
課題・問題
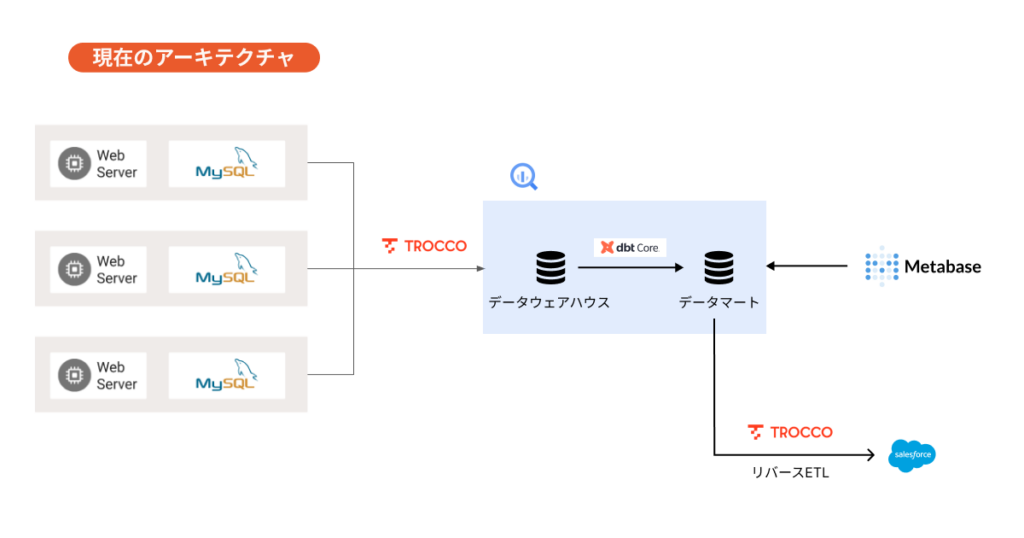
Embulkを自社で使用し、データ基盤を構築、運用しようと試みたものの、数か月かかる見込みだった

貴社では、どのようなデータ活用戦略を打ち出しているのでしょうか。
宮﨑 章太様(以下、敬称略):弊社では、データ資産の蓄積と活用が、社内およびユーザーの意思決定に貢献し、事業規模の拡大に好循環を促すと考えています。私が所属するデータ機能チームは、データ資産の蓄積と活用を支援するため、活用要望の吸い出しおよび遂行支援と、それを遂行しやすいようなデータ基盤の整備を大きなミッションに掲げています。
エンジニアの中でもプラットフォームチームは、データ基盤の構築と運用が滞りなく進む状態を担保することに責任を負っており、今回の取り組みであるETLツール「TROCCO®︎」やBIツールなどの導入、運用が担当業務です。
どのようなきっかけから、データ活用への注力を決定したのでしょうか。
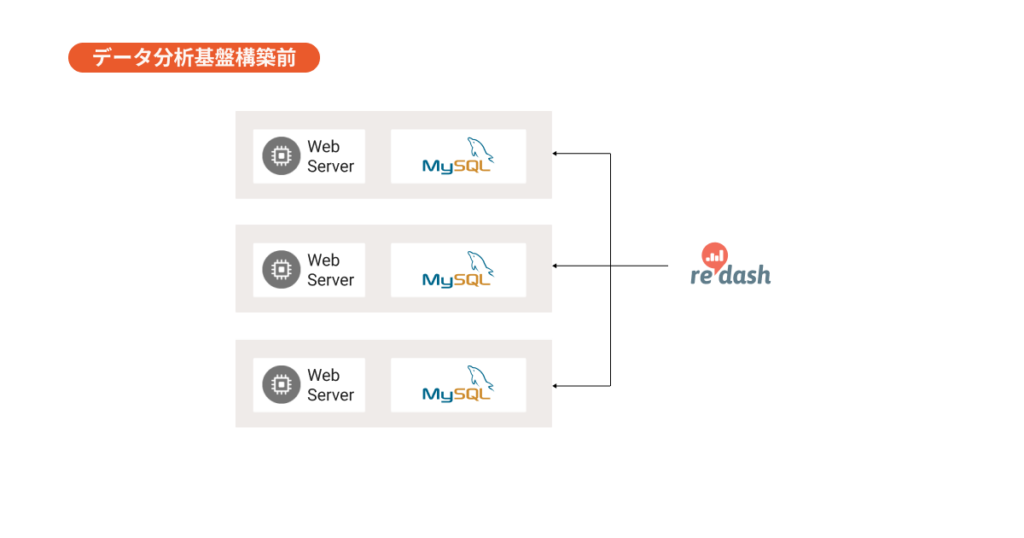
宮崎:HERP Hireをリリースした初期は、Redashをデータベースに直接つないで運用してました。リリースから3年が経った頃、お客様から「採用データをもっと可視化したい」とのご要望をいただくことが増え、さらに人材サービス市場全体でデータ活用に対する関心が高まったこともあり、いよいよデータ活用に注力していくことを2021年頃に決断しました。
データ活用において、当時はどのような課題を抱えていたのでしょうか。
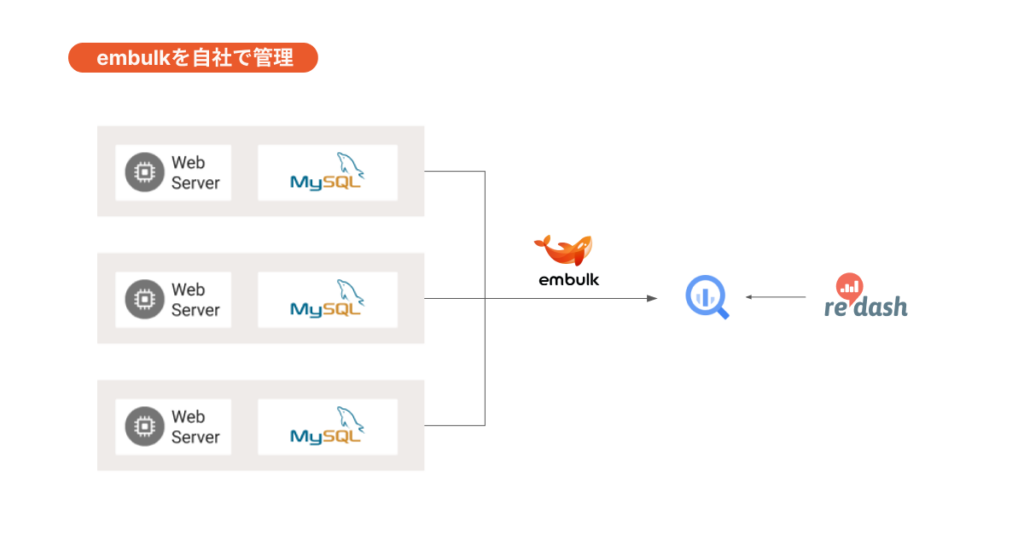
宮崎:当初はオープンソースのETLツールであるEmbulkを自社で使用し、データ基盤を構築、運用しようと試みたのですが、社内のリソースだけでは難しいと判断しました。複数サービスのデータベースやテーブルごとに構築しなければならず、工数がかかりすぎてしまいそうでした。一つのデータベースをEmbulk経由でGoogle BigQueryに乗せるまでに2, 3か月もかかっており、データを集計して検証する以前のデータ転送でリソースを費やしてしまっては本末転倒です。
また、事業をさらに拡大していくにあたって、レベニュー側であるIS(インサイドセールス)、FS(フィールドセールス)、CS(カスタマーサクセス)内で扱うデータや言語を共通化したほうが良いのではないかとの意見が挙がりました。お客様一社あたりの売上や採用関連のデータなど、部門ごとにバラバラな数字を見ていては社内一丸となったアプローチができません。
