
課題・問題
スクラッチ開発されたデータ基盤の保守作業が属人化。新規のデータ転送設定が困難に

データアナリティクスグループのミッションについて教えてください。
太田 広司様(以下、敬称略):ベイシアビジネスセンターで勤務している本部の社員だけなく、各事業部の担当者や店舗で働く社員といったすべてのユーザーが、必要とするデータに適切にアクセスでき、データを活用することで価値あるインサイトを導き出せる環境を整えることが、私たちのミッションです。そのためにデータ同士の連携やデータ基盤(データレイク、データウェアハウス、BIツール等)の構築、保守に取り組んでいます。
貴社ではどのようなデータを扱っているのでしょうか。
太田:2020年12月のID-POS導入に合わせてデータをクラウドに蓄積し、分析できる環境が構築され、運用が始まりました。従来のPOSデータは、いつ、どの店舗で、どの商品がいくつ売れたのかといった基本的な販売データを指しますが、ID-POSデータは従来の販売データに加えてお客様一人ひとりの詳細データが紐づけられています。これによって、よりお客様のインサイトを深堀りしてデータを分析できるようになりました。 その他にも、ID-POSに紐づく組織のマスターデータや店舗ごとのマスターデータ、取引先のマスターデータ、CRMから得られるお客様のデータなどを扱っています。
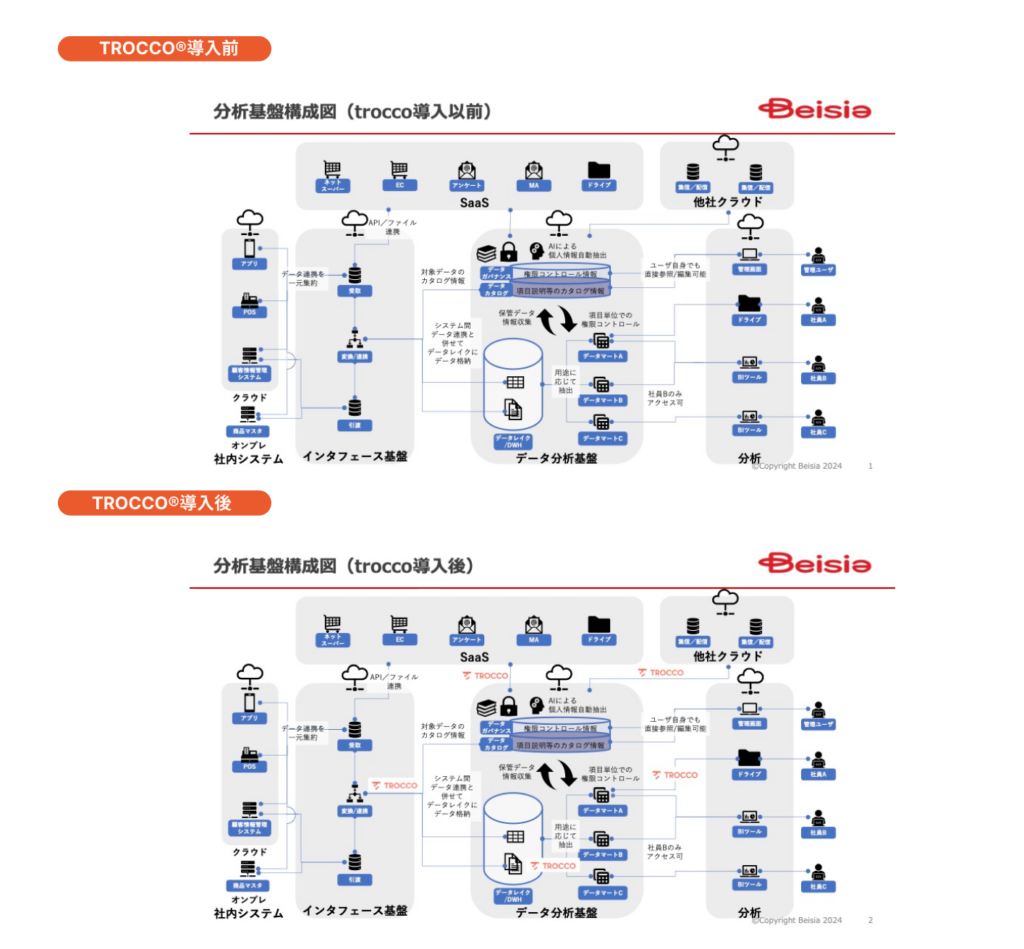
「TROCCO®」導入以前のデータ基盤について教えてください。
太田:当時より弊社では、AWSとGoogle Cloudを併用した、いわゆるハイブリッドクラウド環境にデータ基盤を構築していました。具体的には、AWS S3上のデータがGoogle Cloudを経由してGoogle Cloud StorageやGoogle BigQueryに蓄積され、エンドユーザーはBIツールのTableauを使用してデータにアクセスする、というデータフローです。
以前のデータパイプラインではどのような課題を抱えていましたか。
太田:初めてデータ基盤を構築することになった当時は、データ基盤がどれだけ活用されるか不透明であったため、なるべくコストをかけず、ミニマムスタートで構築することになりました。そのため、比較的コストを抑えてすぐに始められるクラウドのマネージドサービスを組み合わせつつ、内製によるスクラッチで基盤を開発しました。
データ量が限られていた当初は問題なく稼働していたものの、次第にデータ量が増え、データ基盤と連携するシステムも増えていく過程でさまざまな課題が生じてきたのです。
最も深刻な課題が、データ基盤の保守作業が属人化していたことです。外部パートナーの方にデータ基盤の保守をお願いしていたのですが、不具合や新たな要望に対してタイムリーな対応ができていないなど、運用監視の対応などが不十分な状況でした。もしお願いしていた外部パートナーの方が、病気等の理由でご協力いただくのが難しくなってしまうと、最悪の場合データ基盤を維持できなくなります。
