
課題・問題
「ひとりデータチーム」から始まったデータ基盤の構築。目指すは安定して運用できる体制

Product Divisionのミッションや体制についてお聞かせください。
前側 将様(以下、敬称略):Product Divisionにはエンジニアが20〜30名在籍しており、うち8名がデータを扱うチームに所属しています。そのうち、普段の業務で「TROCCO®︎」を使用しているのが4名です。
この4名はいわゆるアナリティクスエンジニアという役割のチームで、非エンジニアとデータをつなぎ、多くの社員がデータを扱える状態にすること、そして最終的にはデータの民主化を実現することがミッションです。プロダクトから得られるデータをしっかり蓄積し、社内で活用しやすいようにまとめること、さらにデータを整形してお客さまに共有することも業務範囲になります。
まだ実現できていませんが、データチームだけがデータの転送業務を担うのではなく、さまざまな部署の非エンジニアの方でもデータを加工したい、データを転送したいと思ったとき、すぐに自分でデータを収集できる状態が理想的だと考えています。
どのようなシーンでデータを活用しているのでしょうか。
前側:社内の事例を挙げると、カスタマーサクセスの領域でのデータ活用が特に進んでいます。弊社のカスタマーサクセスは「ハイタッチ」であることが特徴です。専任の担当者が手厚くサポートを行い、さまざまな提案をしながら寄り添って支援していくスタイルです。
より良いサポートのためには、お客さまが運営するコミュニティの状況を理解することが必要不可欠です。そのため、コンテンツの閲覧データを含むユーザーの行動データを積極的に活用しています。
社内では主にBIツールのLooker Studioで可視化できるようにしており、お客さまに対してもLooker Studioの閲覧権限をお渡しすることもあれば、スプレッドシートに取りまとめて展開することもあります。
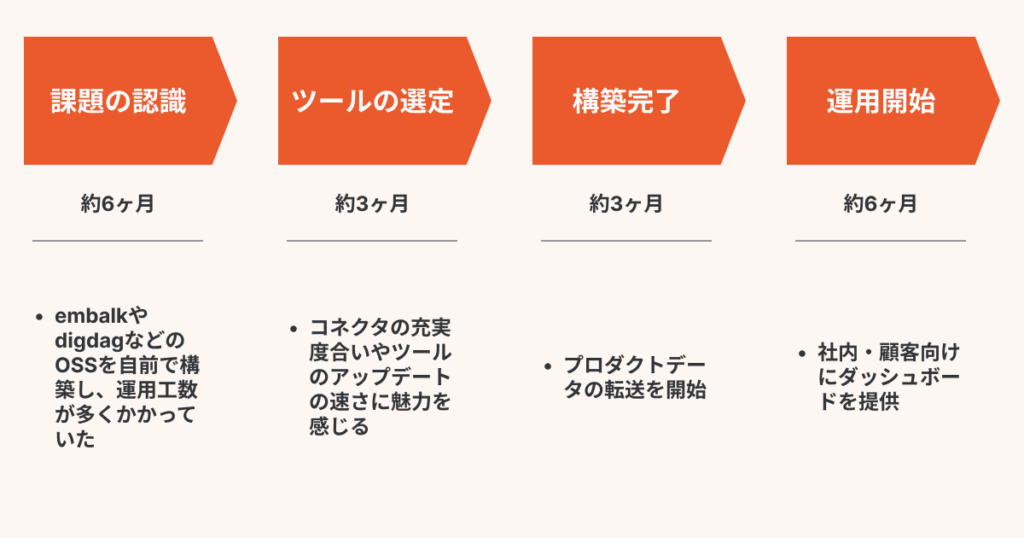
「TROCCO®︎」導入以前は、どのような課題を抱えていたのでしょうか。
前側:「TROCCO®︎」を導入した当時、アナリティクスエンジニアの役割を果たせる社員が前任者の1名しかいない状況でした。そのため、社内やお客さまからのデータの要望にお応えしきれず、業務が回らない状況が続いていました。社内からデータ処理のワークフロー構築の依頼があると、OSSのソフトウェアでゼロから構築する必要があり、数営業日はその他のデータの分析業務や処理業務をストップせざるを得なかったのです。
ちょうど会社としても拡大フェーズに入ったタイミングで、データのニーズも日々増加していました。そこで少ないエンジニアリソースでもデータ基盤を構築し、安定して運用できる体制を目指すことになりました。
なぜ「TROCCO®︎」を選んだのか
ツール導入はメンバーの採用条件とセットで考える。誰でも扱えるツールの使いやすさが決め手に

