
第22回では、「5社のデータエンジニアが振り返る」と題して、データエンジニアリングやデータ分析基盤に関する「良かったこと・問題だったこと・来年トライしたいこと」などを5名の方々にLT形式で発表していただきました。
今回の勉強会では、「Data orchestration 特集」と題して、データオーケストレーションについて3名の方から説明していただきます。データオーケストレーションとは、データのETLと分析、可視化のプロセス全体を自動化し、調整することです。その具体的な方法や利用されるツールについて、講演とLT形式で詳しく説明していただきます。
当日の発表内容はこちら
基調講演「ワークフローオーケストレーション入門」
長江 五月 氏
株式会社CyberAgent AI事業本部 Dynalyst データサイエンティストマネージャー
普段の業務では、MLOpsやMLモデリング、広告データ分析を行う。個人ブログにて、AWSでML基盤を構築する記事を掲載中。
はじめに、ワークフローオーケストレーションの概要についてお話ししていただきました。
ワークフローオーケストレーションとは

長江氏:「ワークフローオーケストレーションとは、一言で表すと、ワークフローをオーケストレーションすることです。
ワークフローとは、2つ以上のステップを含む一連の流れを指します。例としては、Slack通知やETL処理、ML学習などがあります。
オーケストレーションとは、一般的には複数システムやアプリケーション、サービスの管理・調整を指します。管理する対象がコンテナである場合は、コンテナオーケストレーションと呼ばれており、Kubernatesなどが有名です。
これら2つをまとめたワークフローオーケストレーションとは、ワークフロー実行のためのインフラ・システム・トリガーなどの調整を行うことを指します。」
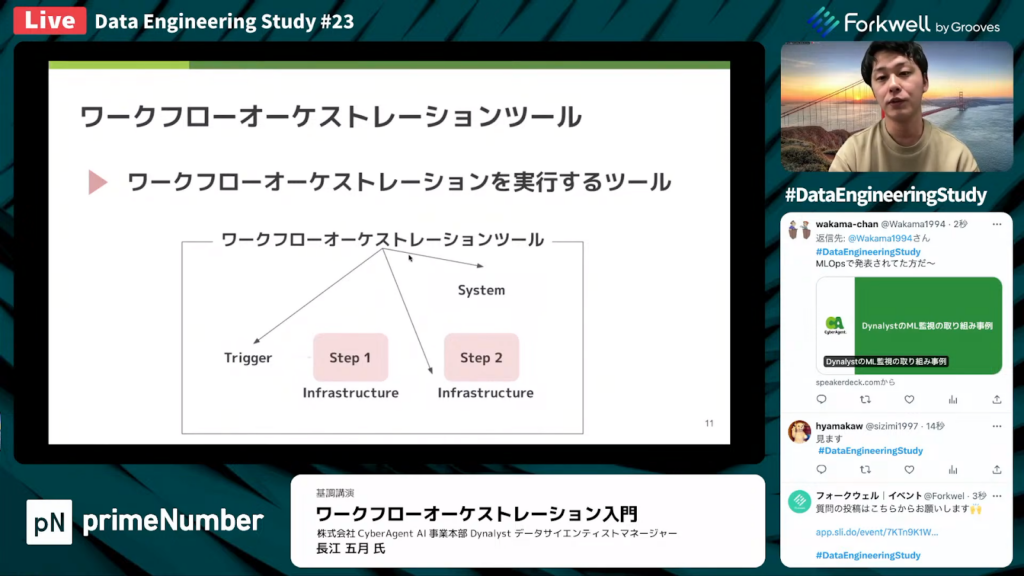
長江氏:「ワークフローオーケストレーションツールとは、ワークフローオーケストレーションを実行するツールです。各ステップが実行される場所や、外部システムとの連携、ステップの実行などを担います。」
ワークフローオーケストレーションはトレンドになりつつある
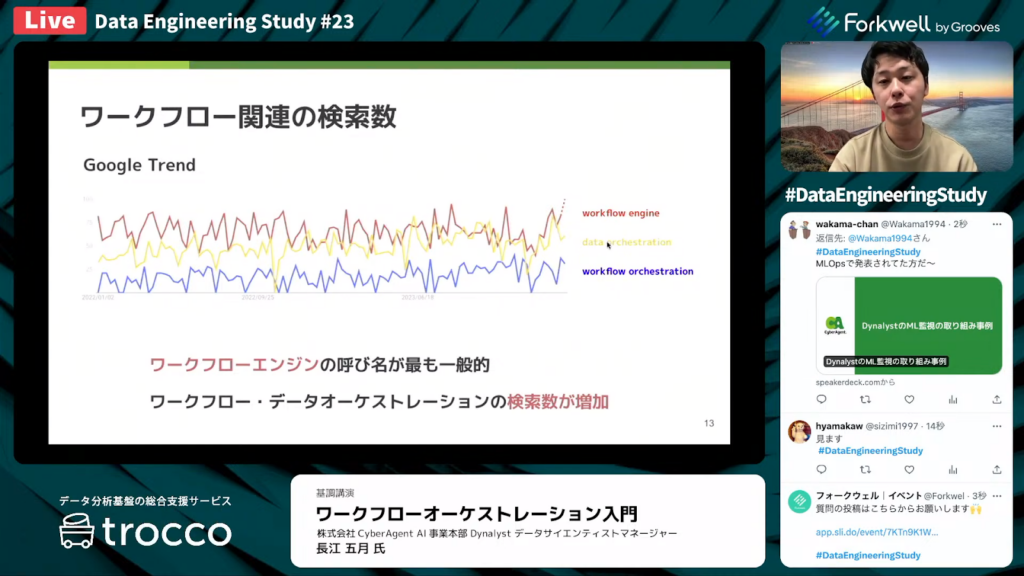
長江氏:「こちらは、ワークフロー関連の検索数(Google Trend)の変化をプロットした図です。
赤色が『ワークフローエンジン』のトレンドです。他の言葉と比べて検索数が多いため、最も一般的な呼び名であることがここから推測できると思います。
しかし最近になって、黄色の『データオーケストレーション』と青色の『ワークフローオーケストレーション』の検索数が上昇していることがわかります。そのため、現在の世の中では、データオーケストレーションやワークフローオーケストレーションがトレンドになっているといえるでしょう。」
ワークフローオーケストレーションツールがトレンドになりつつある背景
長江氏:「ここからは、ワークフローオーケストレーションツールの歴史について着目し、なぜ今トレンドが来ているのかをお話ししていきます。
ワークフローオーケストレーションツールは、大きく分けて5つの歴史に分かれています。」

長江氏:「こちらは、Prefect社が書いた『ワークフローオーケストレーションの歴史』の中の時代区分です。
CRON時代から始まり、現代のモダンデータスタック時代へと移り変わっています。各時代について着目していきます。」
CRON時代
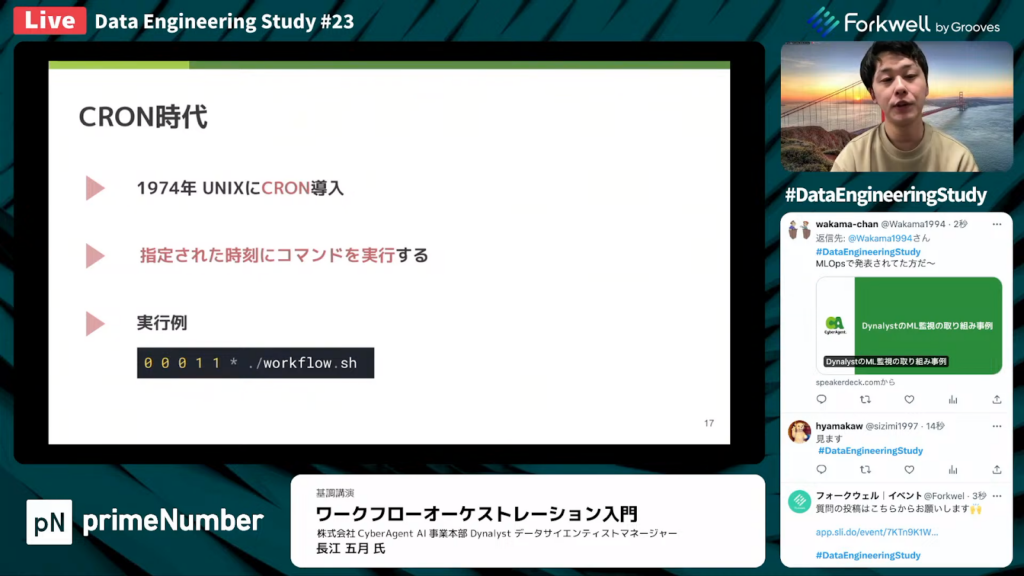
長江氏:「1974年、UNIXにCRONが導入されました。CRONは、指定された時刻にコマンドを実行する役割を果たします。実行例はスライドに記載されている通りで、こちらはworkflow.Shのシェルスクリプトを定期的に実行するコマンドです。
ワークフローオーケストレーションの歴史は、CRONから始まりました。」
リレーショナルデータベース時代
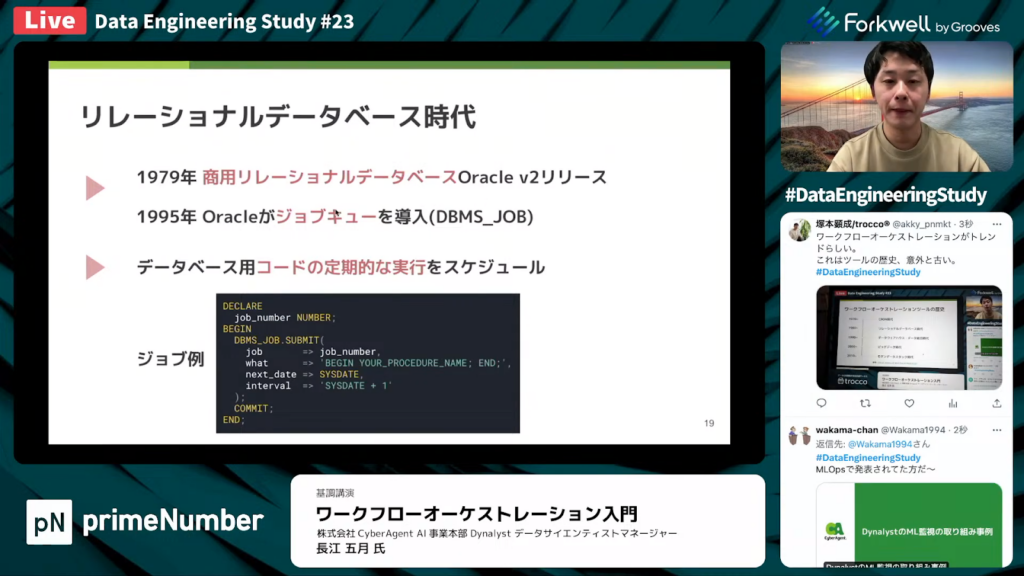
長江氏:「1980年以降、リレーショナルデータベースの時代がやってきます。
1979年に商用ショナルデータベースであるOracle v2がリリースされました。その後、1995年にOracleがジョブキューを導入します。これはDBMS_JOBジョブと呼ばれていました。
DBMS_JOBの機能としては、データベース用コードの定期的な実行のスケジュールが可能です。ジョブの実行例は、スライドに記載されている通りです。」
データウェアハウス・データ統合時代
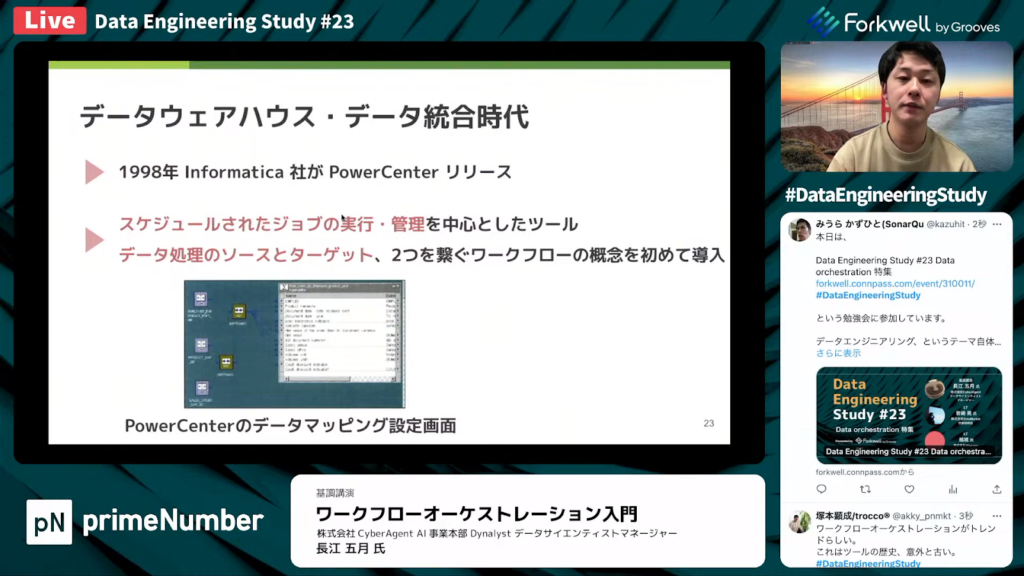
長江氏:「その後、データウェアハウス・データ統合の時代がやってきます。
この時代以前では、複数のデータソースごとにデータを処理していました。たとえば、データソースがアプリケーションの場合はスクリプトをCRONで実行し、データベースの場合はDBMS_JOBを使ってジョブを実行していました。また、Excelファイルは人手で頑張って作業するといったように、集計方法は個々のデータソースごとに異なっていました。
しかしその後、複数のデータソースを1つにまとめてデータウェアハウスに入れる動きが流行しました。よく知られているETL処理を、複数のデータソースから抽出して行う形です。そのため、複数のデータソースから1つのデータウェアハウスに処理をまとめることに特化した機能が、ここから登場していきます。
1998年、Informatica社がPowerCenterと呼ばれるツールをリリースしました。PowerCenterは、スケジュールされたジョブの実行や管理を中心としたツールです。そして、データ処理のソースとターゲットをつなぐワークフローの概念を初めて導入したツールでもあります。」
ビッグデータ時代
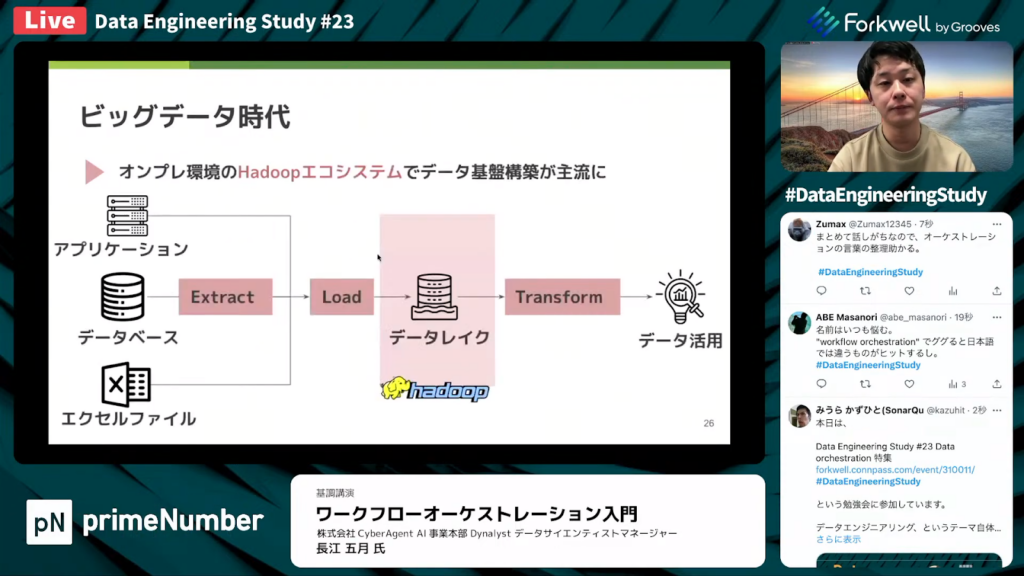
長江氏:「2000年以降、ビッグデータの時代がやってきます。
2006年にGoogleがHadoopをOSS化しました。その後2011年に、データレイクが提唱され、流行します。
ビッグデータの時代では、オンプレ環境のHadoopエコシステムでのデータ基盤構築が主流になります。複数のデータソースからデータを抽出し、分散処理が可能になったことで、大量のデータを捌けるようになりました。そのため、一気にデータレイクとしてデータを格納し、データ活用の目的に応じて加工して使うデータ基盤が主流になったのです。」
ワークフローツール第1世代

長江氏:「このあたりから、Hadoopエコシステムを活用するためのワークフローオーケストレーションツールが登場します。そして、ワークフローツール第1世代と呼ばれるツールが台頭しました。
有名なツールですと、YahooのOozieやSpotifyのLuigi、LinkedlnのAzkabanなどが挙げられます。前提として、これらのツールは、Hadoopジョブをうまく管理するモチベーションがあります。
同じ時代に出てきたAirflowは、ワークフローをプログラムで作成・スケジュール・監視するためのプラットフォームと書かれています。ただ時代背景的には、Hadoopジョブの管理の課題感の中で生まれています。
モダンデータスタック時代

長江氏:「2010年以降から、現在のモンデータスタック時代がやってきます。
2011年にBigQueryがGAされて、2013年にRedshiftがGAされます。また、Sparkを事業化したDatabrics社が設立されます。2014年には、SnowflakeがGAされ、Kafkaを事業化したConfluent社が設立します。
このように、オンプレから安価で高速なクラウドへ環境が変わり、ストリームデータ処理技術が発達していきます。従来存在しなかった、新しいデータ基盤の課題を解決するツールに対して、人々は『モダンデータスタック』の言葉を当てるようになりました。
Data Stackとはそもそもどのような意味かというと、データ基盤を構築する製品群を指します。たとえば、データベースやBIツール、ETL製品、ワークフローツールなどです。
Modern Data Stackは、前提として、特定のアーキテクチャや技術、ソリューションを指す言葉ではありません。あくまで、従来のデータスタックの課題を解決するための技術トレンドの総称です。」
ワークフローツール第2世代の登場

長江氏:「その後、データ基盤のアーキテクチャ変化が起こりました。その中の1つに、ワークフローツールの役割の変化があり、この時期からワークフローツールの第2世代が登場していきます。
2016年にDigdagがOSS化され、StepFunctionがGAしました。2017年にPrefectがリリースされ、同時にArgoがOSS化されます。2018年にはDagsterがリリースされ、2019年にAirflowのマネージドサービスである、Cloud ComposerがGAされました。」
主要ワークフローツールの変遷まとめ