小林 聡史様(以下、敬称略):データ基盤の保守だけでなく、新たなデータを転送するつなぎ込みの際に、その都度で開発の手間とコストがかかることも課題でした。私は入社してすぐ、以前のデータ基盤を引き継いだのですが、「このデータ基盤では、データを引っ張るだけでも大変だ」と太田と話したことを覚えています。
少しでも早くデータ基盤の全容を把握し、誰でも容易にメンテナンスができる状態にしなければならないと危機感を覚えていました。
なぜ「TROCCO®」を選んだのか
対応コネクタの豊富さ、使いやすさに加え、低コストな所や料金の分かりやすさを高く評価

サービスの比較検討は、どのように進めたのでしょうか。
太田:2022年8月頃より、ETLサービスを活用したデータ基盤を検討し始めました。当初は他社製のソリューションでいくつか比較検討していたのですが、それなりの規模の投資が必要になりそうとのことで導入には至らず、しばらくはペンディングされた状態だったのです。
その後、インターネット上のニュースやセミナー、展示会などで「TROCCO®」の存在を知り、再びETLサービスの導入を検討し始めました。
比較検討にあたって、どのような要素を重視していたのでしょうか。
太田:まずは機能です。当時は必要とするコネクタ数は少なかったものの、将来的なデータ基盤のスケールを考えると対応コネクタの豊富さは重要でした。比較検討時に必要としていた対応コネクタは、HTTP・HTTPSやAmazon S3、Google Cloud Storage、Google BigQueryなどです。コネクタの豊富さには、ローカル環境からのデータ転送など、かゆいところにも手が届くような便利さを感じました。
また、誰でもメンテナンスできるデータ基盤を構築するには、GUIの使いやすさ、運用保守性も重要です。操作画面の分かりやすさだけでなく、過去のログを簡単に検索できたり、何かエラーが発生した際に通知が飛んできたりと、私たちの作業負担を軽減する使い勝手の良さは大事なポイントでした。

「TROCCO®」の導入について、社内からはどのように承認を得たのでしょうか。
太田:今後もスクラッチで開発していく場合とETL/iPaaSツールを導入した場合のコスト比較はもちろん、生産性の向上や投資対効果なども苦労しながらも数字に落とし込み、社内に説明しました。
ただ「TROCCO®」の場合は、他社のソリューションと比べて導入と運用のコストが低く、料金プランがシンプルで分かりやすかったので、社内には説明しやすかったです。 他にも、スクラッチでデータ基盤の開発、保守を続けていくリスクや、ビジネス側からのデータ要求に対する対応のリードタイムなど、どのように改善されるかを説明し、無事に「TROCCO®」の導入が決定しました。
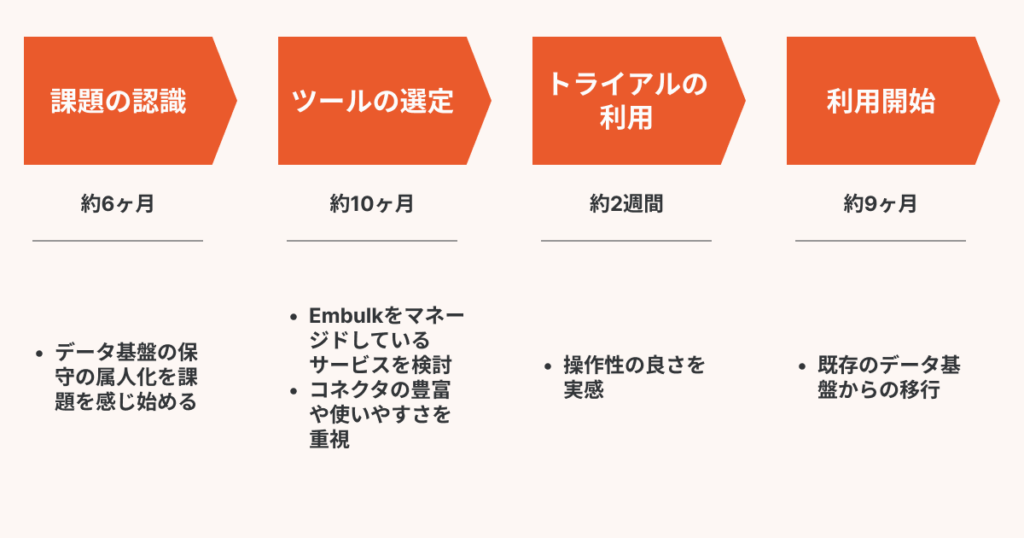
導入までのスケジュール・過程
既存のデータ基盤からスムーズに移行。シンプルなGUIにより、3ステップで転送設定が完了

「TROCCO®」の導入はどのように進行しましたか。
