
背景と課題:なぜメタデータ管理が必要だったのか?
内藤 純様(以下、敬称略):AIを使って生徒一人ひとりに最適な学習カリキュラムをレコメンドするという弊社のプロダクトにおいては、学習ログやメタデータは非常に重要な、コアのような存在です。弊社でメタデータをプロダクトやビジネスに活かすために、どのようなことに取り組んできたのかを、事例をご紹介しながらお話しさせていただきます。

まず私が入社した直後のデータ分析基盤をご紹介します。本番データベースがAmazon AWSにあり、そこからGoogle BigQueryに連携され、DWHやダッシュボードからCSVをダウンロードして分析する、といった流れでした。
ここでの課題は、データ分析がその場限りになってしまい、データ分析基盤が整備されていなかったことです。BigQueryも導入はされてはいましたが、定常的に利用している人は数名程度で、データの転送料金のコストがかなりかかっている状態でした。また、データウェアハウスも数名の分析者が使う便利なテーブル程度で、ほとんどの社員は存在を知らない状況だったのです。さらにデータのドメイン知識が一部の社員に属人化してしまっているのも大きな課題でした。
私は前職でデータ分析基盤の重要性をよく理解していたので、こうした実態に対してデータ基盤をもっと整えていかないとサービスがグロースしないと感じていました。アドホックな分析や書き捨てのクエリを続けても、ナレッジは蓄積していきません。
また、属人化したままにしておくと、組織がスケールするときのボトルネックになるため、標準化する仕組みや組織を作らないと、かなり苦しくなるだろうとも考えました。
そこで入社1年くらい経った段階で、自分が手をあげてこれらの課題解決に向き合うことになりました。
イケてるデータドリブンカンパニーになるためにやったこと

内藤:課題を解決するために、いきなりソリューションを導入した訳ではなく、そもそもすでに構築されていたデータ基盤があったので、「なんでBigQueryあるのに使わないの?」と職種問わず、一人ひとりヒアリングしていきました。
その結果、以下の7つに集約されることがわかってきました。
- やりたい分析はあるけど必要なデータがどこにあるかわからない
- データの定義がよくわからない
- 品質担保されているのかよくわからない
- テーブルをJOINするのが面倒
- SQLの書き方がそもそもわからない
- 他人が書いた長いSQLを読み解くのが難しい
- セキュリティ的に使って大丈夫なのか確証が持てない
特に4番以降はテクニカルな話ではあるものの、ほとんどの社員が共通して挙げていた1〜3に関しては、メタデータ管理の仕組みでほぼ解決できそうだと考えました。
まるっと解決できそうなソリューションの検討
内藤:BigQueryには「テーブルスキーマ」があり、この枠にさまざまな情報を書き込もうと考えていました。しかし弊社の場合、データマートを「TROCCO®」のジョブで構築しているため、洗い替えのたびに一生懸命書き込んだ内容が毎日消えてしまうのです。
そこで新たなソリューションを模索、検討することになり、以下の要件でイケてるメタデータ管理のツールを探すことになりました。