長江氏:「ここまでの主要ワークフローツールの編成をまとめます。
まず、CRONから始まります。その後RDMS_JOBと呼ばれるリレーショナルデータベースの機能が加わり、PowerCenterと呼ばれるデータウェアハウスに特化したツールがやってきます。
Hadoopジョブを管理する目的で、Airflowなどのツールが登場してきました。最近では、モダンデータスタック時代となり、新しいワークフローツールが登場しています。」
現代のワークフローオーケストレーションの役割
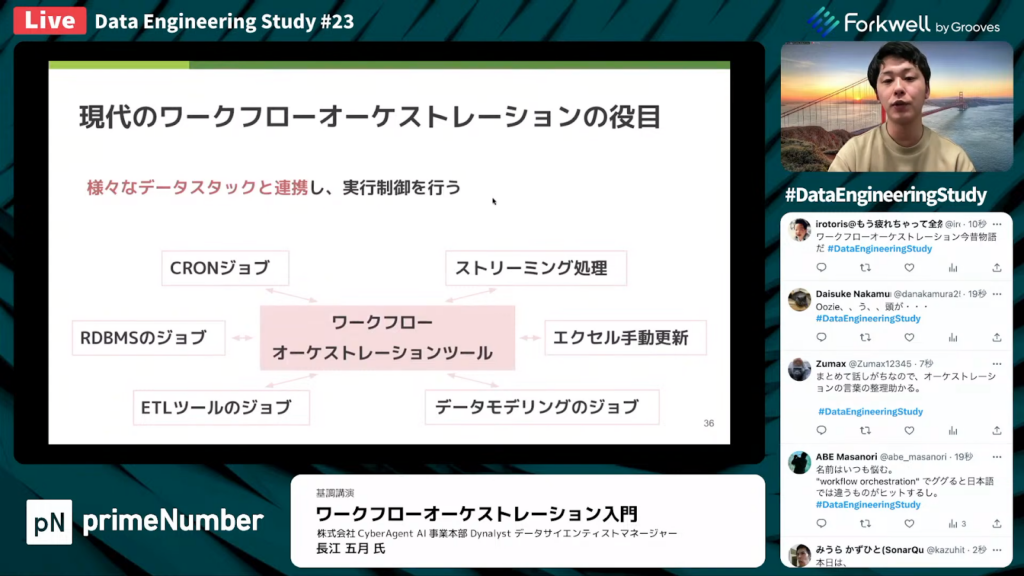
長江氏:「新たなデータスタックが登場してきていますが、完全な世代交代は行われず、さまざまな技術を組み合わせたデータ基盤が作られているのが現状です。
CRONジョブは1970年代に既に登場していましたが、現在でもまだ使える便利な機能です。また、RDBMSのジョブも最近では非常に便利な機能が備わっているため、RDBMSのジョブを使っているプロダクトも多いと思います。データモデリングのdbtのジョブも非常に便利であるため、ここだけで完結するケースもあるかと思います。
そのため、現代の状況として、データスタックごとにデータエンジニアが管理する必要があります。またそうなると、どうしても運用負荷が増加していきます。
そこで、現代のワークフローオーケストレーションの役目とは、新旧含めたさまざまなデータスタックと連携し、実行制御を行うことです。」
ワークフローオーケストレーションツールの機能

長江氏:「ワークフローオーケストレーションツールに備わっている機能として、タスクの実行順序の制御やリトライなどを保証する『実行制御』の機能や、ワークフローの実行状態やログを追跡できる『監視』の機能があります。
また、並列処理や柔軟な計算リソースの拡張を行える『スケーラビリティ』が備わっています。そして非常に重要な点として、データベースやETLツールなどと容易に連携できる『外部ツール連携』の機能を持っています。」
ここからは、ワークフローオーケストレーションツールを導入することで、我々はどのようなメリットが得られるのかを説明していただきました。(以降、ワークフローオーケストレーションツールをワークフローツールと略称します。)
データパイプラインの課題
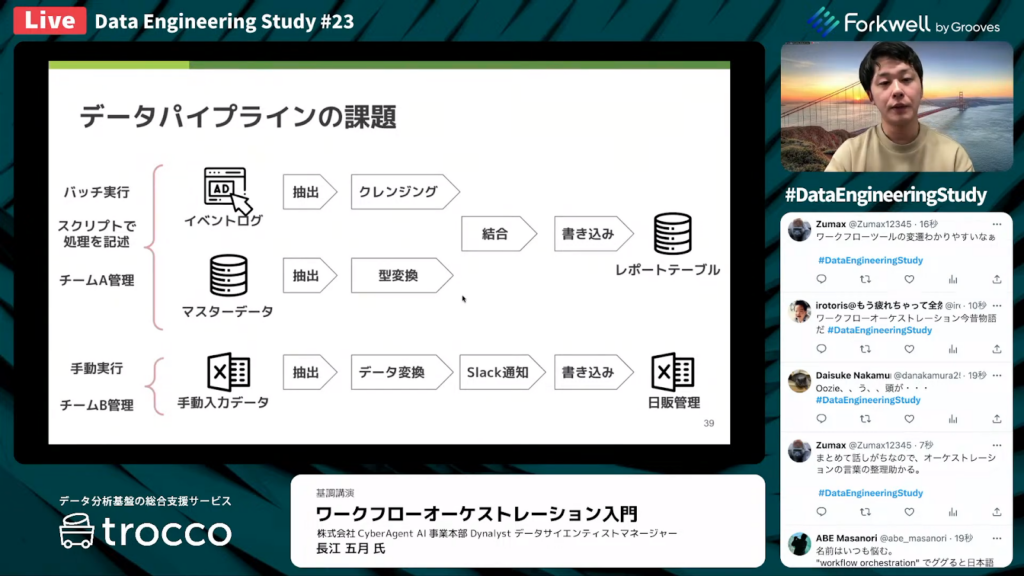
長江氏:「よくあるデータパイプラインの例として、イベントログとマスターデータを抽出して、それぞれを突合してレポートのテーブルを作成するケースがあります。
一方で、Excelの手動入力データをビジネスの方が管理しているケースもあります。この場合、『そのデータを変換して、変換が終わったらSlackに通知を送り、日販管理のExcelシートに書き込む』といったデータパイプラインが考えられると思います。
よくある体制として、『エンジニア側が管理してるデータに関しては、スクリプトで処理を記述してバッチを実行している。一方Excel側の方は手動で実行していて、エンジニアが全く関与していない。』といったケースがあります。
こういったデータパイプラインにワークフローツールを導入した場合、どのように変わるのかをまとめました。」

長江氏:「まずエラー対応に関しては、手動リトライを自動リトライに変更できます。また実行順序制御では、スクリプトで自前で実装する必要がありましたが、ワークフローツール側で行えるようになります。そのため、エンジニアがタスク定義に集中できる状態になります。
また非常に大きな点として、ツールごとの実行ログの確認をワークフローツール1箇所にまとめられるというメリットがあります。データのサイロ化と呼ばれる、管理しているデータが組織内に散在していて簡単にアクセスができない状況も、ワークフローツールで解決できると言われております。」
機械学習パイプラインの課題
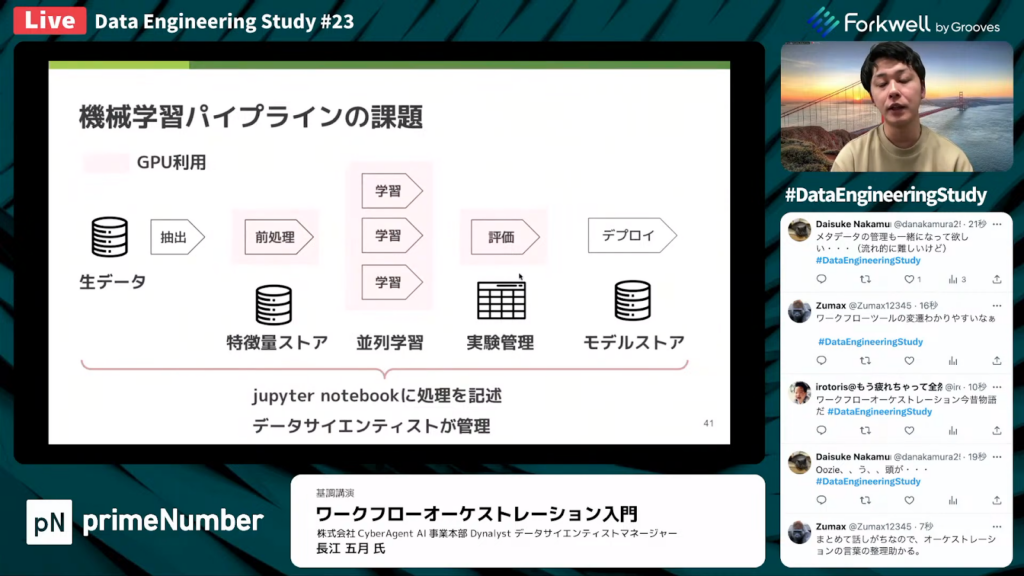
長江氏:「機械学習パイプラインによくある課題として、GPUをデータの前処理や学習部分などの特定の処理のみに利用したいケースがあります。モデルを複数管理してる会社の場合、並列でモデルを学習させたいケースもあります。
比較的アンチパターンではありますが、パイプラインの管理をjupyter notebookに処理を記述して、データサイエンティストのみで管理しているケースもあると思います。」

長江氏:「こういった状況にワークフローツールを導入することで、まずパイプライン管理をjupyter notebookからスクリプトに強制的に変更できます。運用者に関しては、データサイエンティストしか機械学習に触れていない状況から、チーム横断で運用できるようになります。
複数モデルの管理に関しては、jupyter notebookでやるよりスクリプトでやった方が簡単であるため、比較的容易になるはずです。」
ワークフローとDAGの関係
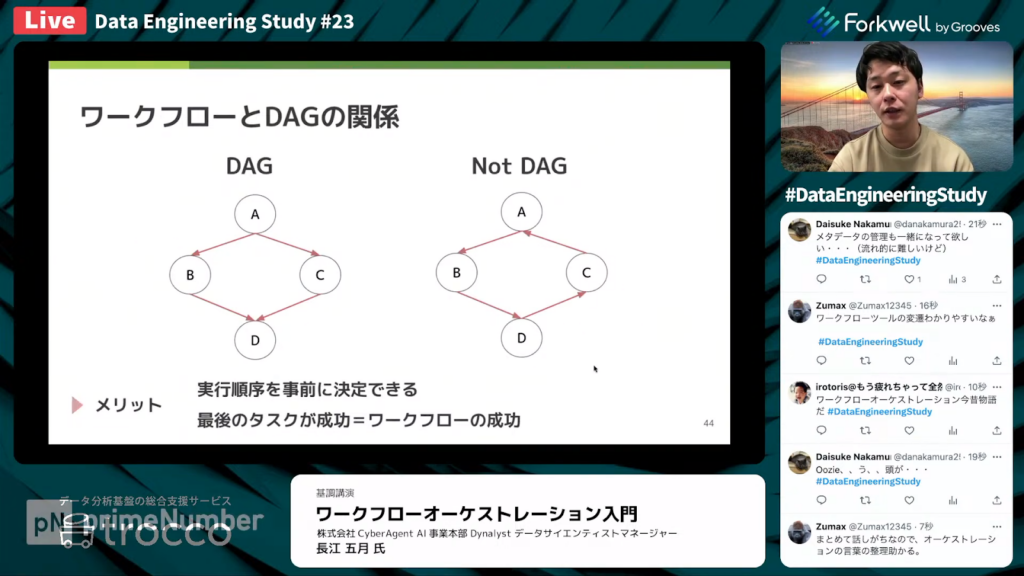
長江氏:「ここからは、ワークフローと結びつけられて考えられることが多い、DAGについて紹介します。
DAGとは、ワークフローをタスクと依存関係で表現したものです。タスクが正常実行されると再実行されない点と、タスクの依存関係は一方向のみである点が特徴です。
図において、左側のケースはDAGになっていますが、右側のケースはDAGになっていません。Aのタスクが再実行される可能性があり、依存方向が一方向ではない状態になっています。
DAGを使用すると、実行順序を事前に決定できるため、ワークフローの依存関係をコードで表現できるメリットがあります。また、最後のタスクが成功したらワークフローが成功したと言えるため、タスクの状態管理がしやすいです。」
なぜDAGがワークフローツールに普及したか

長江氏:「DAGがワークフローツールに普及した背景として、初期のワークフローツールがHadoopジョブをマークアップ言語で記述していたことが大きく影響しています。
HadoopジョブのMapReduceのタスクをYAMLやXMLなどのマークアップ言語で記述していました。これらの言語はループや相互依存を表現できないため、結果的に全てのワークフローがDAGとして表現されるようになりました。
ただ、DAGにする必要がないという説もあります。実際、Prefect社が『You Probably Don’t Need a DAG』といった記事を出しており、このトレンドは変わっていくのかなと思います。」
つづいて、具体的に6つのワークフローツールの特徴について、比較していただきました。
ワークフローツール一覧
長江氏:「『awesome-workflow-engines』というGitHubのレポジトリに100個のワークフローツールがまとまっているため、参考にするとよいでしょう。
今日はその100個の中から、代表的な6個のワークフローツールについて紹介します。Airflow、Digdag、Argo、Prefect、dagster、AWS Step Functionsです。
まず利用形態として、OSS、SaaS、クラウドマネージドの3つのサービスが存在します。また、ワークフローを実装する際、YAMLやPythonで書くのか、もしくはGUIで操作できるのかといった違いもあります。
学習コストに関しても、ワークフローツールごとに大きく異なります。お手軽に試せるツールもあれば、機能は豊富だが学習コストが大変であるツールもあります。
今回は、これらのバリエーションに富んでいる代表的な6つのツールを紹介します。」
GitHub Star数の推移
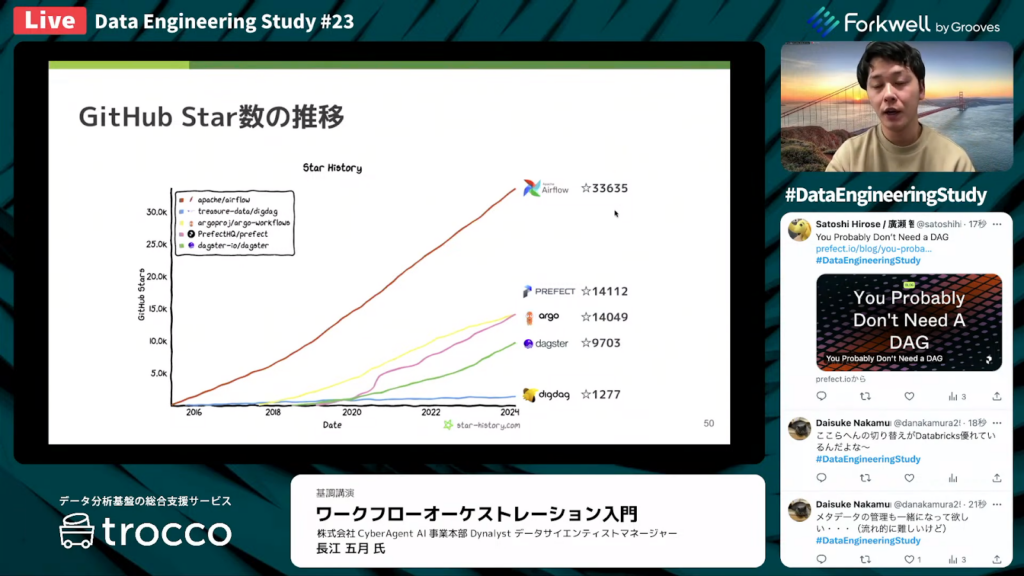
長江氏:「GitHub Star数は、今のところ知名度の高いAirflowがダントツです。ついでPrefectですが、最近になってArgoとdagsterの勢いが増しています。次にDigdagが位置付けている状況です。」
Airflowとは
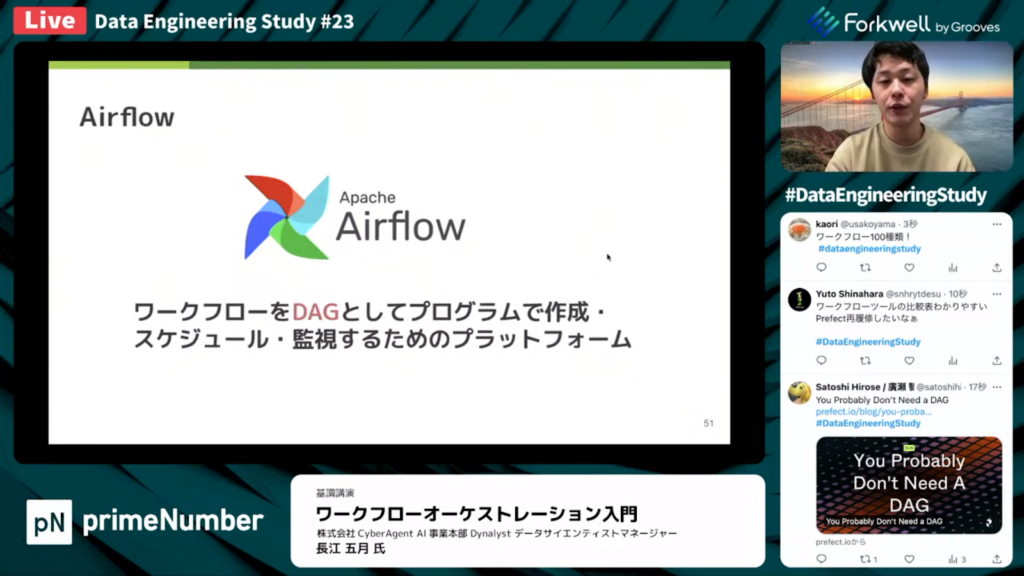
長江氏:「Airflowは、ワークフローをDAGとして、プログラムで作成・スケジュール・監視するためのプラットフォームです。
有名なツールのため、SaaSやマネージドサービスとして提供されています。実際にAirflowを使う場合は、自前でAirflowを運用するより、マネージドサービスを使うケースが多いと思います。」
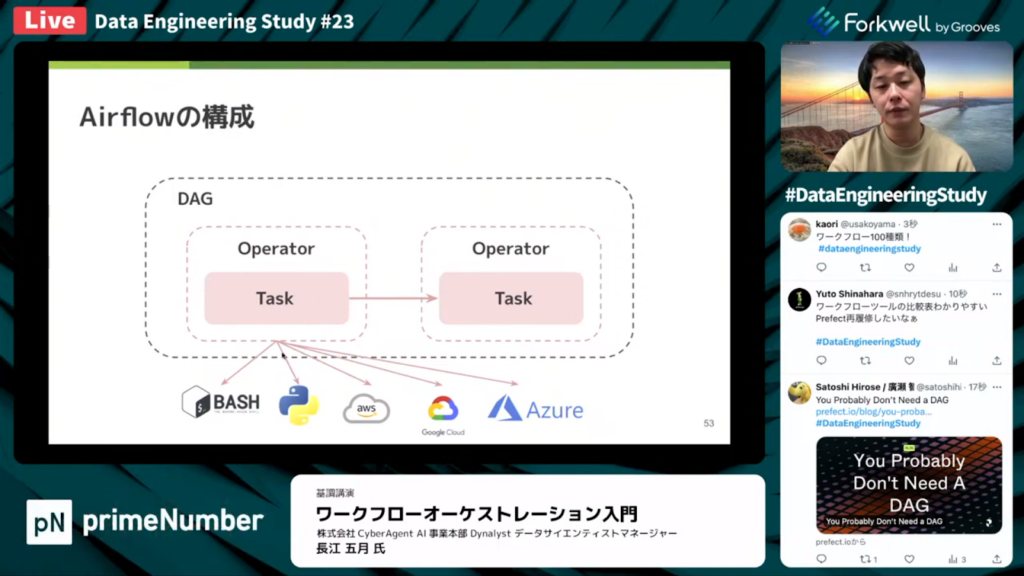
長江氏:「DAGの構成について、まずタスクと呼ばれる処理に関する具体的な記述があります。これをどこで実行するかという部分で、外部システム連携のOperatorでくくります。そしてAirflowの構成では、このオペレーター同士の依存関係をDAGで表現します。」
Airflowの実装例
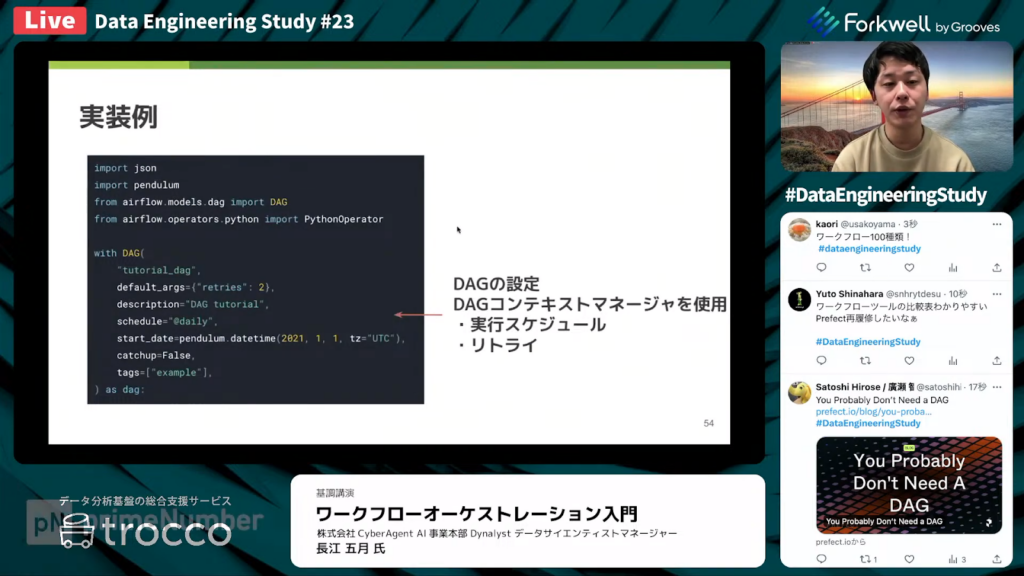
長江氏:「まずDAGのコンテクストマネージャーを使用して、実行スケジュールやリトライの設定をしていきます。次に、Python Operatorで実行する関数を作成します。Pythonライクな形でタスクを定義できます。
Airflowの場合、XCOMと呼ばれる手段によって、タスク間のデータの受け渡しを行います。Operatorのインスタンスをそれぞれ作成して、最後にAirflow独自の記述方法でDAGの依存関係を作成していきます。」
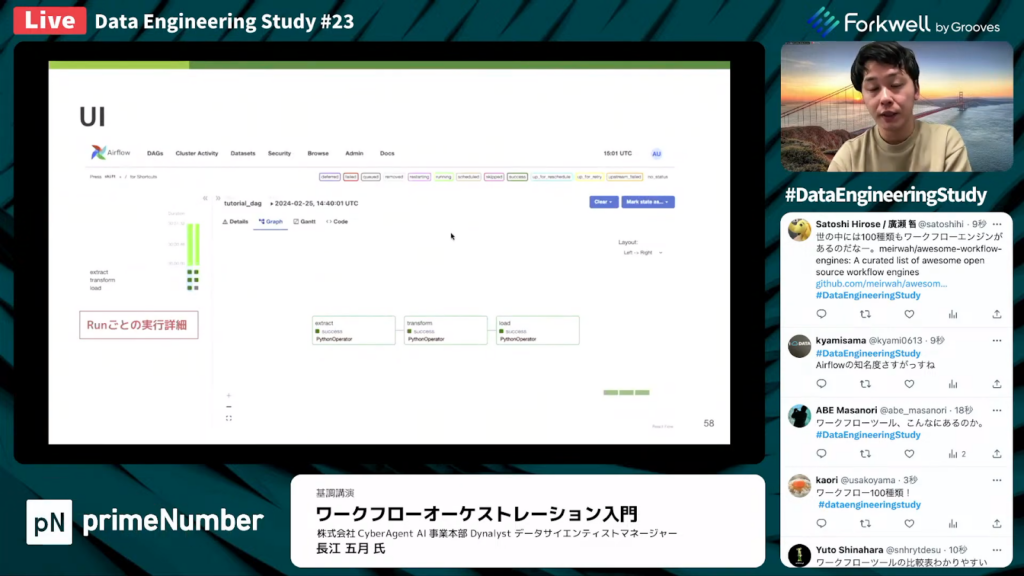
長江氏:「UIに関して、各ジョブごとに今までの実行履歴が見られます。実行の詳細画面はこのようになっており、タスク間の依存関係が可視化されています。実行時のアプリケーションログもUI上で確認できます。」
Digdagとは
長江氏:「Digdagは複雑なタスクパイプラインの構築や実行、スケジュール、監視に役立つシンプルなツールです。Digdagの1番の特徴は、シンプルな点です。
Digdagにはワークフローの実行内容を設定する、Operator Registoryと呼ばれる要素が備わっています。シェルスクリプトやPythonファイル、BigQuery、Redshiftなどのツールとの連携が可能です。
また、ワークフローの実行場所を設定する、Command Executorと呼ばれる要素があります。現在はECSやdocker、kubernetesがサポートされています。
これらの設定を行ったTask Executorと呼ばれる概念が、タスクの実行を制御します。」