こうした課題を解決するため、さまざまなユースケースに対応できる、アジリティが高いデータ基盤を構築するため、最適なETLツールの導入を模索しはじめました。
なぜ「TROCCO®︎」を選んだのか
将来的なサービス拡大を視野に、データソースの豊富さを特に重視して選定

どのようなきっかけで「TROCCO®︎」を知りましたか?また、比較検討の際に重視した要素を教えてください。
宮崎:業務委託でお力添えいただいているアドバイザーの方に相談してみたところ、紹介されたETLツールが「TROCCO®︎」でした。他社のツールとも比較検討を実施し、以下の3点をまず確認しました。
・国内企業が開発、運営していること
・Embulkベースで開発されていること
・データソース(対応コネクタ)が豊富であること1
3つ目の要素として挙げた「データソース(対応コネクタ)が豊富であること」は特に重要でした。MySQLだけでなく、SalesforceやGoogle Analytics、Google Spreadsheetsからのデータ転送なども検討していたため、将来的な拡張に耐えられるかどうかが判断ポイントでした。
比較検討の際に評価いただいた「TROCCO®︎」の機能を教えてください。
宮崎:プログラミングETLの機能が実装されているのは高評価でした。もしテンプレートETLでは実行できないデータがあったとしても、自分たちでプログラムを書いて変換処理をすればよいと考えていました。実際に「TROCCO®︎」の導入後には、プロダクトの機能の有効化によって集計するかを判断するプログラミングETLを書き、直接データ変換処理をしています。
加えて、リバースETL(Reverse ETL)も便利だなと感じた機能でした。以前より、現場のCS担当者から「お客様がどの機能を、どのくらい使用しているかSalesforce上から確認できないか」との相談を受けていたため、SalesforceからGoogle BigQueryへのデータ転送だけでなく、Google BigQueryからSalesforceへと逆のデータ転送もできないかと考えていたのです。
「TROCCO®︎」に実装されているリバースETLを活用することで、わざわざBIツールとSalesforceを両方開かずともSalesforceのみでお客様のデータを確認できるため、普段の業務を効率化するだけでなく、商談時に一画面でお客様の状況を確認し、有効なご提案が可能になります。
こうしたメリットを考慮した結果、スムーズに社内で決裁を得ることができ、「TROCCO®︎」の導入が決定しました。

導入までのスケジュール・過程
わずか1週間、しかもセルフオンボーディングで導入が完了

「TROCCO®︎」の導入から運用が軌道に乗るまで、どの程度の期間がかかりましたか?