ツール導入に向けて、どのような点を重要視していますか。引き続きOSSのソフトウェアを自分たちで構築することは検討されましたか。
前側:マネージャーとして、業務の属人化を避けるべきだと考えています。もし以前のように自分たちで構築した場合、今後のデータエンジニア採用では「OSSのソフトウェアを扱えること」が必須条件になってしまいます。そうなると採用のハードルが上がり、ただでさえ難しいデータエンジニアの採用がさらに困難になってしまうでしょう。特にエンジニアのような専門職の場合、導入するツールと採用条件はセットで考えなければならないのです。
そのため、引き続きOSSのソフトウェアを使うのではなく、誰でも扱いやすいETLツールを導入すべきと判断しました。
ツールの比較検討では、どのような要素を重視していましたか。
前側:1つ目のポイントは、日本製ツールのコネクタが充実している点です。当時比較検討していた他社のETLツールは海外の企業が開発、運営していたので、今後日本のユーザー向けに機能や対応コネクタが開発されるか未知数だったのです。実際に使用していませんが、Yahoo!検索広告といった日本向けのデータを扱っていることは、今後の開発にも期待ができると感じました。
2つ目のポイントがアップデートが速い、かつユーザーが求めている機能がどんどん実装されていたことです。特に印象的だったのが、マネージドデータ転送の機能に、Salesforceのオブジェクトを一括で取り込み、紐づく転送設定も一括で作成できる機能が追加されたことでした。SalesforceのAPIは、一度に書き出せるデータの量や仕様が独特な部分があり、データ転送のパイプラインを内製で構築するのは正直大変でした。こうしたユーザーの困りごとをよく理解し、かゆいところに手が届くような機能をどんどん追加してくださり、ありがたいと思っています。
そしてSlackによる担当者のサポートが手厚いことが3つ目のポイントです。前任者からも「うまくいかないことがあっても、質問に対して親身になってスピーディに回答いただいた」と聞いています。
加えてカスタマーサクセス担当の方が、エンジニアを経験されている方が多く、私たちエンジニアと違和感なく会話できるのは素晴らしいなと感じました。普段のコミュニケーションでも「ここまで理解されているのか」と驚くことが多々あります。
この3つのポイントを評価し、また導入・運用のコストも大きな負担にならないことから「TROCCO®︎」の導入が決定しました。

導入までのスケジュール・過程
データ担当が一人でも導入できるシンプルさ。社内だけでなく、お客さま向けにもデータを活用

「TROCCO®」の導入はどのように進行しましたか。
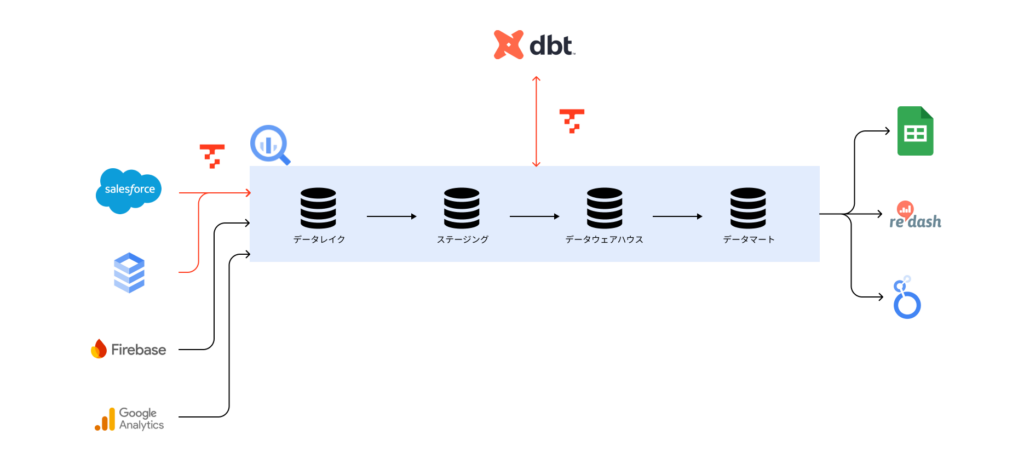