長江氏:「前提として、なぜDigdagがYAMLを導入してるのかについてお伝えします。
まずYAMLの利点としては、シンプルで理解しやすい点とプログラムでパース・生成できる点、シンタックスハイライトが可能な点があります。そのため、エンジニアに非常に馴染みのある言語かと思います。
ただ、外部ファイルのincludeができない点や変数の埋め込みができない点、プログラムが内部で書けない点が欠点です。
これらのYAMLの利点を残しつつ、欠点を補填したものがDigファイルです。」
Digdagの実装例
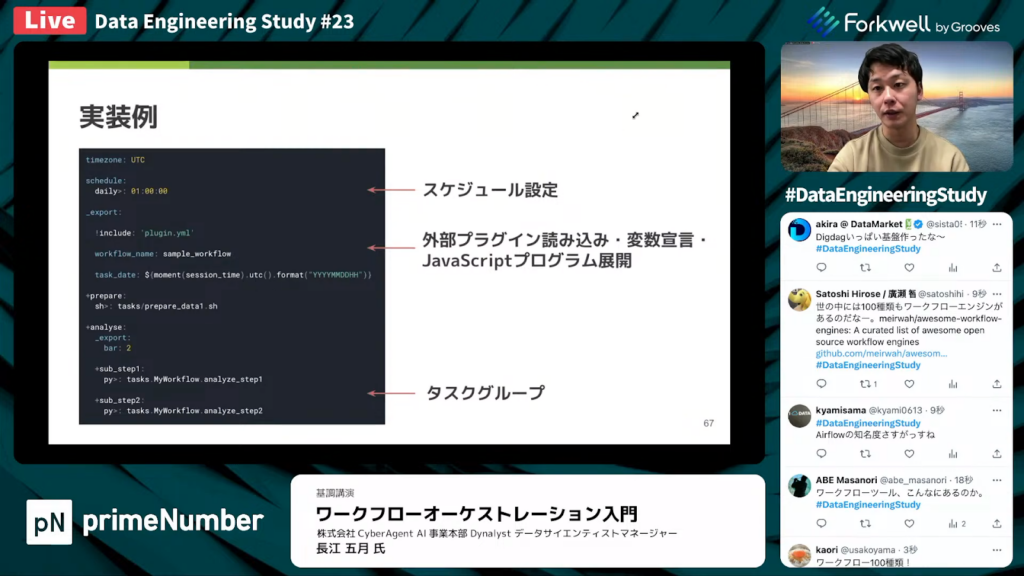
長江氏:「こちらが実際にDigファイルでタスクを定義する時の例です。
スケジュールの設定が可能で、クーロンでの表記もできます。外部プラグインをインクルードでき、変数も設定できます。Javascriptのプログラム展開がサポートされているため、現在状況の取得ができます。
Digdagにはタスクの中にサブタスクが存在し、タスクグループと呼ばれる概念があります。そのため、並列処理を実行したり依存関係を記述したりできます。」
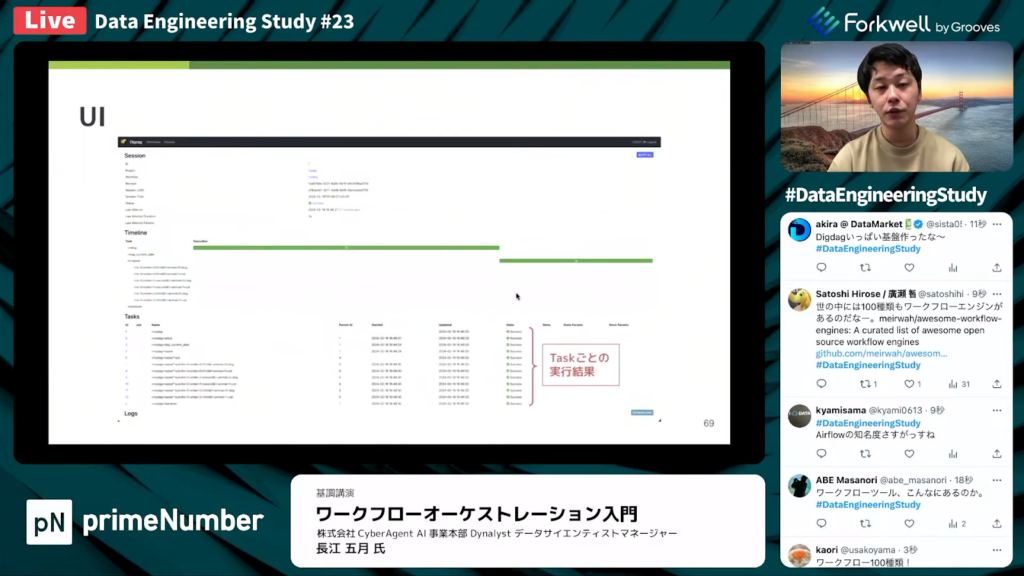
長江氏:「こちらがUIの画面です。今までのワークフロー実行の履歴を見られます。Digファイルのバージョンに対応したRevisionと呼ばれる概念があり、バージョン管理ができます。実行のステータスの追跡も可能です。」
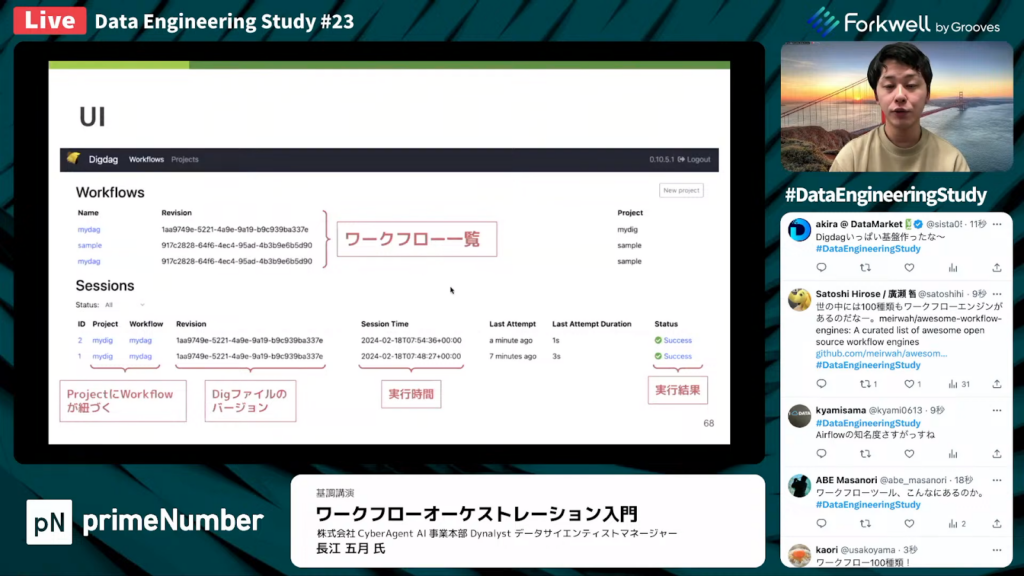
長江氏:「こちらのスライドが実行の詳細画面です。各タスクの実行時間のプログレスバーが見られます。各タスクの実行結果も詳細に追跡できます。
このように、DigdagのUIは非常にシンプルでとっつきやすいです。」
Argoとは
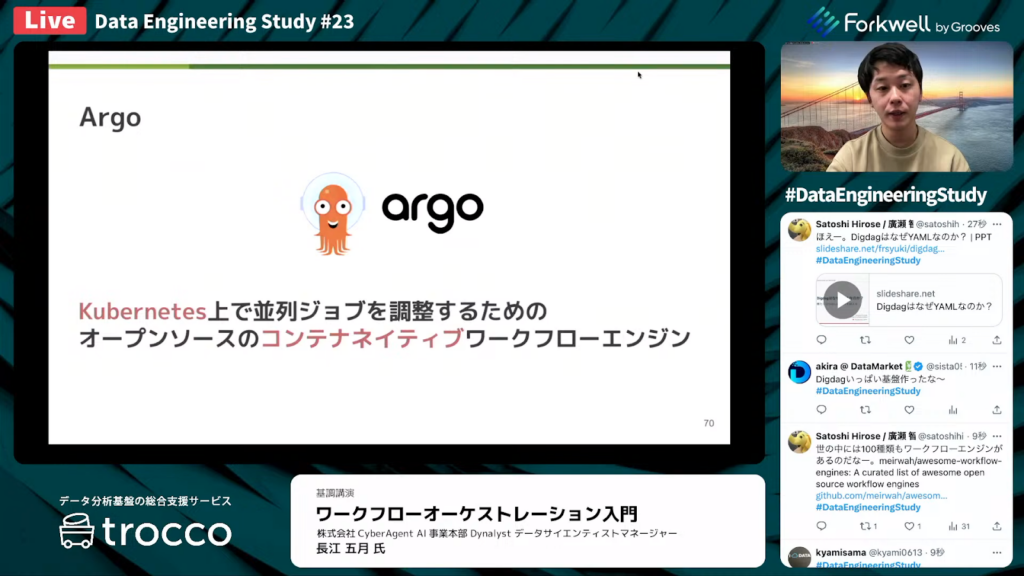
長江氏:「ArgoはKubernates上で並列ジョブを調整するためのオープンソースのコンテナネイティブワークフローエンジンです。Argoでは『Kubernates』がキーワードです。
Argoの要素としては、Templateを組み合わせたWorkflowと呼ばれる概念があります。Workflowは文字通り、実行ワークフローを定義したものです。Templateとは、タスクの内容を定義するもので、6種類のタイプを組み合わせます。」

長江氏:「Templateには大きく分けて、DefinitionsとInvocatorsと呼ばれる要素があります。
Definitionsはタスクの内容を定義します。たとえばContainerと呼ばれるテンプレートは、実行コンテナの設定を行えます。
一方Invocatorsには、Stepsと呼ばれる、タスクの一連の実行ステップを作成するテンプレートや、Dagsと呼ばれるタスクの依存関係を作成するテンプレートがあります。」
Argoの実装例
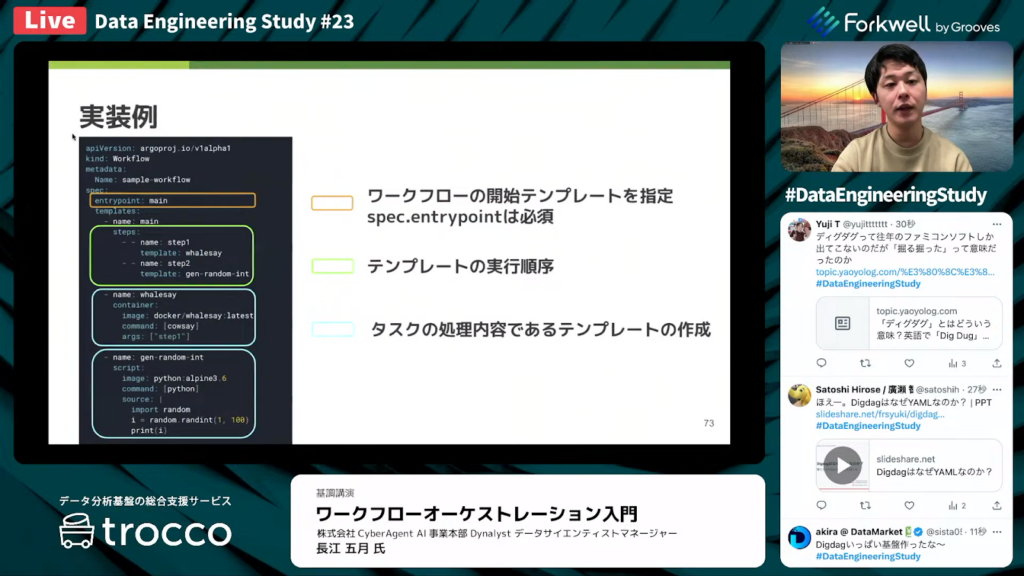
長江氏:「こちらがArgoでのワークフローの実装例です。
まず、タスクの実行内容を定義するテンプレートを作成します。真ん中の枠内はContainerのテンプレートで、実行するdockerのイメージやコマンドを設定して、1個のタスクを作っています。
下の枠内はScriptと呼ばれるテンプレートで、実行するスクリプトをCRDの中で書いて、タスクを定義しています。
この2つのタスク定義をStepsと呼ばれるテンプレートを使って依存関係を定義する処理の流れになっています。Kubernatesを普段から使っている人には馴染みのある書き方かなと思います。」
長江氏:「UIはすっきりした画面になっています。」
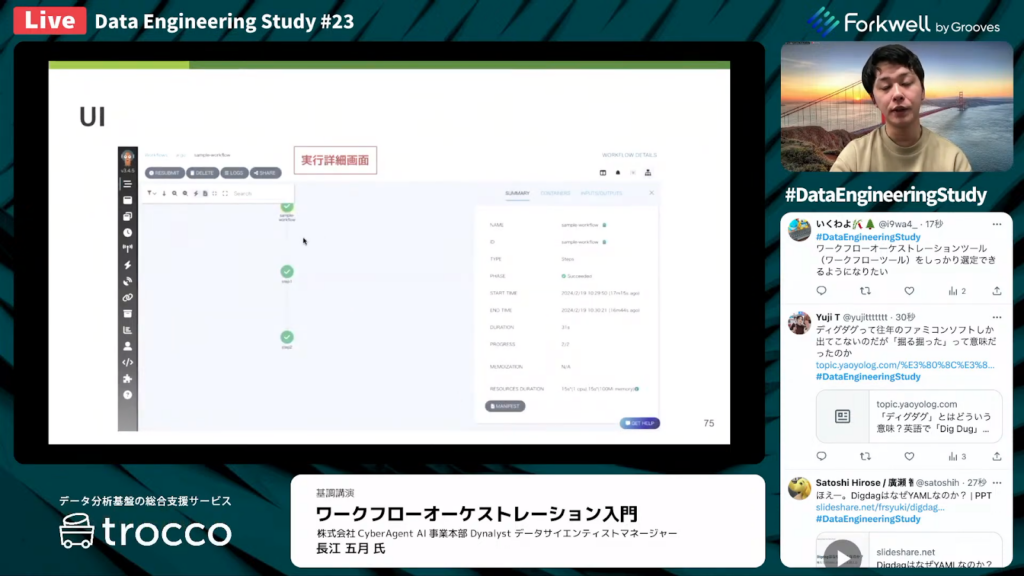
長江氏:「こちらが実行の詳細画面です。各タスクが視覚的に表されていて、タスクごとの詳細も簡単に閲覧できます。
Prefectとは