- メタデータをググるように全文検索できる
- 気軽に誰でも書き込める
- PostgreSQL+BQに対応している
- 環境構築+運用コストがほぼゼロ
以上の要件ツールを探していたところ、TROCCO®で「データカタログ」という新しい機能がリリースされると聞きました。まさに我々が欲しかった機能で、クローズドβ版から登録して活用することになりました。
少人数で一気呵成に初期入力。社内への布教活動や「データカタログ」へのフィードバック
内藤:メタデータ整備はソリューションを導入するだけでは意味がなく、誰かが入力しないと始まりません。そこで、私含めの2名という少人数で一気呵成にメタデータを初期入力しました。テーブル情報に詳しい人の協力を得て入力をお願いする方法もありましたが、その場合スピードが落ちてしまうため、少人数でまずはスタートしました。
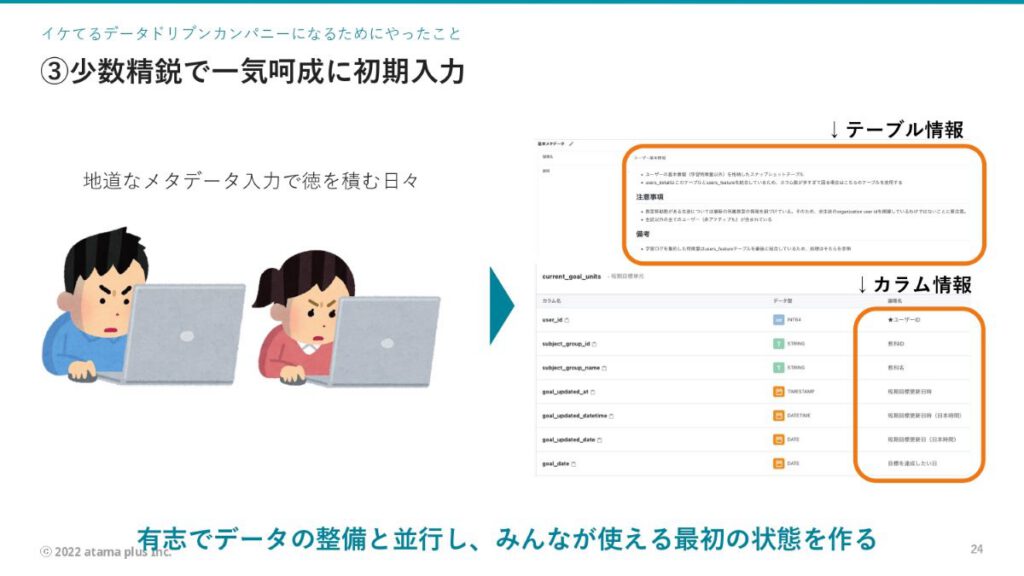
さらにメタデータを入力するだけでは社内で使ってもらえないので、メタデータの布教活動も同時並行で実施しています。非技術者の方にも分かるように「メタデータとは何か」「何で管理しないといけないのか」「メタデータを管理することは、何の得があるのか」を説明しています。
この布教活動は繰り返すことが大事だと考えており、以下の3点をずっと伝え続けました。
- メタデータはデータ活用する上でとても役立つ!
- メタデータを一つ入れるだけでも組織への貢献!
- 同じ分析を繰り返すのはやめよう!
さらに「メタデータの入力は確かに面倒。だけど、1つ入力するだけでも、組織への貢献であり、徳を積んでるようなもの」と、Slack上でも伝えていました。
今回の取り組みで最もよかったと感じている点は、「データカタログ」がクローズドβ版だったこともあり、活用しながら細かい修正希望のフィードバックをさせていただいたことです。「メタデータを太字や赤字でリッチに表現したい」「マークダウンに対応してください」といった要望に対し、10日ほどで対応していただけました。こうしたご対応を受け、弊社では本導入することになったのです。
結果、組織としてどう変化したか?
内藤:「TROCCO®」を活用したメタデータの整備によって、どのような成果が得られたのかご紹介します。定性的な成果として、メタデータに救われた社員が増えた印象です。ビジネス側の非技術者や、SQLは書けるけど入社したばかりで目的のデータの場所が分からない社員も、誰かに聞かず、自立的に目的のデータを探し出せるようになりました。
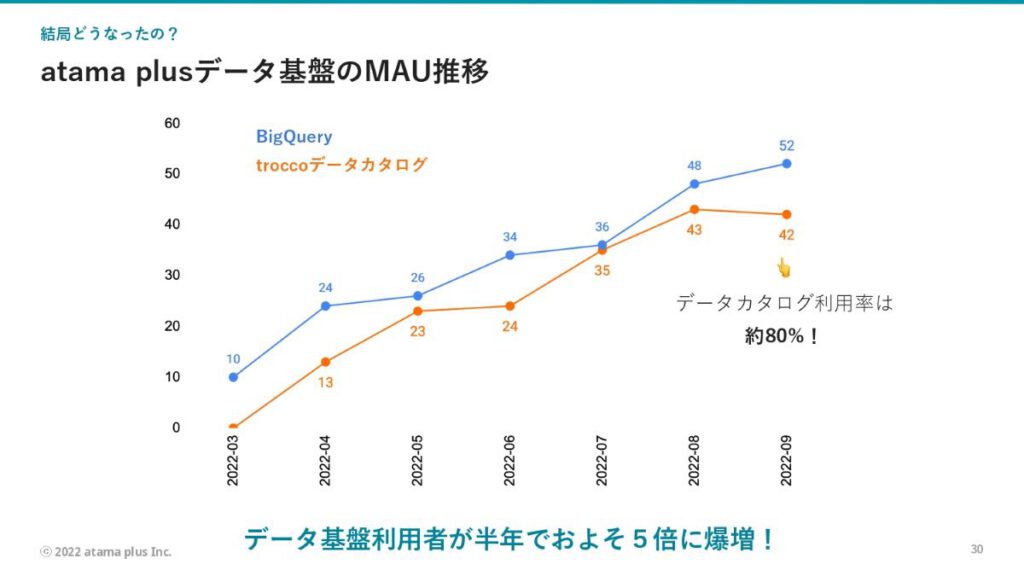
定量的な成果として、以前は社内に10人ほどしかいなかった、BigQueryを活用していた社員が、半年後の現在は5倍以上の52人となりました。それに合わせて、データカタログの利用率も伸びており、BigQueryを活用している社員の約80%がデータカタログを併用しているという結果になりました。この半年で、データ基盤の利用者が爆増したと言える成果でしょう。