宮崎:私たちが必要としていた機能の初期設定はトライアル期間中にすべて完了できていたので、本契約からわずか1週間後には、ほぼ想定通りに「TROCCO®︎」の運用を実現していました。
本契約後に着手した設定のひとつがSlack通知です。データの変換処理中にエラーが発生すればSlackへ通知が届くという仕組みで、これによりエラーの確認漏れを防ぐことが可能です。社内に限定したデータ活用であれば迅速なエラー対応は必要なかったかもしれませんが、弊社では最終的にユーザーさまへデータ基盤をご提供し、データを採用活動の強化に活用していただきたいと考えています。
そのため、エラーをしっかり監視することはサービスへの信頼性を維持するという観点から重要な要素であると考えています。
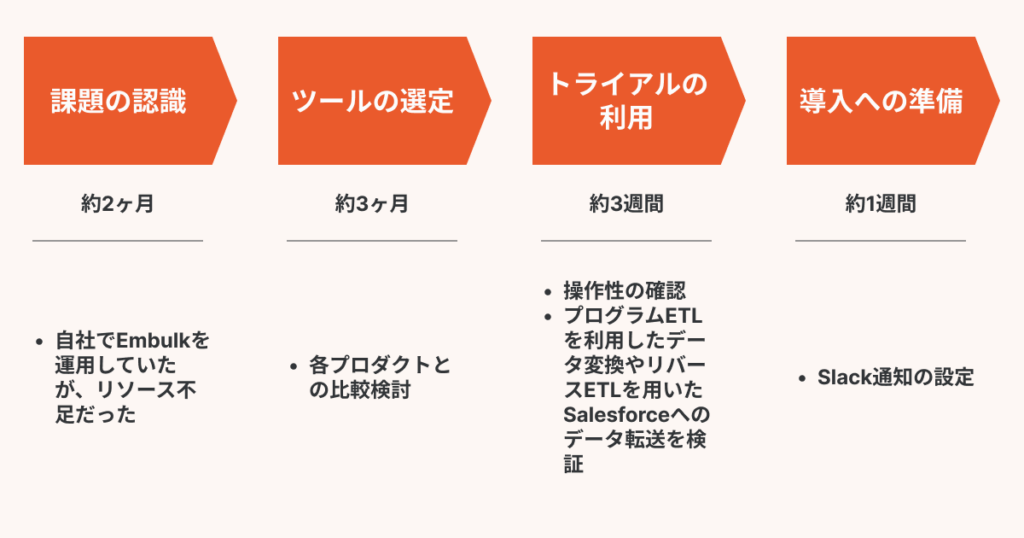
「TROCCO®︎」の導入にあたって、どのようなサポートを受けましたか?
宮崎:今振り返ると、ほとんどサポートを受けずにセルフオンボーディングができていたと思います。MySQLやGoogle BigQueryと接続する際の認証情報の渡し方などについていくつか質問したくらいで、その質問にもSlackから迅速にご回答いただけました。日本語でのスムーズな対応で助かりました。
導入後の効果
1つのDBに2, 3か月かかっていたデータ連携、整備が、たった1週間でいくつも設定できるように

「TROCCO®︎」の導入で、どのような成果を得ることができましたか?