長江氏:「Prefectは、ワークフローの構築、観測、優先順位付けを行うオーケストレーション・オブザーバビリティプラットフォームと呼ばれています。『Pythonコードをインタラクティブなワークフローに変換する最も簡単な方法』とPrefectは称しています。
ポイントは、ワークフローをPythonコードで書ける最も簡単な方法である点です。」
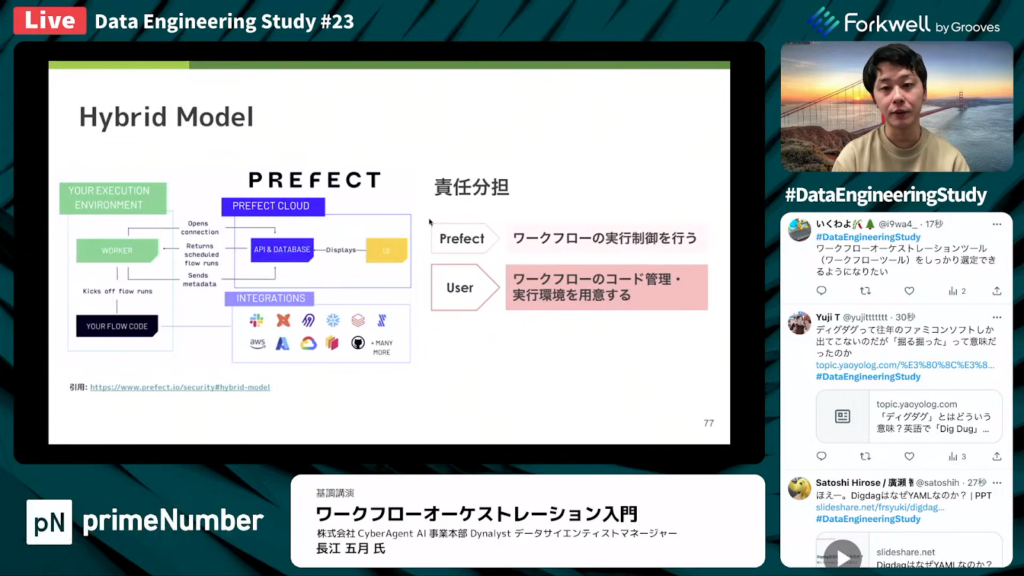
長江氏:「Prefectには、AWSの責任分担モデルと似ている、Hybrid Modelと呼ばれる概念があります。
Prefect側はワークフローの実行制御を行い、User側は、ワークフローのコード管理・実行環境を用意します。Prefectはあくまで実行制御を行うだけで、ユーザーのコードやインフラ環境を管理するわけではありません。」
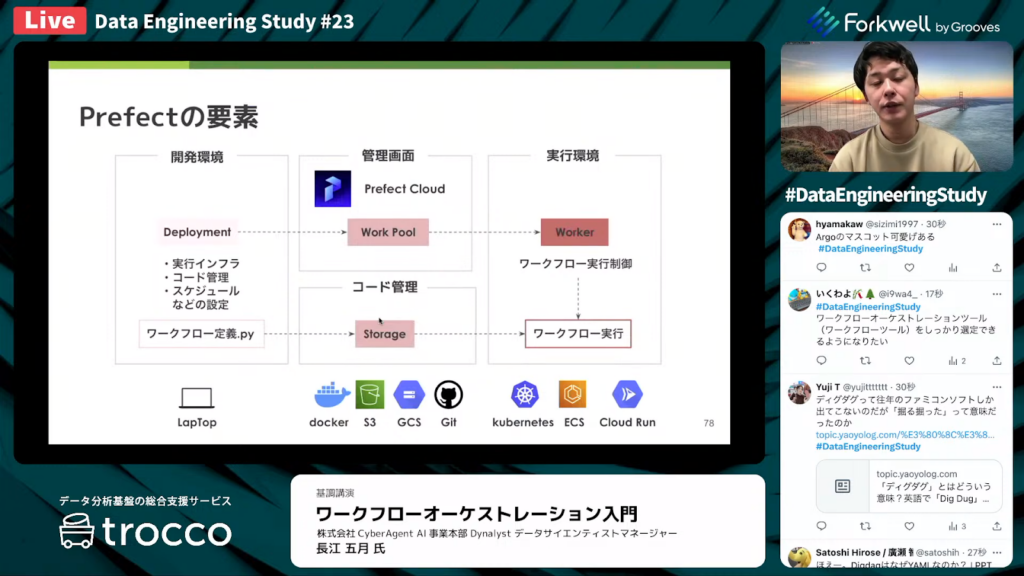
長江氏:「開発環境の段階では、ワークフロー定義をPythonファイルで書きます。ワークフローの実行設定が定義されたDeploymentを作成します。実行するインフラ環境やコードの管理場所、スケジュールなどが定義されています。
その後、DeploymentをPrefect Cloudと呼ばれる課金型サービスの管理画面に登録します。この時、ワークフロー定義が書かれたPythonスクリプトがStorageにされます。Storageはユーザーが選択でき、dockerやS3、GCS、GitHubレポジトリなどの設定が可能です。
実行環境には、KubernatesやECS、Cloud Runなどを選択でき、自分のインフラ環境にWorkerを設置します。WorkerがPrefect Cloudからワークフローをポーリングして、ワークフローの実行制御を行う流れになっています。
Prefectは比較的覚えることが多いため、学習コストが高いといえます。」
Prefectの実装例①
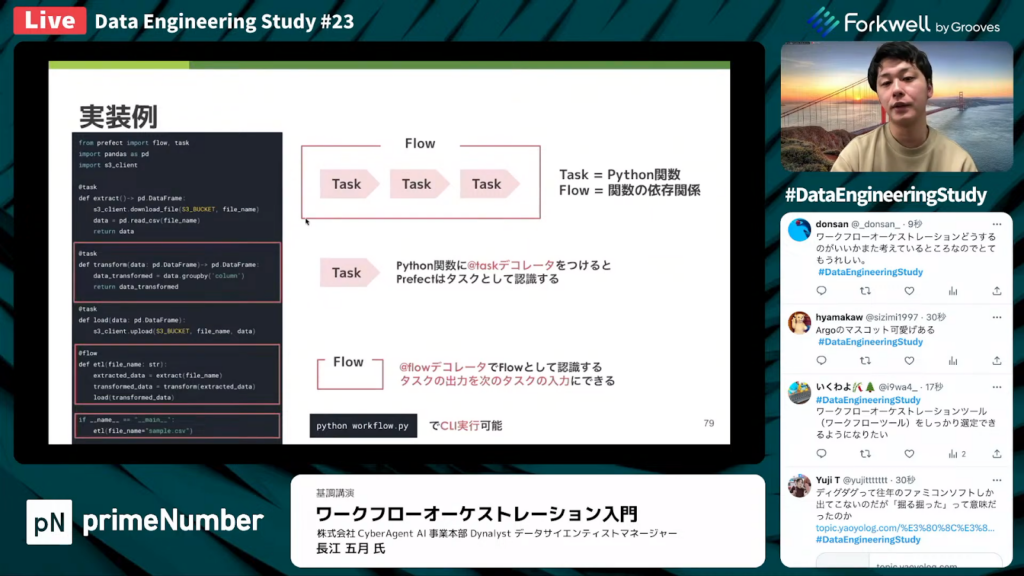
長江氏:「Prefectでは、Taskと呼ばれるPythonの関数をつなぎ合わせて、Flowと呼ばれるTaskの依存関係を定義する必要があります。
上の枠内に書かれているのが、Taskの実装例です。Python関数に『@task』デコレータをつけることで、Prefectはタスクとして認識してくれます。
Task実装例の下の枠内に書かれているのが、Flowの実装例です。Task関数をつなぎ合わせており、ほとんどPythonの関数です。『@flow』デコレータをつけることで、PrefectがFlowとして認識してくれます。
特徴は、通常のPythonのように、タスクの出力を次のタスクにそのまま入力できる点です。実行画面下の枠内のスクリプトを、『python workflow.py』でローカルのCLIで実行してデバッグできます。」
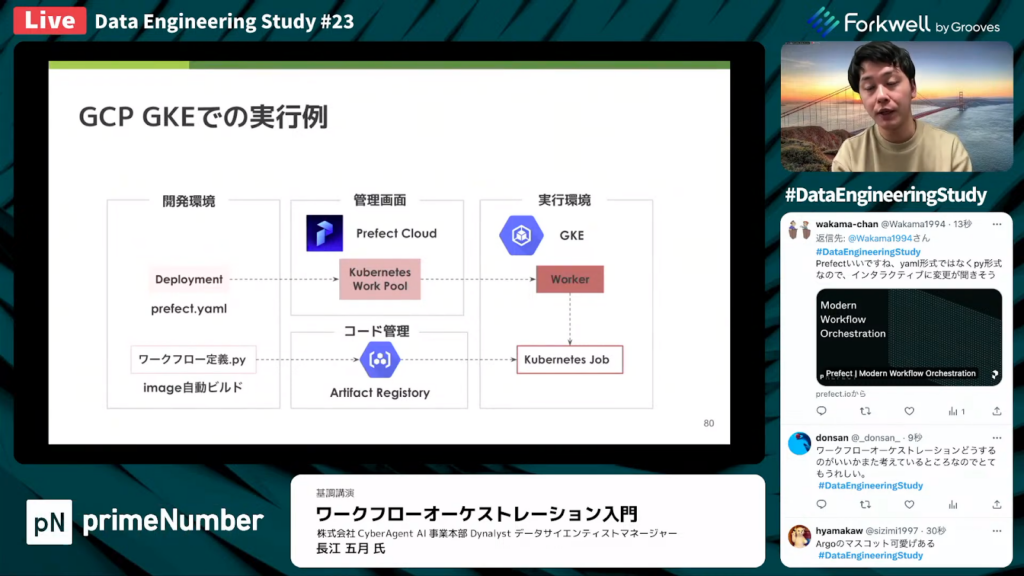
長江氏:「実際にGCPのGKEで実行する例をお見せします。
開発環境では、ワークフロー定義を書いたPythonファイルと、Deploymentにはprefect.yamlのYAMLファイルを作成します。prefect.yamlを基にして管理画面にDeploymentを登録すると、ワークフロー定義のPythonファイルが入ったイメージが自動的にビルドされます。
ビルドされたら、Artifact Registoryにdockerイメージがプッシュされます。そして、GKE上のWorkerが実行時にイメージをプルし、Kubernates Jobとしてワークフローを実行します。」
Prefectの実装例②
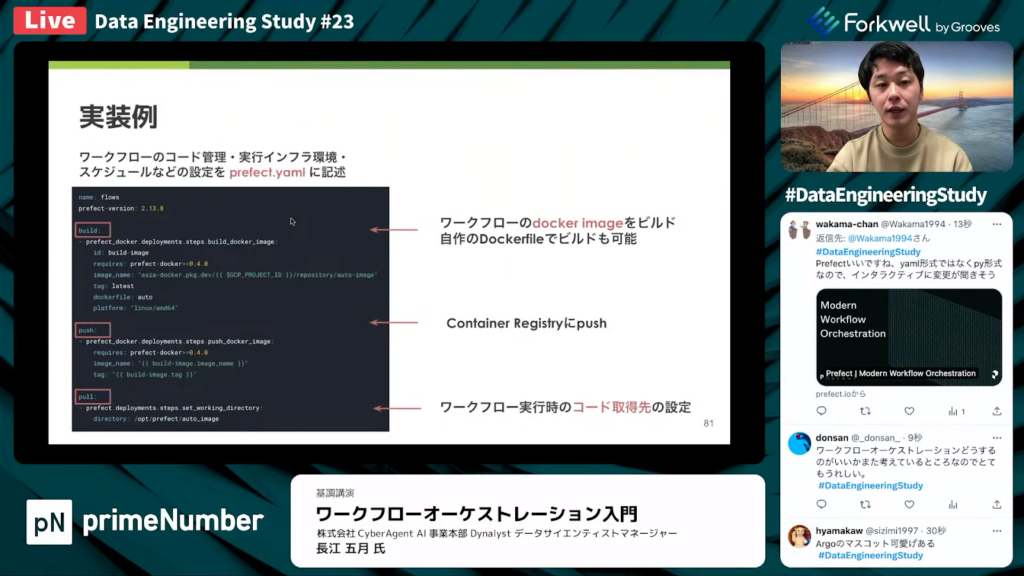
長江氏:「prefect.yamlは、ワークフローのコード管理と実行インフラ環境、スケジュールの設定をまとめたファイルです。
ビルドの設定を書け、何も設定しなければ、ワークフローのdocker imageが自動的にビルドされます。自作のDockerfileでもビルドが可能なため、必要なライブラリなどをまとめたイメージを用意できます。
work poolの設定を行うことで、実行したインフラ環境を容易に変更できます。例では、GKEのwork poolを使用していますが、この部分をECSなどの別のインフラのものにすれば、そのインフラで実行できるようになります。
また、tag.scheduleなどの設定をデプロイメントで行えます。」
PrefectのUI
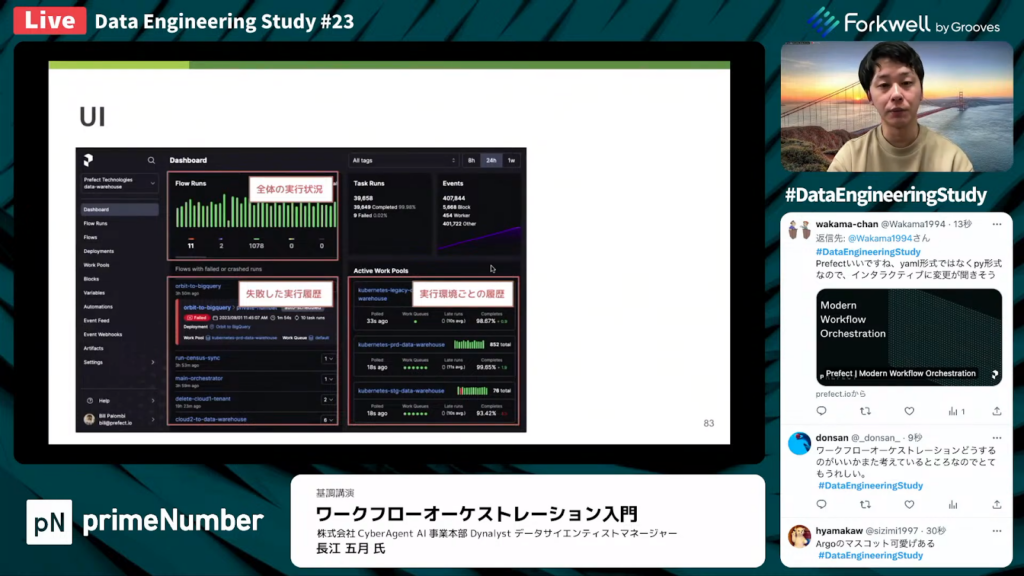
長江氏:「UIは、Airflowと比べるとモダンな印象です。
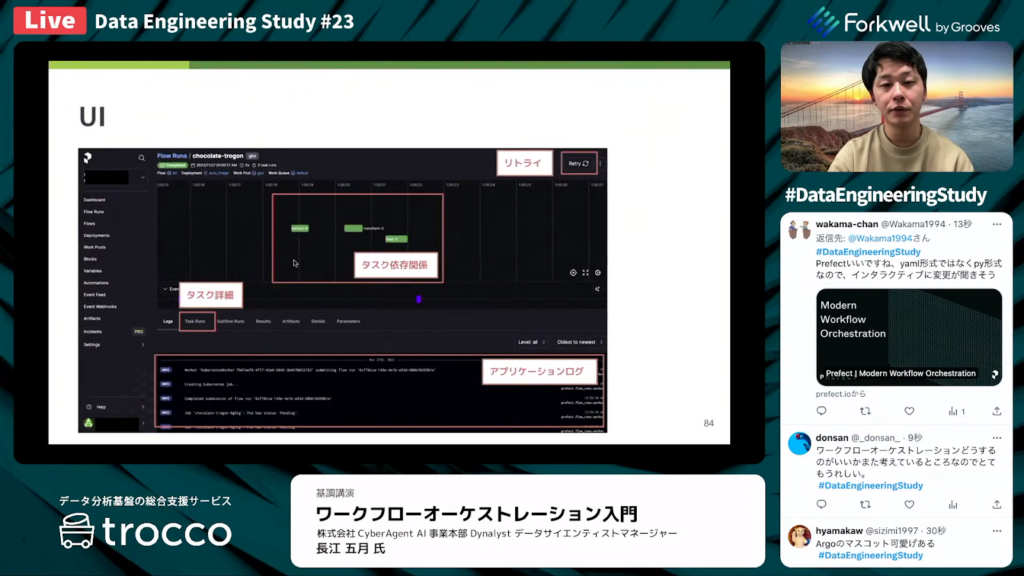
こちらが実行の詳細画面です。タスクの依存関係が視覚的に表されていて、アプリケーションのログを容易に閲覧できます。タスクの詳細も簡単に見れますし、リトライはボタン1つで行えます。」
Dagsterとは
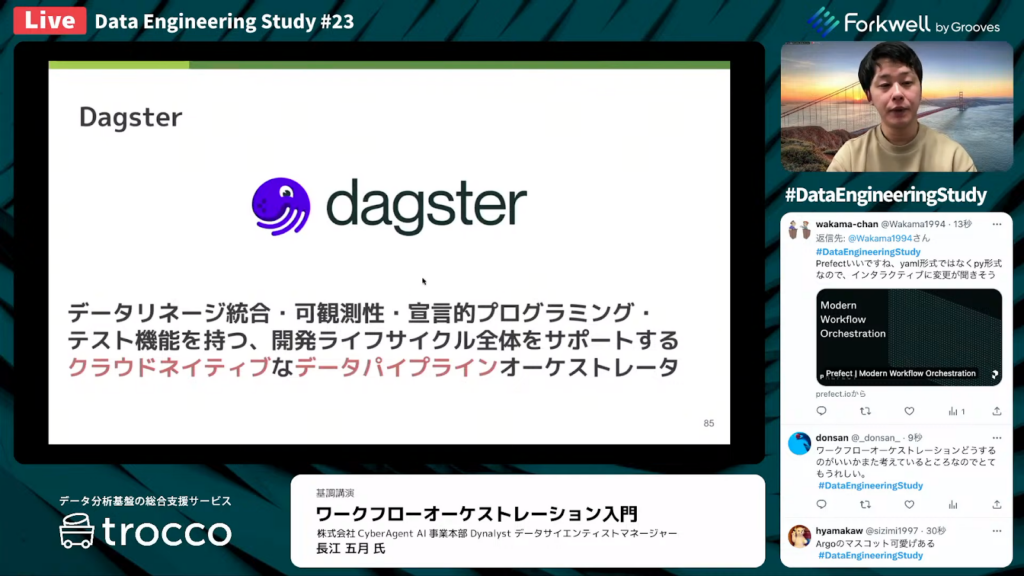
長江氏:「Dagsterは、データリネージの統合、可観測性、宣言的プログラミング、テスト機能を備え、開発ライフサイクル全体をサポートするクラウドネイティブなデータパイプラインオーケストレーターです。
Dagsterは自らを『データパイプラインオーケストレーター』と表現しています。」
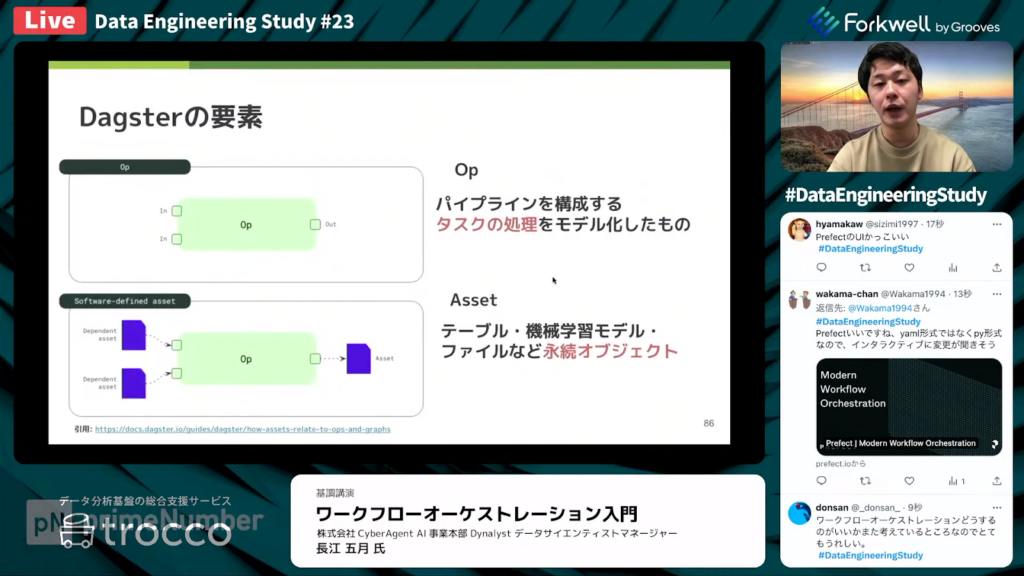
長江氏:「Dagsterには『Ops』と『Assets』の、2つの主要な要素があります。Opsはパイプラインを構成するタスクの処理をモデル化したもので、Prefectのタスクと類似しています。Dagster独自の概念であるAssetsは、テーブルや機械学習モデルファイルなどの永続化オブジェクトを指します。
Dagsterには、Software-Defined Assetsと呼ばれる概念があります。これは、テーブルやMLモデルなどの存在する必要があるAssetや、Assetの作成・更新方法をコードで表現したものです。データがどのように生成されるかをコードで表現できる強みがあります。
そのため、Dagsterの強みは、データ管理に特化してる点です。」
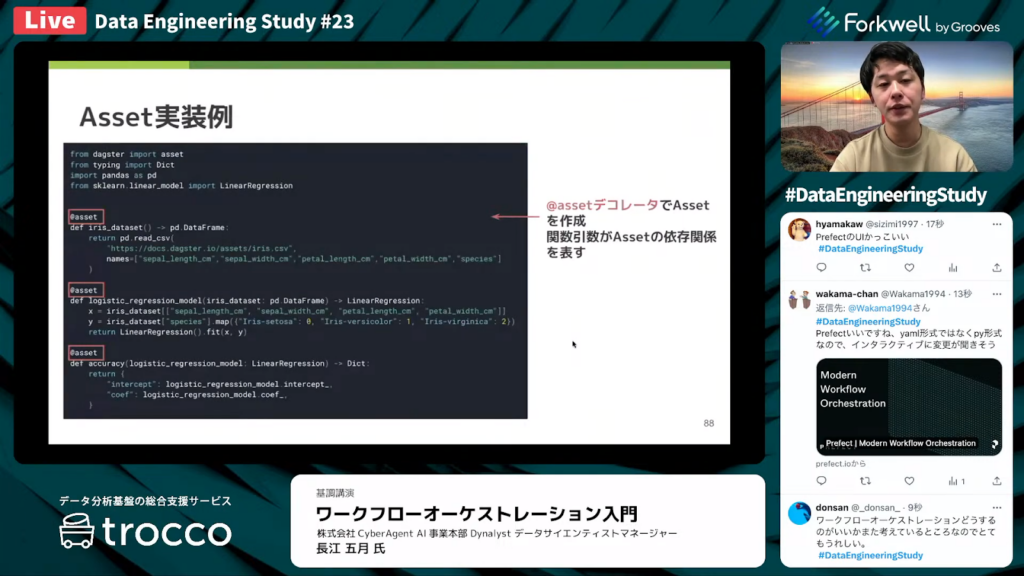
長江氏:「Assetは基本的にPython関数の形で記述され、『@asset』デコレータによって、DagsterにAssetとして認識されます。
関数の引数を通じてアセット間の依存関係を表現できます。たとえば、あるデータセットを使用してロジスティック回帰で予測を行い、その正確さを出力できます。」
AssetJobは複数のAssetをまとめたもので、Assetの実行や監視を行う集合を指します。
コード内でAssetJobを定義し、実行スケジュールを設定できます。最後に、Job実行に関わる設定をまとめ、Dagster Cloudに登録する流れになっています。」

