時代
しかし、今度は共通のビューだけでは耐えられない依頼のケースが増加しました。急拡大するデータ活用の需要に応えられなくなったため、中央集権的な体制から事業部自らがデータを扱えるように介入方法を変えていきます。
一部の部門への導入に留まっていたBIツールを全社向けに導入し、さらには教育プログラムの実践も行いました。また、データアナリストを抱える専門部署も事業部に発足しました。
一方で、データのガバナンスよりも拡大を優先してきたため、各部門管理のデータマートが量産され、数値がずれてしまうレポートも多くできてしまうようになったのです。
2. 「TROCCO®」導入の狙いと効果

土佐 智紀様(以下、敬称略):データの抽出や分析はデータエンジニアがDigdagで実行しており、データアナリストは必要になるたびに依頼をする状態でした。しかし、データの民主化が進み、事業部が自らデータを扱えるようになったことで、事業部側でBigQueryでクエリをスケジュールするケースが増えてしまいました。
これにより、部門ごとでデータパイプラインやデータマートが量産され、再利用性が低い状態になってしまいました。また、BigQueryでスケジュールされたクエリはその仕様上、エラー通知が作成者にのみメールで届くため、作成者本人以外はエラーに気づくことも修正することもできない、保守性が低い状態になってしまいました。
そこで「TROCCO®」を導入し、データアナリストでも品質が高いデータマート構築ができる平易な環境を整備しました。
既存ツールから「TROCCO®」移行で大変だったこと、気を付けたこと
①データパイプラインの全量の洗い出し
土佐:さまざまなチームが、多種多様なデータソースを対象にデータパイプラインを組んできたため、調査範囲が膨大でした。また、現在利用しているか不明だったり、作成者がわからなかったりといった背景から、どのパイプラインを移管対象とするかといった問題も発生しました。
これらの問題は、泥臭く定期的に棚卸をするよう、何度もチームに対してデータパイプラインの洗い出しをプッシュをすることで、なんとか解決しました。今後は、もし同じような作業が発生したとしても「TROCCO®」だけを確認すればよいという環境になっています。
②導入前のルール整備
データエンジニアだけなく、データアナリストも利用しやすい環境を作ることを目的に掲げてルール整備を進めました。以下のような、必要最低限のルールだけ設定し、細かい部分は随時フィードバックを受けながらアップデートしています。
- 命名規則の統一
- 「TROCCO®」のラベル等を用いたSLA(復旧基準)やサービス把握などの保守管理
- メモ欄の有効活用/「TROCCO®」外サービス連携/エラー対処法/レビュー
従来のデータエンジニアがルールを決めてデータアナリストが従うという環境から、ルールや分析環境までもデータアナリストの意見を反映できる環境になっています。
③「TROCCO®」エバンジェリストとしての難しさ
「TROCCO®」に限らず、SaaSはただ導入して終わり、では意味をなさないと思っています。「TROCCO®」上で作成されたデータパイプラインの視認性や結合条件をすぐに確認し、生成されるパイプラインの傾向を把握できるようにしたいと考えました。
また、新規ツールである「TROCCO®」を社内に広めることも難しいポイントです。「TROCCO®」の導入効果を社内に発信することで、利用するメリットを理解してもらい活用を促していきました。具体的には以下の内容をメリットとして共有しています。
エラー通知
Googleのスケジュールクエリでは、設定者本人以外への通知設定ができないため、エラーが起きても気づけないことが多い。データを活用する現場側で数値がおかしいということが判明し、修正依頼を受けてエラー対応する状況だった。エラーが発生した時点で通知が来ることで、現場の人の余分な作業量を減らすことに成功。
SLA基準再考
エラーへ素早く対応できることで、依頼ベースでのエラー対応から自発的なエラー対応が可能になった。つまりエラー対処の時間のハンドリングが可能になった。「このワークフローは、どのくらいのペースで復旧すれば良いか」ということが可視化でき、SLA基準を改めて考えることができた。また、SLA基準に準拠した対応を行えるようになったことで、タスクを計画的に進められるようになった。
「TROCCO®」導入の効果
土佐:部や個人などで自由にパイプラインを作成しており、データパイプラインの全貌が不明でした。しかし、「TROCCO®」の導入によって、173のワークフローと237のデータマート、それぞれのデータパイプラインの作成者や目的が、当事者以外でも分かるようになっています。(2022年9月時点)
また、以前は急激なデータ抽出や分析などのニーズに対してエンジニアの工数が不足していたため、マートの作成がうまく進んでいませんでした。「TROCCO®」の導入によって、データアナリストでも品質が高い構築ができるようになったことで、マートの作成が進むようになりました。
また、不具合対応の課題も解決できています。「TROCCO®」導入以前は、作成したワークフローは、作成した本人にしか復旧できないという属人的な保守体制でした。しかし今では、Slack連携や適したSLAを定められる環境になったことで、エラーの検知/復旧は他の人でも対応できるようになり、結果的にエラー対応負荷を軽減することができました。
Phase②:これからの基盤全体の改善
山本(泰):現在進めている、統合データ分析基盤の構築について、3つのテーマでお話をさせていただきます。これまでは、データエンジニアのリソースが限られた中で開発運用を行っていたため、そこで生じた課題がいくつもありました。過去の反省を踏まえ、属人化を防ぐために採用している開発アプローチについてのお話をさせていただきます。
1. 現行基盤の課題感共有
①現行基盤におけるデータ品質課題
山本(泰):アイスタイルではかなり多くのパイプラインが存在しているものの、テストに関する方法論が確立されていないという課題がありました。そのため、テストを十分にしていないまま提供したデータに誤りがあったり、障害に繋がってしまったことも。
現在進めている統合データ分析基盤では、分散しているパイプラインを集約し、中央集権的にデータを提供できる基盤を構築することを目的にしています。同時に、データのバリデーションテストや加工時にテストのフローを組み込むことで品質を保証したデータを提供していきたいですね。
その一方で、中央集権的にパイプラインを構築し、テストをしっかり行うことはスピード感が落ちる要素でもあります。そこで加工パイプラインにdbtと呼ばれるツールを採用し、エンジニアリングの力でスピードを落とさず、品質向上に繋げたいです。
②分断されたパイプラインによる運用・実装コスト
アイスタイルでは収集パイプラインとしてOSSのEmbulkを、加工パイプラインにはDigdagを採用していました。それぞれバッチ的にジョブで運用していたため、パイプラインごとに分断が発生したり、運用実装コストがかかる状態になっていたのです。
これらの問題を解消していくため、データの収集と加工は1つのワークフローで管理していきたいと考えました。
2.属人化解消を見据えた開発アプローチ
山本(泰):現行基盤における属人化、標準化の課題として、以下の5つの課題が挙げられます。
- データのテスト方法が揃っていない
- パイプラインが分断しており、復旧する上で学習コストが高い
- システム仕様の意図や背景を答えられる人が居ない、もしくは忘れてしまう
- 依頼ベースで加工パイプラインを都度作成しており、パイプラインの作成方法が標準化されていない
- 依頼ベースでデータを提供しているため、データマートがサイロ化している
ADRを利用した開発の意思決定文化の醸成