小林:2023年4月より、まずはトライアルとして導入を始め、PoCを経て2023年9月に有償プランを契約し、本格的に使い始めました。既存のデータ基盤の本番ワークロードの移行が完了したのは翌年の3月頃です。「TROCCO®」の基本的な操作は直感的で分かりやすく、既存のデータ基盤からのデータ移行はそれほど苦労することはありませんでした。
また私自身が過去にEmbulkを触ったことがあったことで、Emblukで動いている「TROCCO®︎」をスムーズに導入できたと思います。
弊社のCSからはどのようなサポートがありましたか。
小林:Slackでチャンネルを立てていただき、分からないことや相談があればチャットにてご相談しています。タイムリーかつ的確にレスポンスいただいたおかげで、データ基盤の移行もそれほど苦労するところはありませんでした。
「TROCCO®」で特に評価いただいている機能を教えてください。
小林: 「TROCCO®︎」で一番使っている機能は、データ転送設定です。比較検討時に必要 としていた対応コネクタに加え、導入後にもコネクタの多さのお陰でTROCCOの活躍シーンは増えています。 データ基盤のインポート、エクスポートのコネクタだけでなく、S3バケット間でシステム間のファイル連携が必要な場合に TROCCOのEmbulkではなくAWS SDKを使った転送が使われている場面があります。
太田:導入以前に比較検討していた他社製のETLやiPaaSツールのGUIは、各パーツを一つひとつつなぎ合わせるようにデータフローを構築する操作だったため、正直なところエンジニアとしては非常に面倒くさいなと感じていました。GUIであれば何でも操作しやすい訳でなく、パーツの機能を覚えたり、操作のクセを覚えたりと、意外と学習コストが高くつきます。
一方で「TROCCO®」の場合、データの転送元と転送先を選択するだけで、マッピングと転送設定が完了します。この3ステップで転送設定が完了できるGUIは高評価ですね。
導入後の効果
1週間はかかっていたデータ転送設定がわずか2日に!属人化の課題は無事に解決

「TROCCO®」の導入によって、どのような成果を得ることができましたか。
太田:一番大きな変化は、データ転送1本の設定およびテストにおよそ1週間はかかっていたところ、約2日で完了するようになったことです。以前のデータ基盤では、チームをまたいだり、外部パートナーさんに協力いただいたりと、コミュニケーションのリードタイムがありました。さらにスムーズに連携できれば問題ないものの、うまく機能が連携していないといったトラブルがあれば、さらに2倍の時間がかかってしまうこともありました。現在は私たちが所属するデータアナリティクスグループでデータ転送設定は完結するようになり、作業工数も大幅に削減されています。
「TROCCO®」でデータ転送の工数が削減されたことで、データ活用に対してよりプロアクティブに動けるようになりました。以前はデータ転送が手間だったために積極的な提案ができませんでしたが、今では「データがあるのなら、まずはGoogle BigQueryに入れてしまおう」と会議の場で気軽に伝えられています。