長江氏:「クラウド環境で実行する場合は、Dagster Cloudを使用します。Dagster Cloudは課金制のサービスで、ServerlessとHybridの2つの実行環境を提供しています。
Serverlessは、Dagsterがインフラ環境を提供するフルマネージド型の実行環境です。一方Hybridは、ユーザーのインフラ環境で実行を行う方式で、Dagsterは実行のみを行います。」
Hybridの構成

長江氏:「Hybridでワークフローを実行する場合は、こちらの図のような構成になります。
Dagsterのポイントとしては、GitHubのブランチでプロダクションなどを変えていく仕様です。Dagster CloudにブランチのGitHub Actionsを通じて、Deploymentを登録します。
その時に、各ワークフローのコードの場所を管理している『dagster_cloud.yaml』で、コードのロケーションにdockerイメージがプッシュされます。Dagsterは基本的に、dockerイメージを使ってワークフローの実態を管理しています。
ハイブリッドモデルの場合、実行環境はユーザーが自前でインフラ環境を用意しますが、KubernatesやECSがサポートされています。Prefectと同じく、Agentと呼ばれるものを自前のインフラ環境に設置する必要があり、Agentがデプロイメントをポーリングして、ワークフローを実行制御します。」
AWS ECSでの実行例
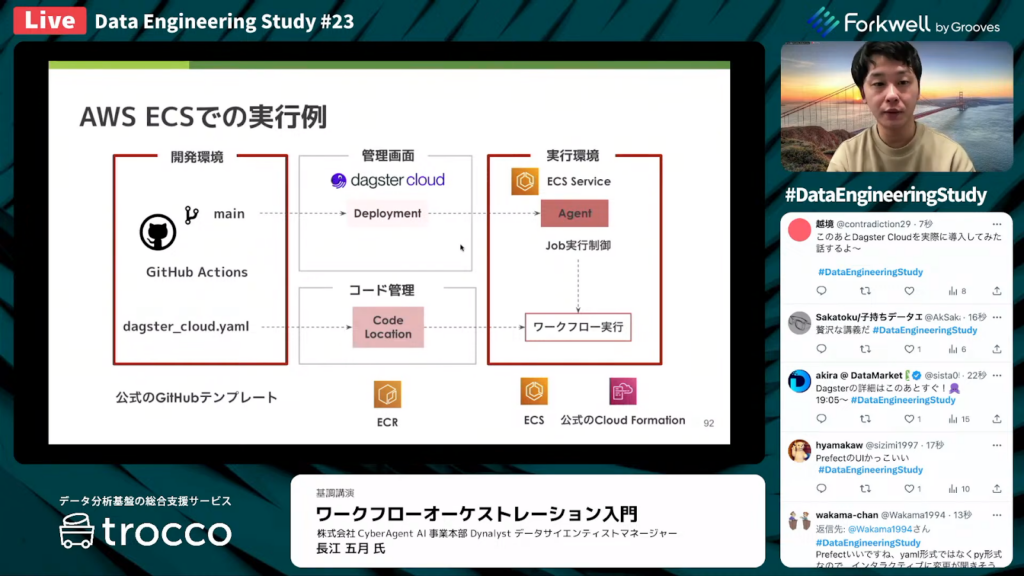
長江氏:「AWS ECSでDagsterを実行する場合、公式のGitHubテンプレートを使用することで、すぐに環境を構築できます。コードのロケーションはECRです。
ECS ServiceとしてAgentを起動する必要がありますが、公式のクラウドフォーメーションが用意されているため、簡単に自分の環境でECS Serviceを立ち上げられます。」
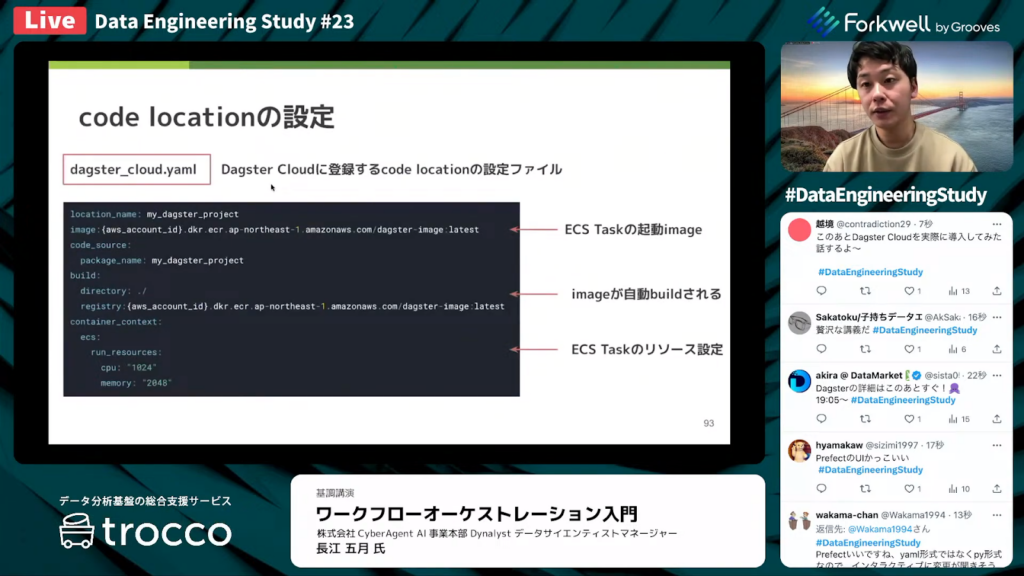
長江氏:「ECRの設定を書く必要があります。基本的に、イメージは自動でビルドされますが、自分で依存関係を書いたdockerファイルなども使ってビルドできるようになっています。
ECS Taskのリソース設定も可能で、各タスクのリソースを簡単に設定できます。」
DagsterのUI
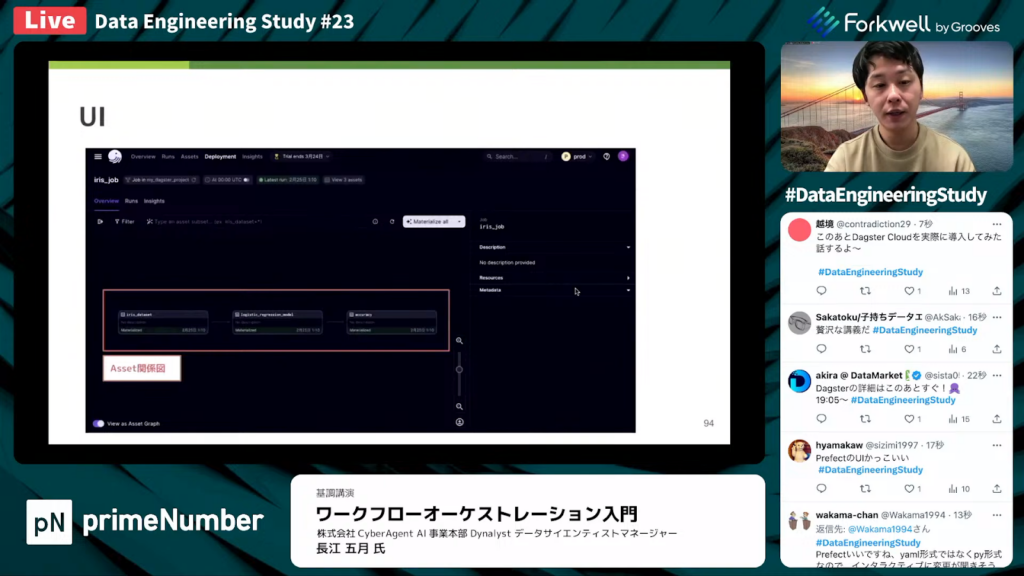
長江氏:「DagsterのUIでは、データごとの関係性が視覚的に分かりやすく表示されます。」
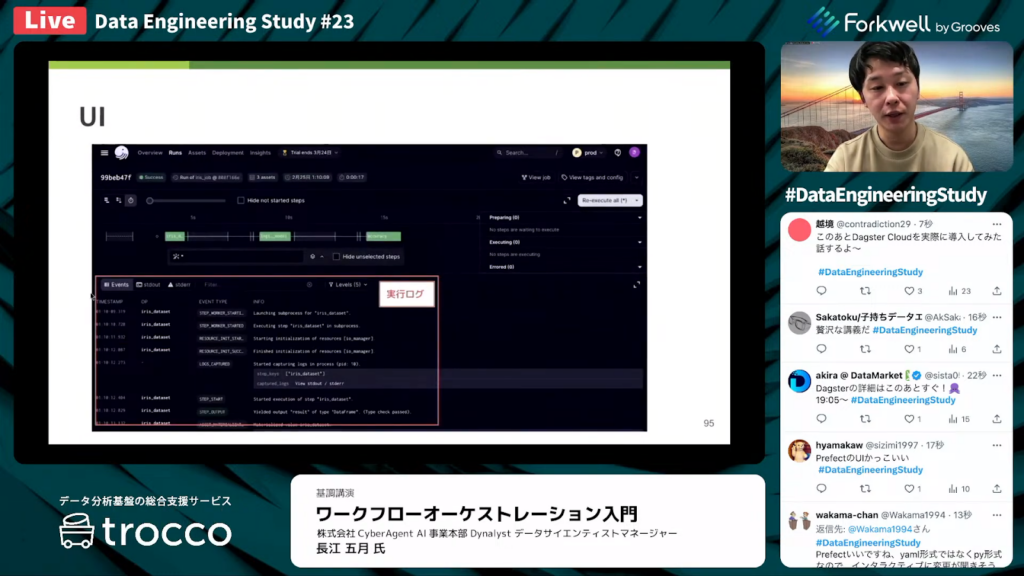
長江氏:「2枚目のスライドが実行の詳細画面です。ログがグラフィカルに表示され、ユーザーが実行状況を直感的に把握できます。」
StepFunctionとは

長江氏:「StepFunctionは、AWS Lamda関数と他のAWSサービスを組み合わせてビジネスクリティカルなアプリケーションを構築できるサーバレスのオーケストレーションサービスです。ポイントは、サーバレスな点です。
特徴としては、AWS LamdaとAWSサービスで一連の処理を制御します。」
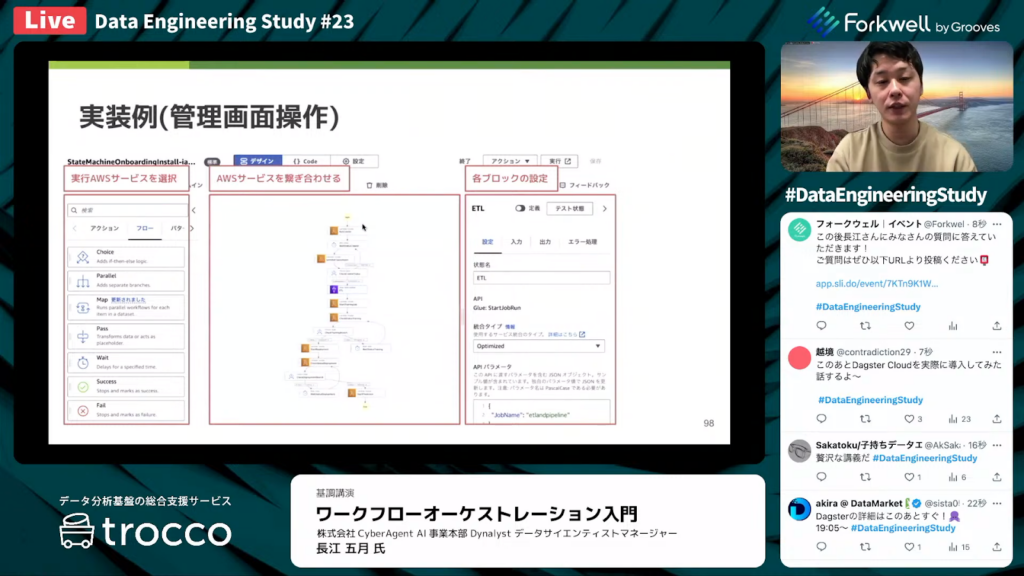
長江氏:「管理画面操作において、実行するAWSサービスの依存関係をドラック&ドロップでつなぎ合わせられます。」
StepFunctionの実装例(JSON)
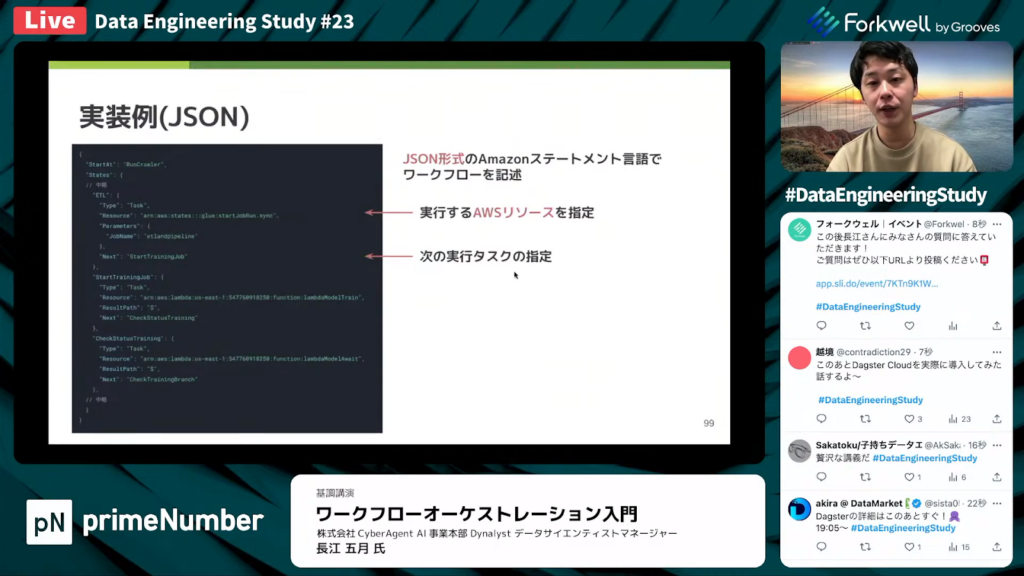
長江氏:「JSON形式でワークフローを定義できます。基本的には、実行するAWSリソースを指定する形です。」
StepFunctionのUI
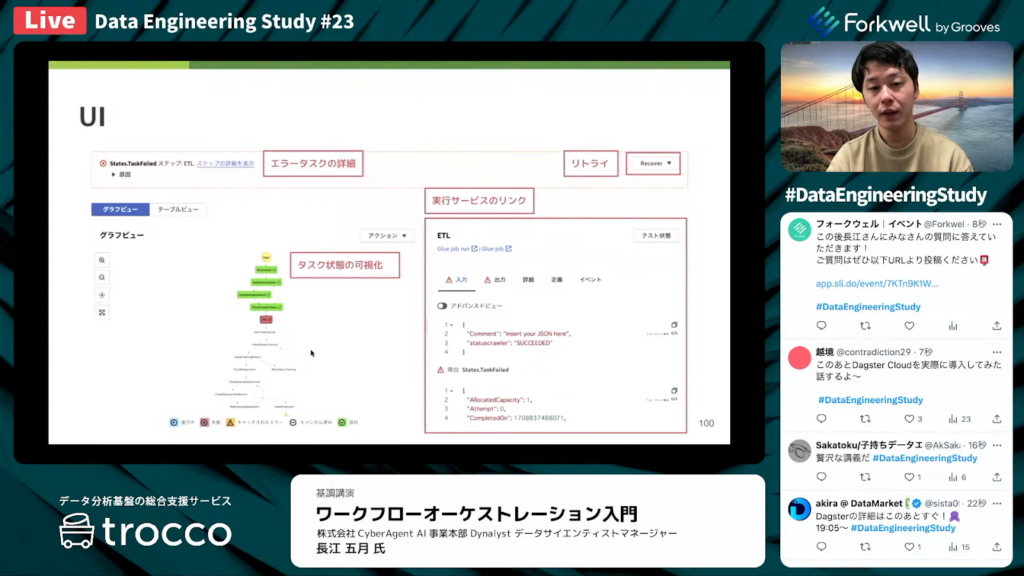
長江氏:「StepFunctionのUIはこちらのとおりです。タスクの状態を可視化できて、関連するAWSのサービスへのリンクを表示します。StepFunctionはあくまでAWSサービスを実行制御するツールであるため、実行の詳細は各サービス画面で確認する必要があります。」
ここからは、今までの話を踏まえ、どのワークフローツールを選べばよいかについて解説していただきました。
ワークフローエンジンについて、はじめに考えること