須賀 俊文様(以下、敬称略):エンジニアから仕様を伝えられた際、どのような経緯で決まったかが不明なため、改善提案をする際に、その背景から確認する必要があります。また、運用中の問題発生による改修を行おうとした際に、当時の意思決定の背景が分からず、関わったメンバーからヒアリングする必要もでてきます。過去の意思決定は、議事録に埋もれて忘れてしまうことや、人の入れ替わりが原因で背景が確認できなくなるケースも、珍しくありません。
そこで弊社では、日々の小さな意思決定であっても、ADR(Architecture Decision Record)として背景の情報を残す方針にしました。

私たちのチームでは、日々の小さな意思決定をADRとしてまとめ、過去に決めた方針を変更した方がよいと判断した場合、過去に採用したADR自体を修正するのではなく、新しいADRを作成して過去のADRを否決するという形にしています。これによって、履歴が残る形となり、新しく入ってきたメンバーが、当時の意思決定の経緯を振り返ることができるようになっています。
全体パイプラインのパッケージ化
須賀:アイスタイルでは、データを利用したいという依頼者のリクエストに対して、その都度集計用のクエリを作成していたのですが、業務の標準化がされていませんでした。パイプラインの実装に関しても、過去に実装されたものを利用するという対応が多く、品質や生産性で問題を抱えていました。
そこで私たちはパイプラインをパッケージ化することにしました。開発生産性を向上させるだけでなく、業務一覧を洗い出すことで業務フローや定義を整備し、開発の進め方自体の属人性を排除しています。また、パイプラインでさまざまなツールを利用する予定のため、チュートリアル用のドキュメントを作成し、オンボーディングも重視した開発を行いたいと考えています。
データのモデリング工程の見直し
須賀:依頼者の要望にその都度対応してパイプラインを構築していくと、いくつものデータマートが立ち上がり、サイロ化してしまうことになります。弊社でも結果的に、中間過程で汎用的なウェアハウスを構築、整備することができず、データの再利用性が低い状態になっていました。
そこで、データのモデリング手法として、Data Vaultを採用し、データの拡張性、再利用性を高めたいと考えています。
また、これまではデータのレイヤリングや、どのような加工をするのかに関しても取り決めがない状態でした。そこで特定のレイヤーではどんな処理を行うのかというルールを「モデリング標準」として定め、開発時の属人性を排除しようと考えています。
Data Vaultとは、長期的に履歴保管することを目的としたデータベースモデリング手法
須賀:Data Vaultとは、複数の業務システムから入ってくるデータを、長期的に履歴保管することを目的としたデータベースモデリング手法です。ストレージの費用が安くなったこともあり、長期的に履歴を保管することを目的としているのが特徴の1つです。
一般的なデータの変更例で言いますと、テーブルの物理削除や論理削除が挙げられます。アイスタイルの具体例として、化粧品ブランドの統廃合によって、テーブルの中身が変更になるというケースがあります。単純にデータを洗い替えて収集していると、利用してるデータの変更に基盤として対応することができないという課題があります。
そこでモデリング手法としてData Vaultを採用し、問題の影響を回避、最小化することを考えています。
アイスタイルが考える「TROCCO®」の利用フェーズと次のステップ

須賀:アイスタイルが「TROCCO®」の採用に踏み切った当時、データエンジニアのリソースが枯渇しており、データ基盤の運用に追われていました。その結果、データマートの構築や整備といったデータに価値を加えて届ける活動に時間を割くことがなかなかできていなかったのです。
しかし「TROCCO®」を導入することによって、データのアナリストがマートの構築や整備を推し進め、データの分析業務や業務改善に取り組むことができるようになりました。その過程で見えてきた課題を踏まえ、エンジニア採用で体制を強化しつつ、次のデータ基盤の構築に向けたコンセプトを作り上げることもできています。
ここまでの意思決定に至るまで、「TROCCO®」なしでは到達できませんでした。感謝の言葉で、本セッションを締めさせていただきます。ありがとうございました。