前側:2022年から導入がスタートし、順次データ転送の設定を進めていきました。まずはプロダクトデータが格納されている、マネージドデータベースのCloud SQL for MySQLとSalesforceからGoogle BigQueryへの転送パイプラインを定義しています。その後、Google BigQueryからデータを可視化するためのBIツールやスプレッドシートへのデータ転送を構築しました。ワークフローのスケジュール実行機能を活用し、毎日夜間にデータが転送、実行されています。
「TROCCO®」の導入は、前任者がprimeNumber社が共催されているData Engineering Studyで勉強しながら、最新のトレンドに沿った形で進めました。今では浸透してきましたが、Google BigQuery内でデータレイク、ステージング、データウェアハウス、データマートといった層に分けているのもそのひとつです。
また、データの転送処理は基本的に「TROCCO®」を使用しているのですが、主にお客さまに展開しなければならないデータで変換処理やデータモデリングといった加工処理にはdbt Cloudを使用しています。
「TROCCO®」の導入後、どのようなサポートがありましたか。
前側:「TROCCO®」導入当初から同じSlackチャンネルを使用して担当の方にサポートいただいてきました。担当の方からの過去のサポートやアドバイスはSlackのチャンネル内に蓄積されているので、私のように後から転職してきても「TROCCO®」がどのように使われてきたのかを理解する手助けになります。
ただ、弊社の転送パイプラインはずっと安定稼働しているイメージでして、深刻なトラブルに対する個別サポートなどはありませんでした。普段の業務の中で生じた質問に対しても、遅くともご連絡したその日のうちに一次回答をいただけるので、コミュニケーションで不満を感じたことはありません。
エンジニア組織以外では「TROCCO®︎」をどのように活用しているのでしょうか。
前側:コミュニティに属するユーザーの行動データを、お客さまにも把握、分析いただくため、一部のお客さまにLooker Studioのダッシュボードを共有しています。毎月1〜2件ほどの頻度で、お客さまが追加されるたびに転送パイプラインの構築に「TROCCO®︎」を活用している状態です。パイプラインの設定やオペレーションは型化されており、データチーム以外の社員でも簡単に設定ができ、現在1名が担当しています。
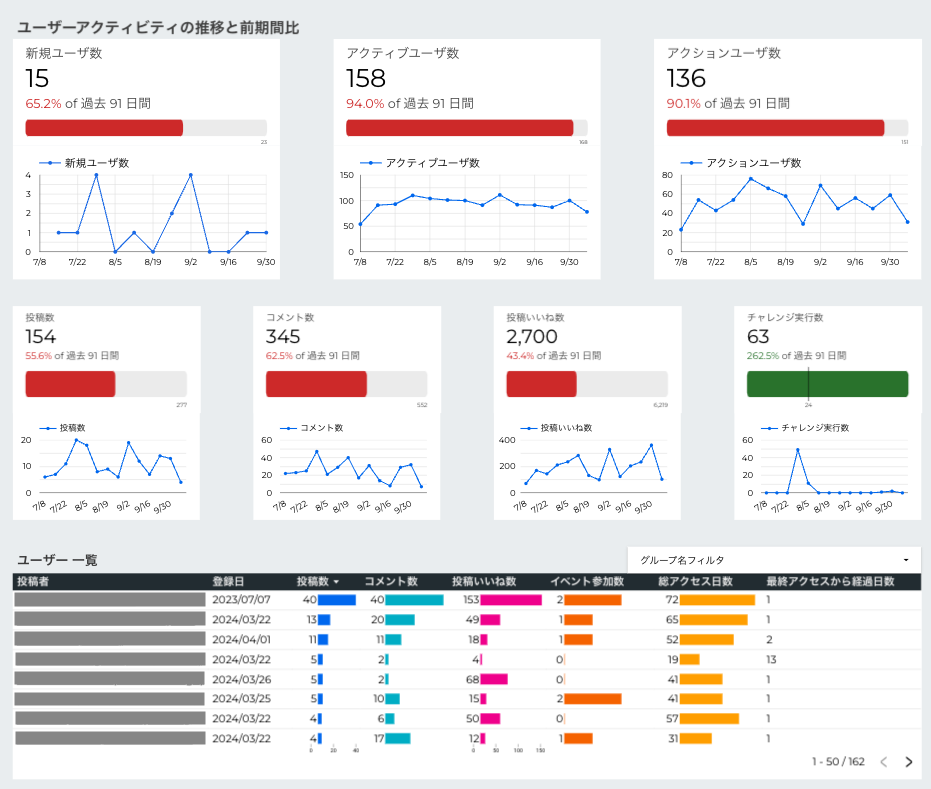
またユーザーの総滞在時間のような、部門ごとの指標であるNorth Star Metricを日々把握するため、BIツールで作成したダッシュボードにデータチームの考察を加えたレポートを週に一度の頻度で社内向けに周知しています。
導入後の効果
浮いたリソースで採用強化。「TROCCO®」の存在で、データ人材が安心して入社できるように

「TROCCO®」の導入によって、どのような成果を得ることができましたか。