長江氏:「『実践的データ基盤への処方箋』からの引用すると、『はじめに考えることは、データ基盤「専用」のワークフローエンジンにするか、会社のワークフローエンジンに「相乗り」するかです。』と書かれています。
既存のワークフローツールに相乗りするメリットは、データやMLエンジニアがワークフローツールの実行環境を運用しなくてよい点です。また、事業システムの処理とデータ基盤の処理を1つのワークフローで制御できる点も強みです。
デメリットとしては、データ基盤のワークフローを気楽に変更できなくなります。さらに、事業システム側のワークフローツールがレガシー化してしまい、使いにくい場合があると思います。
メリットが勝っているのであれば、基本的には相乗りするのがよいと思います。しかし、デメリットの方が勝っているのであれば、データ基盤に新しくワークフローツールを導入した方がよいと思います。
ワークフローツールを新しく導入する際の選定基準として、本から引用すると、『選定の基準になる考え方はシンプルに「使いやすい製品かどうか」です。』と述べられています。
私なりにもう少し噛み砕いて考えると、『使いやすい』とは技術・人・お金の制約の中で、目の前のプロダクト課題を解決できる最も扱いやすいものだと思います。そしてこれらを満たすツールこそが、選ぶべきワークフローツールになると考えます。」
6つのワークフローツールの特徴比較
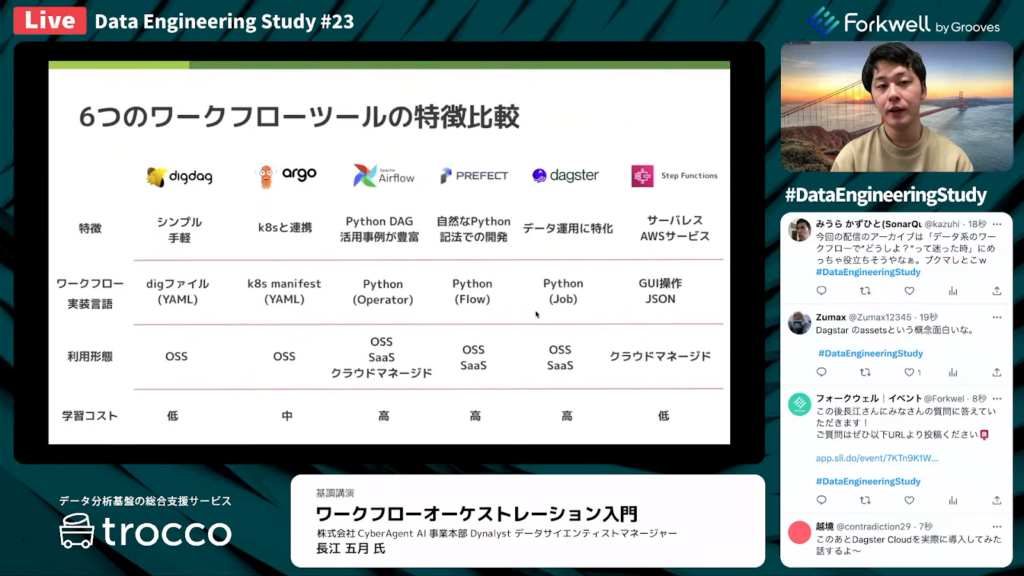
長江氏:「改めて、6つのワークフローツールの特徴をまとめます。
それぞれの注目すべきポイントが大きく異なります。Digdagであれば非常にシンプルで手軽な点が魅力ですし、ArgoであればKubernatesとの相性が良いです。
コスト面を考慮すると、OSS・SaaS・クラウドマネージドサービスのうち、どのサービスを使用するかが重要になります。また、Pythonに通ずるメンバーが少ないのであれば、AirflowやPrefect、Dagsterを選ぶことは難しいと思います。学習コストもワークフローツールごとに大きく異なります。」
Digdag・Argo・Step Functionのおすすめユーザー

長江氏:「それぞれのツールが誰にとって使いやすいかを私なりにまとめました。
Digdagは、シンプルなバッチ実行で十分な人や、ワークフローツールにお金をかけたくない人にとって、コスパのよいツールだと思います。既存システムをKubernatesで構築している人は、まずArgoが選択肢に上がってくるでしょう。AWSを利用していて、小規模なワークフロー実行で十分なチームには、StepFunctionが適切なツールだと思います。」
Airflow・Prefect・Dagsterのどれが使いやすいか
長江氏:「Airflow・Prefect・Dagsterの中で、結局どのツールが1番使いやすいかという議論がよく行われており、Redditでも既に同様の議論が行われています。各ツールの好意的なコメント数を集計した結果、今のところDagsterの数が最も多かったです。
あくまで一例ではありますが、AirflowからDagsterやPrefect、他のツールに移行した人が多い印象を受けています。」

長江氏:「個人的な評価ですが、Airflowは最も有名であるため、ノウハウが世に数多く出ていて安心感があります。ただ、ハマリどころが多いという意見も聞くため、『とりあえずAirflow』の選択は、後々苦しむことになるかもしれません。
Prefectは拡張性が高く、Pythonに慣れている人には非常に使いやすいツールです。一方、インターネット上に出ている情報が少ないため、初学者には学習コストが高いでしょう。
Dagsterは、とにかくデータエンジニアに寄り添った仕様になっています。公式ドキュメントや実例がPrefectに比べて整備されているため、初学者でも取り掛かりやすいツールだと思います。
各ツールの評価を述べましたが、結局は実際に使ってみて、チームが使いやすいツールを選ぶことが大事だと思います。」
LT1「データオーケストレーションツールDagsterの紹介」
岩崎 晃 氏
株式会社Data Market 代表取締役
SIerとしてキャリアをスタートし、ハードウェア・OSの開発に10年以上携わる。2017年にはフリーランスとして独立。今年(2024年)でデータエンジニア7年目となる。
データ業界は盛り上がっている

岩崎氏:「今、データ業界全体が大きな盛り上がりを見せています。
エポックメイキングな出来事として、ChatGPTをはじめとするLLM処理技術などの機械学習技術が台頭してきました。これにより、データのことを知らなかった層にも価値が認知され始め、社内でデータを集めて活用する動きが世界的に活発になっています。
それに伴い、もう1つ大きな出来事として、データが2025年からGDPに含まれ、資本として見なされるようになります。私は昔から、データとお金が以下のようなよく似た性質を持っていると考えています。
- 多ければ多いほど、価値が出る
- 量が指数級数的に増加する
- 多いところにより多く集まる
この点は少し複雑なため、よろしければ補足資料にて詳細をご覧ください。」
データエンジニアリングにも注目が集まっている

岩崎氏:「中でも、機械学習技術の台頭によって、データを整備する動きも注目され始めたように感じます。機械学習の精度向上には、データ整備が課題になるでしょう。
機械学習によりクエリや分析の難易度が下がったことで、アナリストやサイエンティストに比べて、データエンジニアの価値が相対的に高くなってきているように感じます。特に最近は、データエンジニアは分析や提案もできる混合人材の需要が高く、結局さまざまな技術がコモディティ化するため、技術を掛け合わせられる人が1番強いと考えています。
そしてデータが資本扱いになると申し上げましたが、今の状況はまさにデータという金を掘るゴールドラッシュに例えられると考えています。
当時1番儲かったのは採掘者ではなく、ジーンズやツルハシを売った人であるという教訓があります。まさにデータエンジニアは、データを掘る人でもあり、ジーンズやツルハシを売るような細かい整備をする人でもあるのではないかと考えています。
そして将来はさらに仕事が細分化されて、データアテクトやデータスチュワードなどの職種も注目されていくのではないかと考えています。」
データエンジニアリングの進歩

岩崎氏:「データエンジニアリングとは、データの収集・蓄積・加工・管理を行うためのシステムやプロセスの設計・構築・維持の技術を指します。
近年、データエンジニアリングの流れは変化してきました。以前はビッグデータというワードが独り歩きしていましたが、最近では『大きなデータはSnowflakeを使おう』『ELTやデータモデリング、dbtを使おう』のように、世間的に収集や蓄積、加工の段階の代表的なサービスが決定してきた印象があります。
しかし、データエンジニアリングの加工の段階において『皆が使っているサービス』は、まだ思い当たらないのではないかと思います。」
データエンジニアリングの課題

岩崎氏:「こうした状況は、データマネジメント成熟度モデルと照らし合わせてみたときにも、同じことが言えると思います。
世の中のデータエンジニアリングは、着実にレベルが上がってきているように感じます。私自身の経験や実感としましても、DMMにしたがって携わってきた案件の内容も、次第に高度化・最適化されており、データエンジニアリング分野が進歩してきたのだなと実感しています。
DMMにおける高レベルの段階は、データエンジニアリングにおける管理の段階に当たると考えています。しかし、やはり頭にパッと思い浮かぶような支配的なツールはまだ登場しておらず、DMMの高度なレベルへの対応は自前の内製ツールや高額のサービスで賄っている状況です。」
Data Assetを統合するプラットフォーム

岩崎氏:「そのようなデータエンジニアリングの管理の問題を、もう少し掘り下げてみたいと思います。
急激な需要拡大に伴い、さまざまな標準化のスピードが追いついていないように感じます。WebならWeb、製造業なら製造業、行政なら行政といったように、データの表現法が異なりますし、流儀も言語も違います。また組織内においても、使用しているデータ管理方法も違いますし、それらを統合しなければデータの連携は難しいままです。
右の図は、Dagsterが考えるデータ組織の模式図です。Dagsterはそうした問題を解決するために、組織や技術などの違いを吸収して連携するデータプラットフォームとなり、これらを統合しようと考えています。」
Dagsterの概要

岩崎氏:「ご存知ない方も多いと思うので、改めてDagsterについて簡単に説明します。
Dagsterはデータオーケストレーションツールの1つです。データオーケストレーションとは、企業全体のデータ設定・管理・調整の自動化を指します。よく比較されるデータパイプラインは、データオーケストレーションに包含されるものと考えていただけたらと思います。
DagsterはAirflowを超える目的で作られており、これから紹介する機能はAirflowになかった機能です。(長江氏から)Prefectがv2.0になってから大きく変わったというお話があったとおり、Prefectもデータオーケストレーションに寄せてきている印象があります。」
Dagsterはデータプラットフォームである

岩崎氏:「『Dagsterがデータプラットフォームを目指している』というのは、Dagster自身の言葉です。Dagsterの創始者であるNick Schrockは以下のように述べています。
- データの世界は多数のドメインによりサイロ化している
- これらのデータの分断は、サイロ化ではなくレイヤーとして捉えるべきである
- レイヤーとして捉えるというのは、組織全体で機能を統合しながらレイヤー上で異種ツールを柔軟に導入して利用できるようにすること
そして、そうした違いをまとめるのは、1つのプラットフォーム上で行うべきという考え方があります。」
Dagsterの学習コンテンツ・コミュニティ

岩崎氏:「Dagsterの概念を学習するには、これから登場する独特な概念の理解も必要になります。そのためにDagsterは、いくつかの学習コンテンツを用意していたり、コミュニティでの意見交換を活発にしていたりします。
たとえば、Dagster Universityと呼ばれる学習コンテンツがあります。6時間から10時間の無料学習カリキュラムをご用意しています。他にも、Slack Communityでは、メンバーがおよそ1万人いたり、分からないことは質問用チャンネルでAIがすぐに解答してくれたりする対応があります。
また、私の資料にも参考になる情報が掲載されているため、ぜひご覧ください。」
つづいて、Dagsterの中核概念であるData Assetについて紹介していただきました。
DagsterのData Assetとは

岩崎氏:「Data Assetとは、企業のデータ資産をデータレイヤーで抽象化し、データリネージとして視覚化したものを指します。
Dagsterには、Asset Materializationと呼ばれる機能がございます。クエリなどを実行することで、データの更新と同時にメタデータを収集し、企業のデータ情報をData Assetの形で管理できます。Assetとして表現できるのは、テーブル・ファイル・機械学習モデルなどの
永続ストレージのオブジェクトです。要するに、企業にあるデータと見なせるものを一覧にして表現する機能です。」
Asset Materializationとは