また、私たちだけでなく、データの提供を受ける側にも大きなメリットが生まれました。以前のデータ基盤でデータを転送する際は、「Shift_JISのCSVファイル」「UTF-8のCSVファイル」といった厳格に決められたフォーマットに揃え、決められたストレージに格納する必要がありました。
しかし現在では、システムアカウントを持たない事業部側の担当者でもGoogle Driveに出力したり、Google スプレッドシートで提供したりと、ユーザーが分析しやすい形でデータ提供ができるようになりました。
データ基盤の保守の工数には、どのような変化がありましたか。
小林:厳密には計算できていませんが、感覚的には半分以下の工数に削減できています。「TROCCO®」を導入して以降、トラブルはあまり起きていません。もし、今後トラブルが起きたとしても、自分たちだけで解決できるようになったため、工数削減に大きく貢献しています。
太田:データ基盤の属人化という課題は解決することができました。特定のデータエンジニアでなければ理解できないデータ基盤から、シンプルで分かりやすいGUIのおかげで、我々データアナリティクスグループのみならず、依頼元のシステム担当者側でも運用できるようになったのは、生産性向上の観点からも大きな成果です。
今後の展望
経営層からもデータ活用に期待の声が。浮いたリソースでさらなる課題解決に取り組みたい

今回の取り組みを受けて、今後のデータ活用の展望をお聞かせください。
太田:データ基盤に対して経営陣からは「データ転送のリードタイムを短くするだけでなく、その先のデータ活用をどんどん推進してほしい」との期待の声をいただきました。
実際には、ID-POSをはじめとした販売データをBIツールで可視化し、分析できる環境を整えることができたものの、その先のビジネスに活かすフェーズまではまだまだ課題が残っています。現場が使いたいデータがまだ十分揃っていなかったり、複数部署を跨いだデータ連携にはユーザー対応のリードタイムがあったりと、これまで以上に私たちからの積極的なアプローチが必要な課題ばかりです。「TROCCO®」の導入で浮いたリソースを事業部側に残っている課題の解決のためにも活用していきたいと考えています。
これからデータ基盤の構築に取り組む予定の企業へ、アドバイスをいただけますか?
太田:「TROCCO®」は非常にシンプルで簡単なツールです。エンジニアはもちろん、非エンジニアでもデータ転送を簡単に設定できるツールなので、とりあえず試しに使ってみるだけでも、その良さが分かると思っています。今回の弊社の取り組みのように、データ基盤の保守がとても楽になりますし、生産性の向上も期待できます。 データ活用で悩んでいることがあれば、まずはprimeNumberの担当者の方への相談や、Freeプランを試してみてもいいのではないでしょうか。
[service_banner]