宮崎:Embulkを自社で使用し、データ基盤を構築していた場合、おそらく2,3か月かけて1つのデータベースしかデータ連携、整備ができていなかったでしょう。しかし「TROCCO®︎」を導入したおかげで、たった1週間でいくつものデータベースのデータ変換処理が可能になり、スピーディにデータ活用環境を構築することができました。
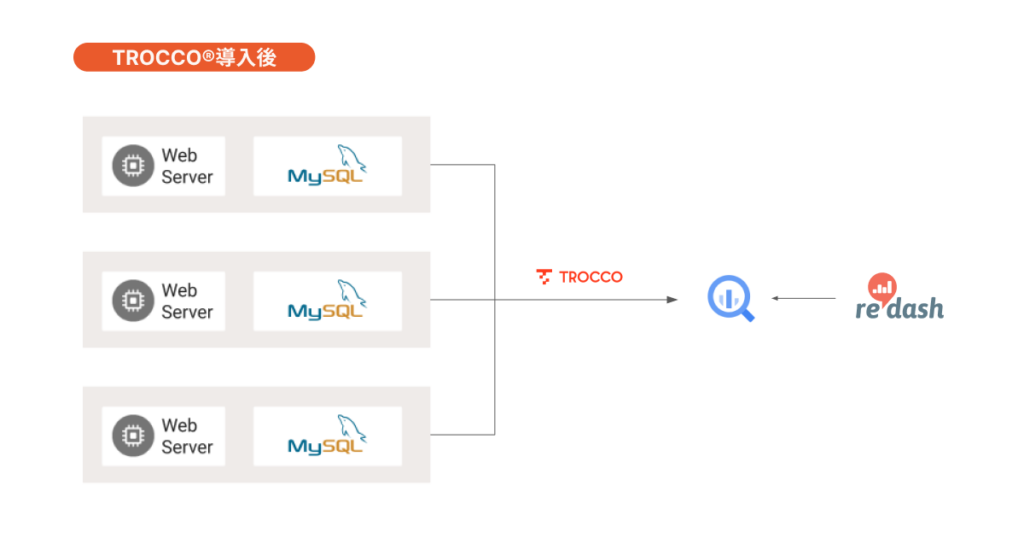
「TROCCO®︎」を実際に操作して、どのような点を評価いただいていますか?
宮崎:エンジニアでなくても分かりやすく、クリックだけでも日々の運用ができる操作感が便利だと思います。たとえば、テーブルやカラムが増減するとSlackへ通知が飛んでくるのですが、その通知内のURLをクリックして「TROCCO®︎」へログイン。あとは指示通りの箇所を3つほどポチポチとクリックしていけば、設定変更が完了します。その後、データが同期される次回のタイミングを待つだけです。
以前のEmbulkをベースにしたデータ基盤のままだったら、テーブルやカラムの増減に気が付かないばかりでなく、設定変更も非常に面倒で着手をためらっていたと思います。
「TROCCO®︎」の導入で、業務にどのような変化がありましたか?
宮崎:「TROCCO®︎」によってデータを可視化できるようになり、最も恩恵を受けているのはCSのメンバーだと思います。Salesforce上でお客様のデータを確認できるようになり、顧客満足度をさらに高めるご提案ができていると聞いています。
また、最近ではお客様向けにBIツールの閲覧環境を構築し始めています。まだまだ実装途中の段階ですが、HERP Hireの管理画面にオープンソースのBIツールのダッシュボード画面を埋め込むことで、HERP Hire上に蓄積された採用データを自由に組み合わせて分析することが可能になる予定です。2024年6月時点では、先行で数社にテスト提供しており、将来的にはすべてのユーザー様への提供を開始したいと考えています。
こうしたデータ可視化の機能拡張によって、お客様へ提供できるサービス価値を向上できれば、長期的な売上げの向上や事業の進化につながるはずです。
今後の展望
今後はデータ基盤における採用データの管理強化や安定性の向上に取り組みたい

今回の取り組みを受けて、今後のデータ活用の展望をお聞かせください。
宮崎:もともとさまざまなユースケースに対応できる、アジリティが高いデータ基盤の構築を目指していましたが、現在はおよそ70点くらいのデータ基盤を実現できたと感じています。「TROCCO®︎」の導入でデータ基盤のアジリティをかなり向上できたので、今後は個人情報のかたまりである採用データの管理をさらに強化していくこと、そのうえでメタデータやドキュメント整理にも着手していきたいですね。
「TROCCO®︎」については引き続き、お客様やレベニュー側のデータ活用を支援していくこと、そのためにもデータ基盤の安定性を向上させていくために活用していきたいと考えています。
データ基盤の構築に課題を感じている方へ、メッセージをお願いします。
宮崎:私たちもまだまだ道半ばですが、データ基盤を構築するにはまずデータが得られなければ何も始まりません。一歩目を踏み出すためにも、まずはETLツールでデータ連携することが大事だと考えており、そういう観点から「TROCCO®︎」はおすすめできるツールです。
そこからデータ活用していく中で、「TROCCO®︎」のデータマート機能やdbt連携機能も活用し、自社サービスに最適なデータ基盤を構築してみてはいかがでしょうか。
[service_banner]