岩崎氏:「Data Assetは、dbtのようなデータを更新するために調整するジョブ以外にも、データスタックがある場合に役立ちます。
『一部のAssetは、15分ごとに更新する必要がある』『他のAssetは、上流のAssetが更新された後に更新する必要がある』『データが古くなった場合のみ更新すべきものがある』のように、データにはそれぞれ必要な更新頻度があります。
そのため、各Data Assetに鮮度という概念を設けています。データの鮮度に応じた更新をすることで、無駄なクエリやジョブ実行を避けられ、コスト削減につながります。」
Data Assetのメタデータ
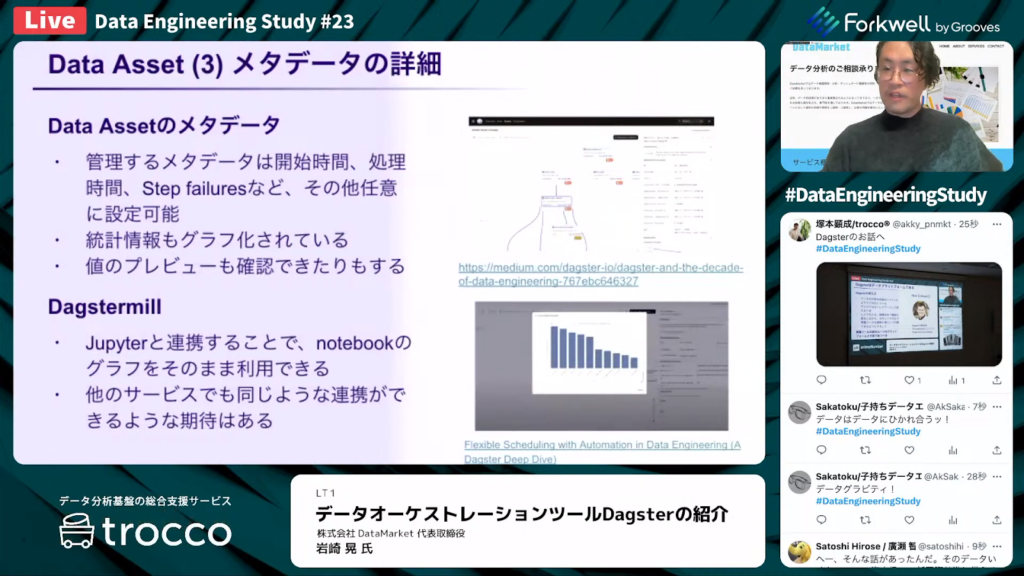
岩崎氏:「Data Assetの管理するメタデータは、開始時間や処理時間、失敗による停止、他にも任意に設定できます。また統計情報もグラフとして表現できますし、データの読み込みの仕方次第でデータ一覧のプレビューなども見られます。
さらにAssetの詳細からは、DagstermillなどではJupyterと連携することで、notebookのグラフを閲覧できます。このような連携は、ますます拡充されていくものと思われます。」
つづいて、Dagsterの機能について紹介していただきました。
Dagsterの機能①「LaunchPadとGraph」
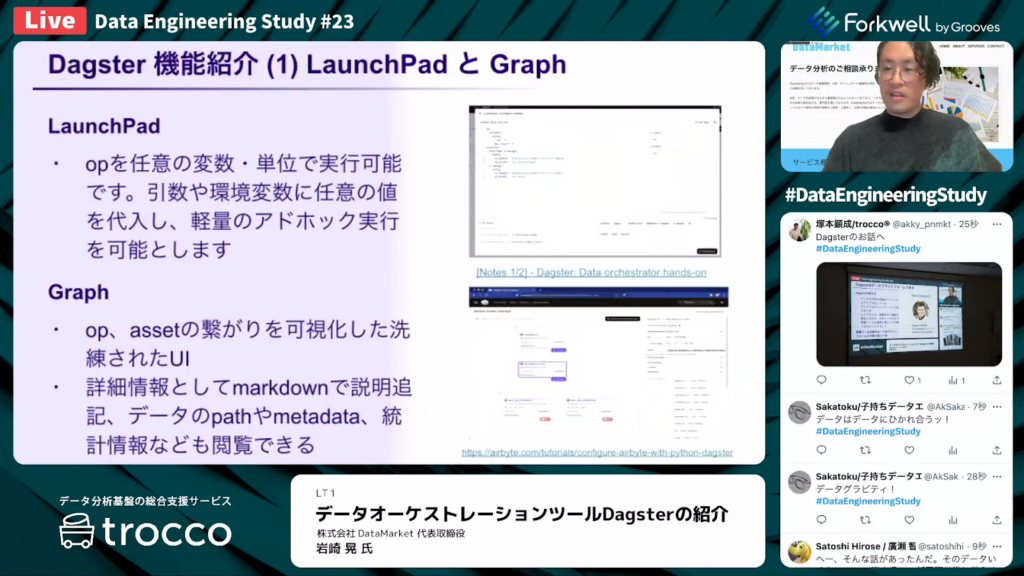
岩崎氏:「LaunchPadは、処理を任意の変数・単位で実行できる機能です。Dagsterの処理の最小単位であるOpに、任意の引数や環境変数を代入し、実行単位も自由に変えられ、軽量のアドホック実行を可能にします。他にも、単体テストをする時などに役立ちます。
Graphは、OpやAssetの繋がり、または全体のパイプラインを指します。Graph自体は処理の繋がりを示すだけですが、UIのビジュアライゼーション機能が強力です。また、編集にmarkdowを使用でき、細かい表現が可能です。」
Dagsterの機能②「SensorとResource」
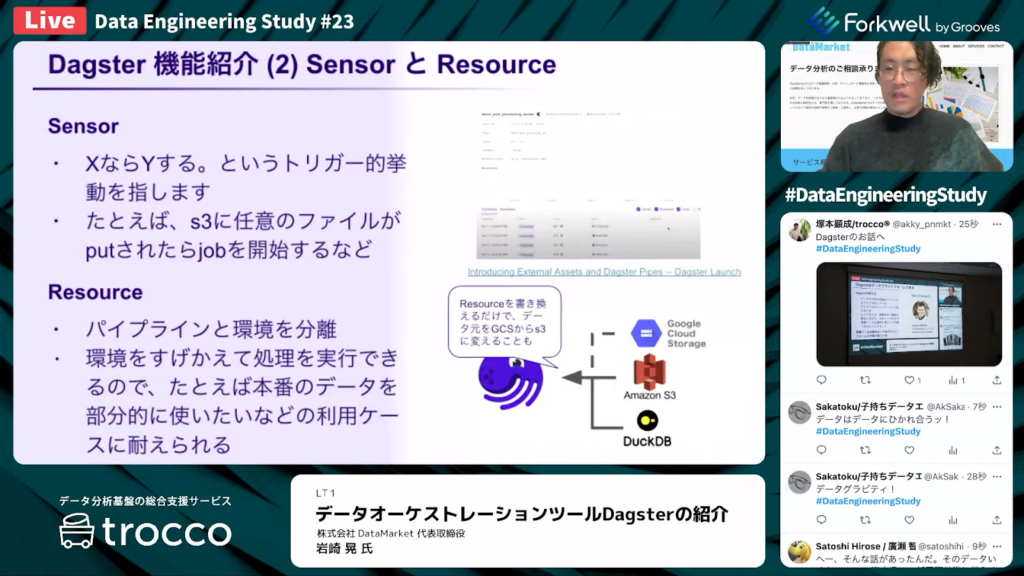
岩崎氏:「Dagsterのセンサー機能は、『XならYする』トリガー的挙動を指します。この挙動は非常に柔軟に設定可能です。たとえば、S3に何らかのファイルがプットされたらジョブを開始するなど、外部サービスと連携した条件を設定できます。
こうした点は後で紹介するインテグレーション機能のように、他のサービスとの連携を見据えた機能になっています。
DagsterのResourceでは、ストレージに『S3ならS3を使う』『RDSならRDSを使う』といった環境を、パイプラインとは別で定義します。こうすることで、ジョブがどの環境を使っているか意識する必要がなくなります。
たとえば、開発中に本番にしかないデータを使いたいケースがよくあると思います。そうした場合にも、リソース部分だけ取り替えれば、リソースを意識することなく処理を継続できます。」
Dagsterの機能③「Deployment」
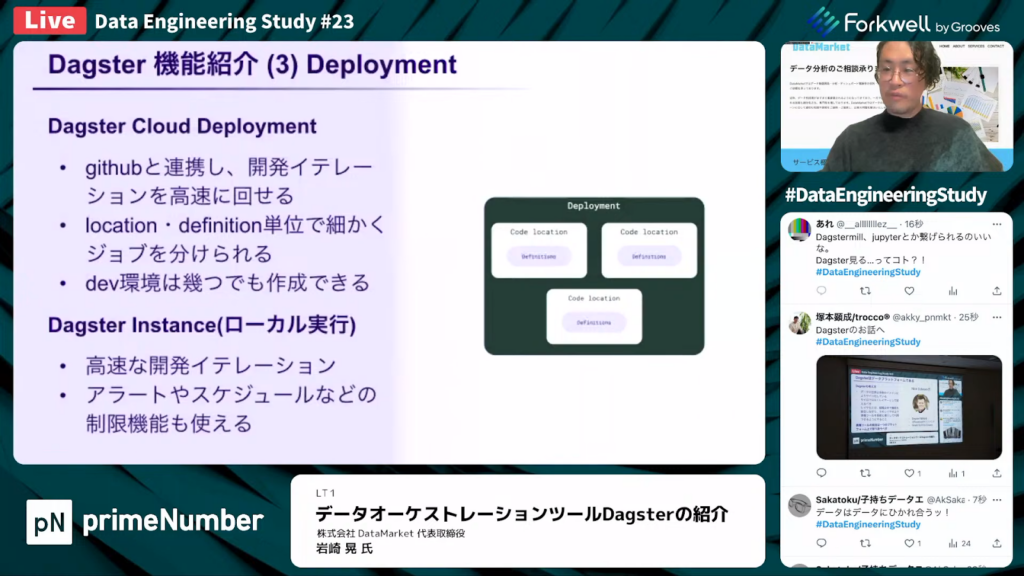
岩崎氏:「Dagster Cloud Deploymentとは、基本的にDagster Cloudに対するデプロイを指します。
この機能はGitHubと連携してPull Requestに変更が入った時点で、自動デプロイを走らせ、高速に開発イテレーションを回したり、location・definition単位でジョブを切り分けられたりします。また、プロリーグに紐づける形でいくつでも環境を作成できます。
デプロイとは異なりますが、ローカルでDagsterを起動する方法もあります。ローカル実行では、Dagster Cloudの開発環境で制限されている機能も使えます。
デプロイの概念は少し難しいため、よろしければ私の資料を参考にしてください。」
さいごに、Dagster Integrationについて紹介していただきました。
Dagster Integrationとは

岩崎氏:「繰り返しになりますが、Dagsterでは複数のデータサービスを単一のプラットフォームにまとめようとしているため、さまざまなサービスを包含する動きが活発です。
まずELT/ETLツールとして、Airbyte/Fivetranなどのメジャーどころはもちろん、他にも踏み込みELT機能を実現し、年間数万ドルのコスト削減を実現しました。
そして注目したいのは、SparkやDatabricksなどの競合しそうなワークフローエンジンとの連携もできていたり、PrefectやAirflowも実はインテグレーションの対象として巻き込んだりしている点です。」
Dagsterの連携①:dbt
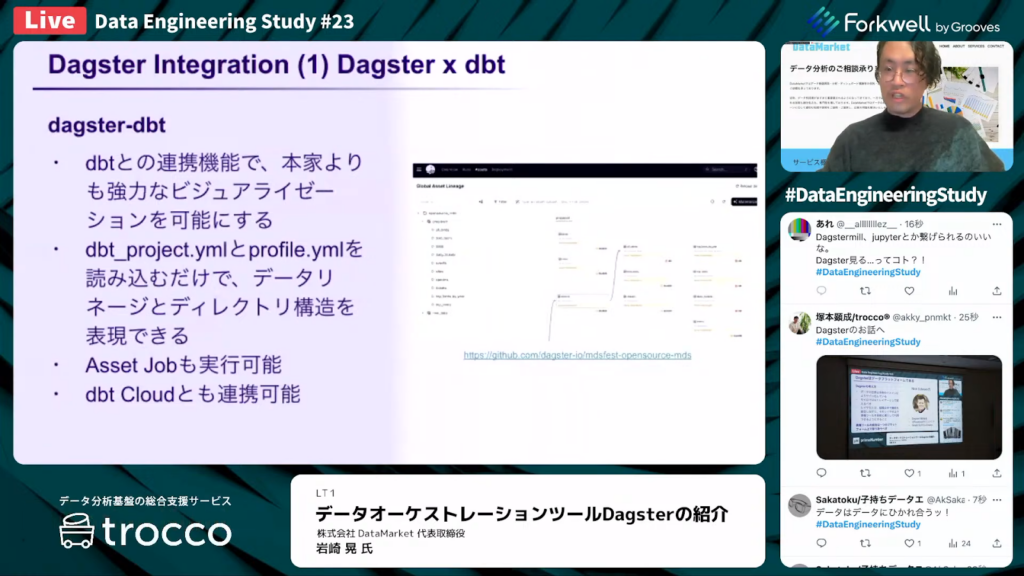
岩崎氏:「Dagsterでは、dagster-dbtと呼ばれるモジュールで、dbtと連携できます。dbtでは、dbt docsでデータリネージを閲覧できます。しかしdbtの設定を読み込むだけで、それよりさらに綺麗なリネージを作ってくれます。
またdbt Cloudとの連携も可能です。後ほど、詳細な説明があります。」
Dagsterの連携②: Cube
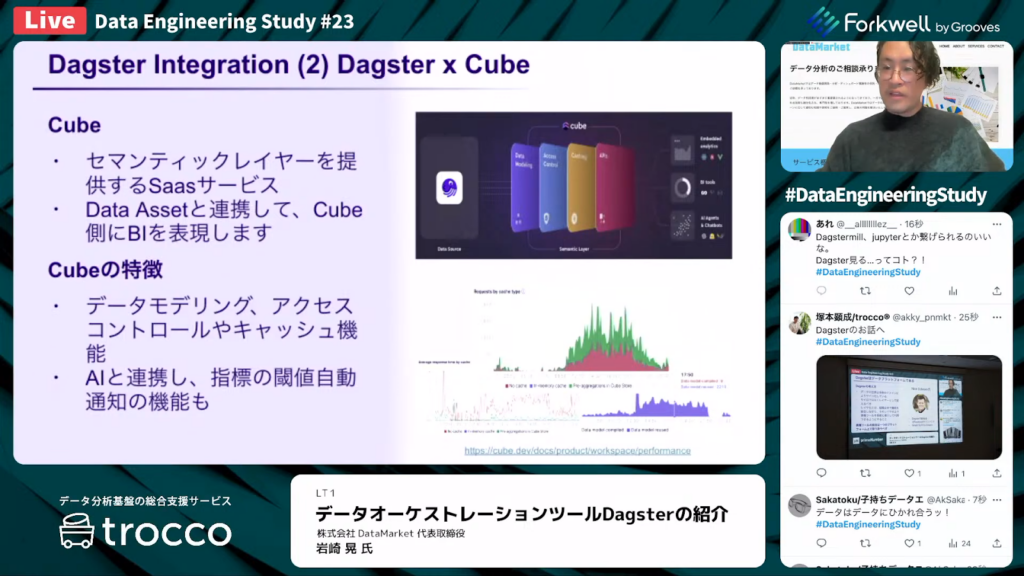
岩崎氏:「つづいて、Cubeとの連携も紹介します。Cubeはセマンティックレイヤーを提供するサービスであり、CubeとDagsterを統合することで、データパイプラインとセマンティックレイヤーのシームレスな接続を可能にします。
セマンティックレイヤーによってBI設定をコード化することで、ビジネス職などの方にもBIを簡単に利用できるようにします。近年、セマンティックレイヤーはさまざまなサービスで用いられるようになっており、大きな注目を集めています。
Cubeのセマンティックレイヤー以外の機能としては、データモデリング・アクセスコントロール・キャッシュ機能に加え、AIと連携して指標の閾値を超えた時に自動通知してくれる機能もあります。」
Dagsterの連携③:Secoda
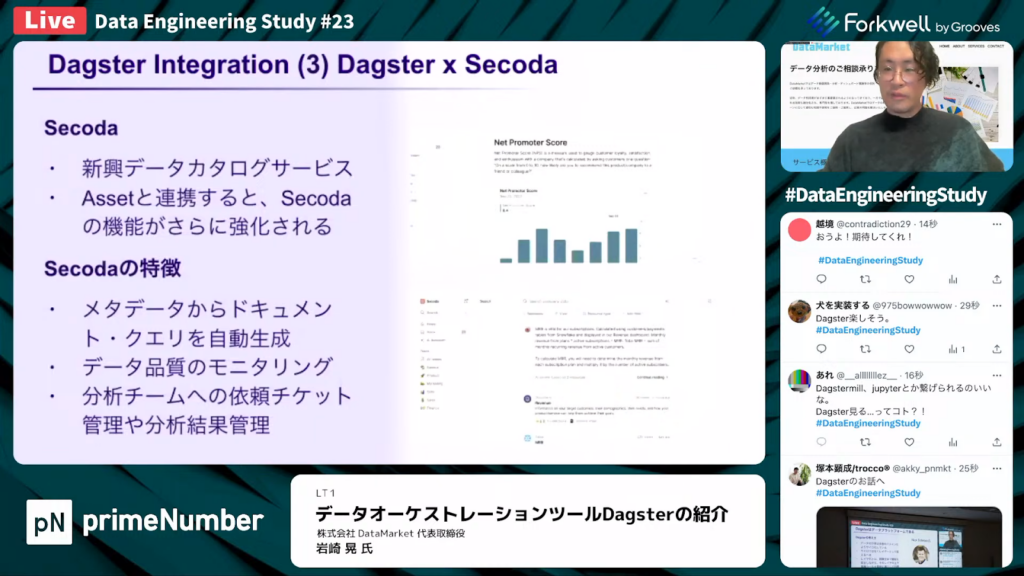
岩崎氏:「Secodaはメタデータの管理ツール、つまりデータカタログです。メタデータをAssetより細かく専門的に管理可能で、DagsterのData Assetを強化します。
Secodaは発展中のデータカタログツールであり、大型の資金調達を果たしていることもあって、今非常に注目を浴びています。シリーズAでは、同時期のdbtの調達額より多い1400万ドルを調達しました。
世界的なデータカタログのサービスとなり得ると期待されており、企業のデータに明るくない方からデータを専門的に扱う人まで、データ利活用の窓口になる使われ方がされると考えています。」
まとめ