前側:よいプロダクト作りに貢献できている実感があり、データチームの採用強化にも大きく貢献しました。「TROCCO®」を導入した当時は前任者1名だけでしたが、現在8名の規模まで成長できたのは、「TROCCO®」でデータ転送の業務を効率化でき、採用強化に時間を使えるようになったことが影響していると思います。そして私自身もそうでしたが、「TROCCO®」の利用が「データ基盤が整ったプロダクトである」と候補者に安心していただけることが影響していると思います。
私の採用面談の際に「『TROCCO®』をすでに導入済みで、データ基盤は安定している」と聞き、「構築済みのデータ基盤を活用し、もっと先のデータ活用ができる」と確信しました。例えるなら、社内のコミュニケーションにメールではなく、チャットツールを導入していると聞いた安心感のようなものですね。
データ活用の業務には、どのように貢献できているでしょうか。
前側:データ転送に時間を割く必要がなく、データ活用に集中できる体制を実現することができました。North Star Metricのダッシュボードによってユーザー行動のモニタリングができ、プロダクト開発に必要な土台もすでに整っています。
さらにデータ分析に強い優秀な方を採用できたことで、より実用性の高い分析画面を作成したり、より有効なレコメンドモデルを構築したりと、今後「攻め」のデータ活用の施策を積極的に展開していきたいと思います。
今後の展望
「データの民主化」で誰もが閲覧できるだけでなく、自らデータを処理できるように

今後のデータ活用の展望をお聞かせください。
前側:2025年以降はいよいよ本腰を入れて「データの民主化」に取り組んでいきます。これまではデータのリネージやテストの自動化などの施策を優先し、データエンジニアリング全般のレベル上げとデータ品質の向上に取り組んできました。ようやく準備が整ってきましたので、一気にビジネス向けダッシュボードを構築し、誰でも主要な指標をいつでも見られる状態を実現していきます。
さらに「データの民主化」の先では、ビジネスサイドから自分たちでも部門レベルでデータを転送したり、加工したり、リバースETLでSalesforceへデータを戻したいといった要望がでてくるでしょう。そのために自走してデータ活用するためのルール整備も同時並行で進めていきます。最終的な理想像としては「Communeの武器はデータだ」と社内外から評価されている状態です。
データ基盤の構築、運用に悩んでいる方へアドバイスをお願いします。
前側:データ組織の立ち上げフェーズにこそ「TROCCO®」はおすすめです。年々データエンジニアの採用は難しくなっている一方で、企業から求められるアナリティクスエンジニアリングのレベルも上がってきています。
だからこそデータエンジニアを採用してから動き出すのではなく、少しでも早く「TROCCO®」に頼り、あとから「TROCCO®」を扱える人を採用するという順番も良いと思います。
[service_banner]