利用者側からみた変化。教育現場での定量データの活用や効果検証、サービス全体の可視化も
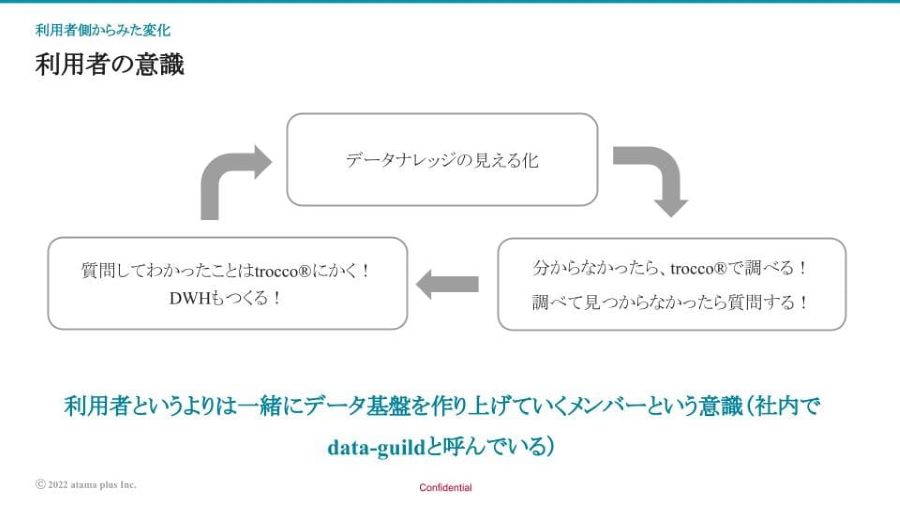
辻本 直人様:私からは、利用者側から見たメタデータ管理の変化についてお話しさせていただきます。そもそもスタートアップである弊社では、利用者と提供者と分かれた意識があまりありません。みんなが利用者であり、提供者でもあり、一緒にデータ基盤を作り上げていくメンバー(社内では「data-guild」と呼称)という意識です。

当初はデータに詳しい人がまずデータナレッジを見える化し、蓄積していきました。そこから、データに詳しくないメンバーが「TROCCO®」のデータカタログで調べ、それでも見つからなかったら質問するという流れでした。そして質問して分かったことは、データカタログ上に書いたり、データウェアハウスも作ってさらにナレッジが蓄積されていくという、好循環が作られているかなと思います。
これによって、データ活用の成果もしっかり感じられています。たとえば、教育現場での定量データの活用です。実際に塾の教室に行き、生徒の横に座って定性的なヒアリングをすることがあるのですが、その際にその生徒の学習ログがすぐに調べられるようになり、そのヒアリング内容をデータ上でも確かめることできるようになりました。これはつまり、定性と定量がうまく融合した分析や検証が進んでいるということです。
また、施策の効果検証にも変化がありました。教育というドメインの特性上、施策を実施したことでどのような学習効果があったのか、定量的に分析するためにはさまざまなデータを組み合わせる必要があり、非常に難しくなっています。
そのため、以前は一部の限られた社員にしか効果検証ができなかったのですが、今回の取り組みでデータによる効果検証のハードルが低くなり、より多くの社員が施策の検証ができるようになりました。
加えて、サービス全体像を可視化できるようになったことも大きな変化です。データ基盤がなくても、時間さえかければ可視化できる部分もありますが、何よりもより幅広い社員が素早くサービス全体像の可視化ができるようになったことに、最も価値があると考えています。
メタデータは地味だが役に立つ

内藤:メタデータは本当に地味だと思います。しかし、間違いなくビジネスの役に立つものでもあるのです。このメタデータを誰でもすぐに理解できる仕組みこそが、データの活用促進において極めて重要だと思います。
しかし、このメタデータの重要性は、99%の人には伝わりません。だからこそ、なぜ活用すべきなのかという文脈を、非技術者の方でもわかるように丁寧に説明すべきです。そして、メタデータをみんなで育てる意識を醸成するためにも、その重要性と「1つでも入力することが組織への貢献であること」を誰かが繰り返し主張し続けることが大事なのではないでしょうか。
最終的には、データ分析の手間がなくなっているような世界観を目指しています。社員のみんなが本来やりたいことはデータ分析ではなく、仮説の検証や施策を考えることです。本当にやりたいこと、やるべきことに時間を割けるような仕組みを目指していきたいですね。