岩崎氏:「Dagsterが単なるパイプラインではなく、プラットフォームになるという話をしてきました。
ここに来てデータ系のツールは百花繚乱になってきました。プラットフォームとしてまとめあげることができたら、非常に有用なサービスとなると思います。
機能を詰め込みすぎてダメになっていったサービスはたくさんありますが、Dagsterのデータプラットフォームの夢は果たして叶うのでしょうか。引き続き注視していきたいと思います。」
LT2「dbtをDagster Cloudでオーケストレーションする」
上村 空知 氏
株式会社Algoage データエンジニア
Web系のスタートアップ企業に所属。データエンジニアリングをはじめとした、データに関する仕事は何でも行う。『健常者エミュレータ事例集』の管理人。Snowflake・dbt・Dagsterが好き。
はじめに、dbtをオーケストレーションする技術の選定ポイントについてご説明していただきました。
dbtをオーケストレーションする技術の選定ポイント5つ
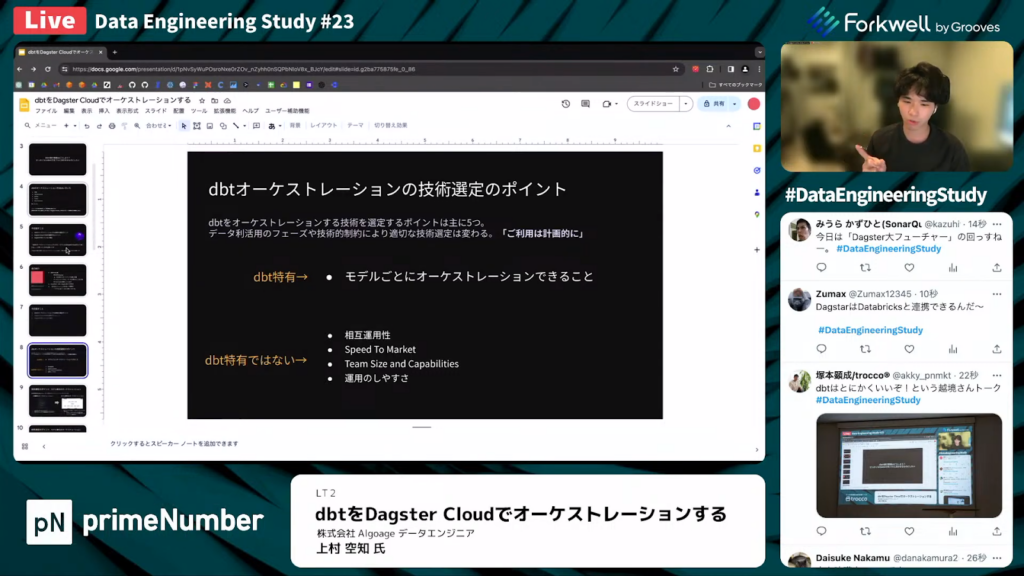
上村氏:「dbtをオーケストレーションする際の技術選定には、主に5つのポイントがあります。
まず1つ目は、dbt特有の機能である、モデル単位でのオーケストレーションが可能である点です。これに加えて、dbtを使用していないケースでも共通して重要視されるポイントが4つあります。
これらについて、順を追って説明していきます。」
モデル単位のオーケストレーション
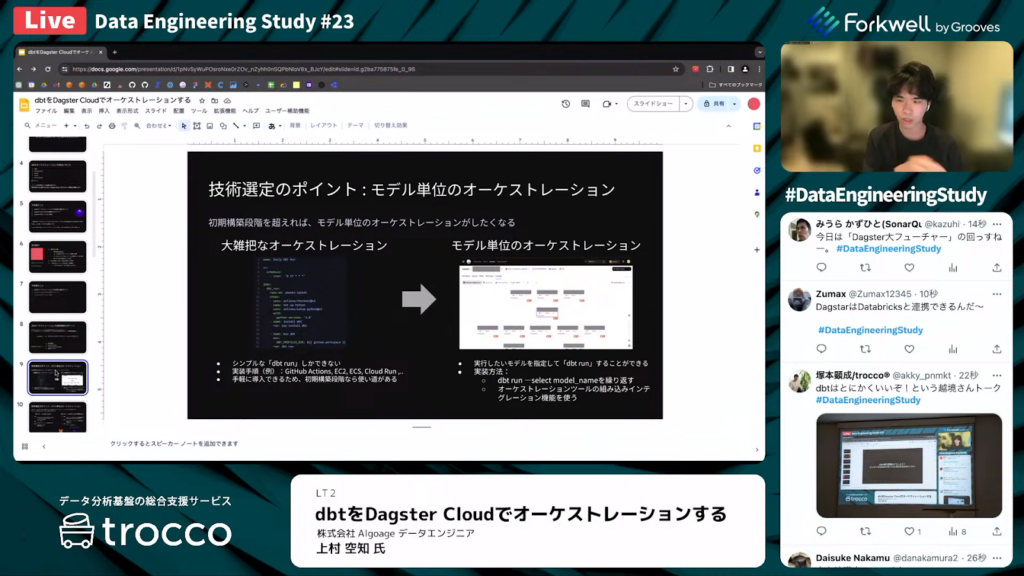
上村氏:「モデル単位のオーケストレーションとは、一見、何を指しているのかわかりづらいかもしれません。図に示されている内容を簡単に説明すると、オーケストレーションには大まかに2つのタイプがあります。
1つ目は、左側の図に示された、より大雑把なオーケストレーションで、主にシンプルなdbt runのみを実行する方法です。この方法はCRONで定期的に実行され、導入が手軽であるため、初期構築段階では有用ですが、それ以外の段階ではあまり用途がありません。
2つ目は、右側の図に示された、モデル単位のオーケストレーションで、実行したいモデルを指定してdbt runを行う方法です。dbt runはdbtの実行コマンドを指します。
モデルごとにdbt runをするコマンドがあるため、モデル単位でオーケストレーションを行えます。ただ、それ以外の方法もあるためご紹介します。こちらは、分岐の話になります。
モデル単位のオーケストレーションを実装する方法は大きく2つあります。
1つ目の方法は、AirflowのBashOperatorや他のコマンド発行可能なツールを使用して、モデルごとに『dbt run–model_name』を実行する方法です。この方法では使い慣れているツールに直接統合できて便利ですが、実装が複雑になりがちで、動作も重くなる可能性があります。
もう1つの方法は、『dbt run–model_name』を使用しない方法です。この方法はスマートに実装できますが、実現できる手段が現状限られています。おもに、dbtと統合機能を持つツールを使用することが前提になります。Dagsterやdbt Cloud、またAstronomerが提供するdbt用のインテグレーションパッケージCosmosなどがこれに該当します。
dbtの機能を最大限に活用することができますが、選択できるツールが限られるため、利用可能なシナリオも限定されます。」
その他の技術選定のポイント
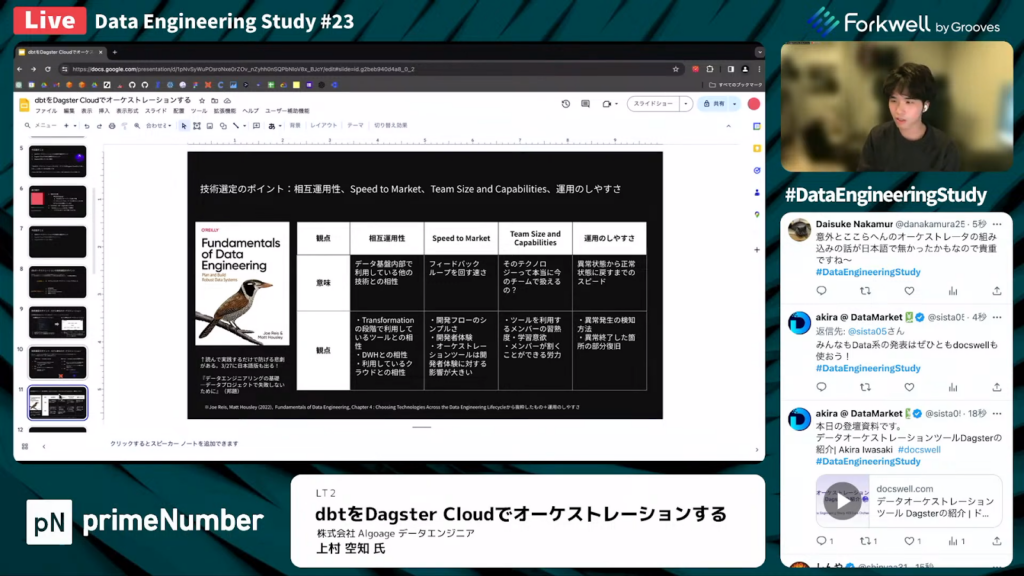
上村氏:「技術選定のポイントは他にも4つあります。
ちなみに、私の説明内容はほとんど『Fundamentals of Data Engineering』に書いてあります。これを読んで実践していくだけで、防げる悲劇は数多くあります。2024年3月27日に日本語版も出版されるため、是非皆さんにも読んで欲しいと思います。
2つ目の選定ポイントは、データ基盤内部で利用している他の技術との相性の良し悪しについての指標である、相互運用性(インターオペレータビリティ)です。トランスフォーメーションの段階で使っているツールとの相性について考慮する必要があります。dbtとのDagsterの相性は非常に良く、Dagsterの利用者の半分がdbtを使っているほどです。
次に、DWHとの相性について考慮する必要があります。基本的にはBigQueryかSnowflakeの2択だと思います。
また、利用しているクラウドとの相性も考慮する必要があります。クラウドの制限で使えないケースもあります。
3つ目の選定ポイントは、Speed to Marketです。これは、フィードバックループを回すスピードの速さを指しています。オーケストレーションツールは開発フローの速度に与える影響が非常に大きく、開発フローのシンプルさや開発者体験にダイレクトに影響します。
4つ目の選定ポイントは、Team Size and Capabilitiesです。これは、そのテクノロジーが現在のチームの能力で使えるかどうかを指します。ツールを利用するメンバーの習熟度や学習意欲、メンバーが運用に割ける労力を考慮します。
5つ目の選定ポイントは、運用のしやすさです。データは、バグだらけの現実世界を映しているため、その現実世界をモデル化したオーケストレーションも失敗を起こします。そのため、異常状態から正常状態に戻すまでのスピード感がオーケストレーションツールに求められます。異常発生の検知の方法や異常終了した箇所を部分復旧する方法が重要です。」
Dagster Cloudは全ての観点において優れていた
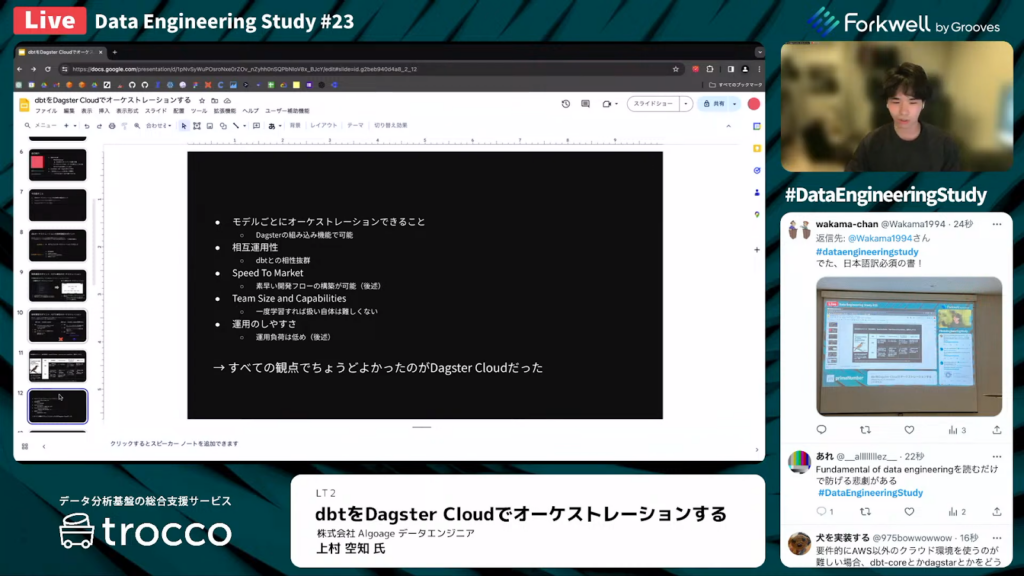
上村氏:「技術選定のポイントを再度まとめます。
- モデルごとにオーケストレーションできる点
- 相互運用性
- Speed to Market
- Team Size and Capabilities
- 運用のしやすさ
この5つの観点を考慮して、全てが適切だと思ったツールがDagster Cloudだったため、このツールを利用していくことにしました。」
つづいて、Dagster Cloudでdbtを運用するメリットについてお話していただきました。
サーバレスな環境構築が可能
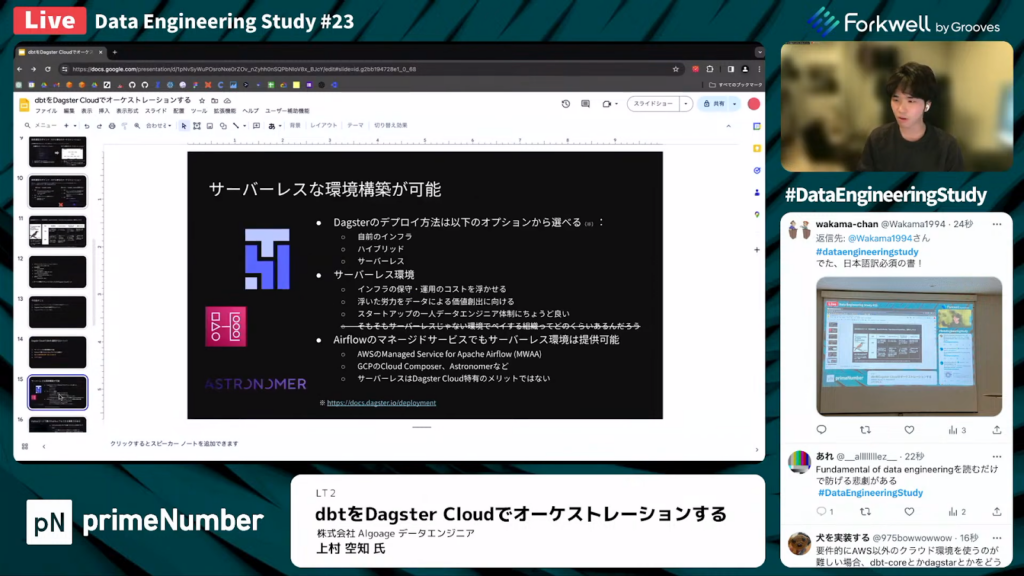
上村氏:「1つ目のメリットは、サーバーレスな環境構築が可能である点です。
Dagsterはデプロイ方法を、自前のインフラ・ハイブリッド・サーバーレスの3つから選びます。
1人のエンジニア体制や労力が足りない体制だと、サーバーレス環境は非常に魅力的です。インフラの保守とか運用のコストを浮かせて、浮いた労力をデータによる価値創出に向けられる点がサーバーレスのメリットです。
しかし、サーバーレス環境はAirflowでも提供できるため、これはDagster Cloudのみの特長ではありません。」
Pythonコードで書ければ何でもできる柔軟さがある
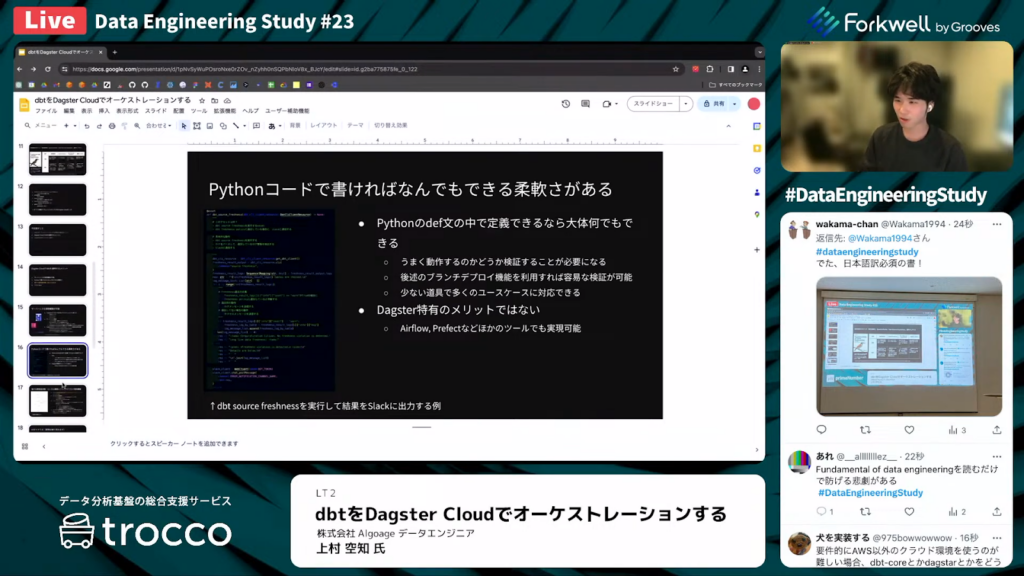
上村氏:「2つ目のメリットとして、Pythonコードで書ければ何でもできる柔軟さがあります。Pythonのdef文の中で定義できるのであれば、大体のことは実現できます。
スライドの左側に書いてあるコードは『dbt source freshness』と呼ばれる、このデータソースが最新のものであるかをチェックし、その結果の良し悪しをSlackに出力させる仕組みです。
当然、そのジョブが本当にうまく動作するのかどうかを検証する必要がありますが、後述のブランチデプロイ機能を利用すれば検証が可能です。
つまり、少ない道具でさまざまなユースケースに対応できます。ただ、こちらもAirflowやPrefectなどの他のツールでも実現できるため、Dagster Cloud特有のメリットではありません。」
強力な開発者体験:ローカル開発とブランチデプロイ環境構築
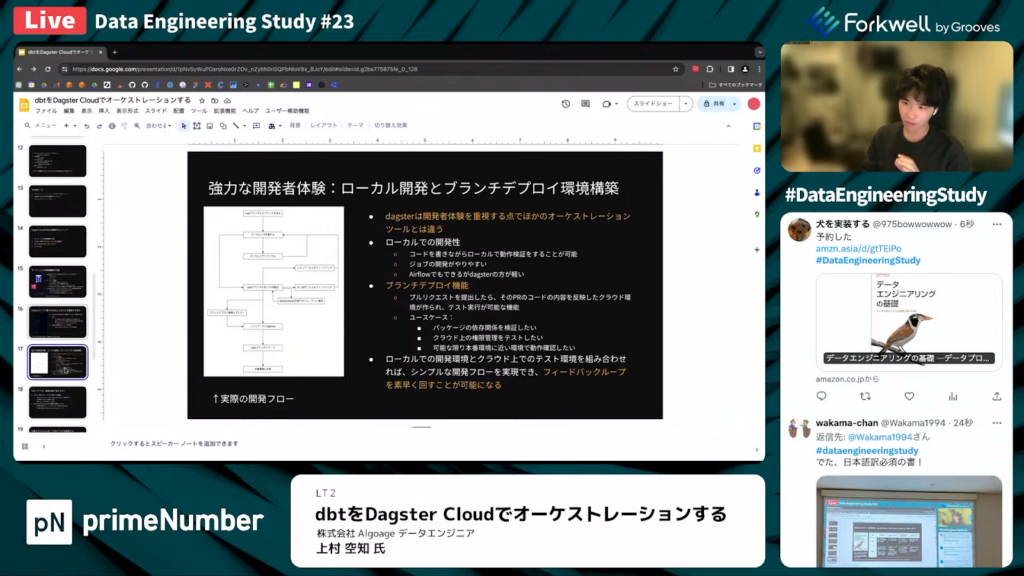
上村氏:「他のオーケストレーションツールにはないDagster特有のメリットは、開発者体験だと思います。まず、ローカルでの開発性が非常に高く、コードを書きながらローカルでジョブの開発ができます。
AirflowのAWSのマネージド版のサービスにて、Dockerイメージが公開されているため、ローカルでの開発はAirflowでもできますが、Dagsterの方が圧倒的に軽いです。
また、ブランチデプロイ機能と呼ばれる機能により、プルリクエストを提出したらそのPRの内容を反映したクラウド環境が作られて、テスト実行もできます。定期実行以外は全てできる点が魅力的です。
ユースケースとしては、パッケージの依存関係の検証やクラウド上の権限管理が挙げられます。可能な限り本番環境と近い環境で動作確認をしたい場合に、ブランチデプロイ機能は非常に役立ちます。とくに、オーケストレーションツールはパッケージの依存関係が非常に厳しいため、その検証をブランチデプロイで瞬時にできる点は本当に素晴らしいと思います。
Dagsterでは、ローカルでの開発環境とクラウド上でのテスト環境を組み合わせることで、シンプルな開発フローを実現でき、フィードバックループを素早く回せます。これは、その他のツールにはない特徴であり、実際AirflowはMWAの環境構築に30分ほどかかってしまいます。」
Dagsterの優れたUI
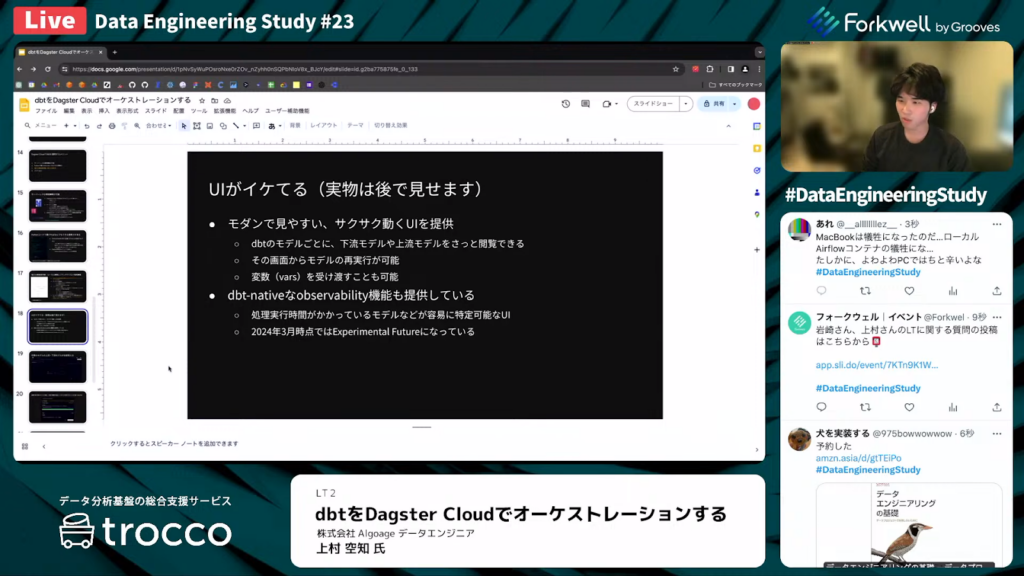
上村氏:「4つ目のメリットとして、UIが優れています。モダンで見やすく、サクサク動くUIが提供されています。
また、dbt-nativeなobservabilityの機能も提供していて、処理実行に時間がかかっているモデルの特定が容易に行えます。現段階ではExperimental Futureになっています。」
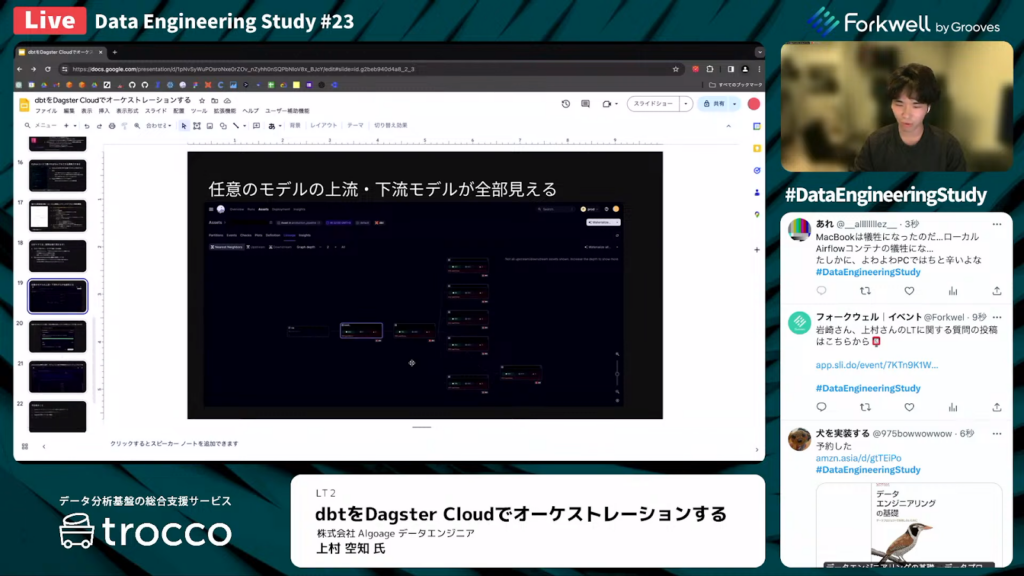
上村氏:「実際のモデル名は隠していますが、このように任意のモデルの上流・下流が見れます。」
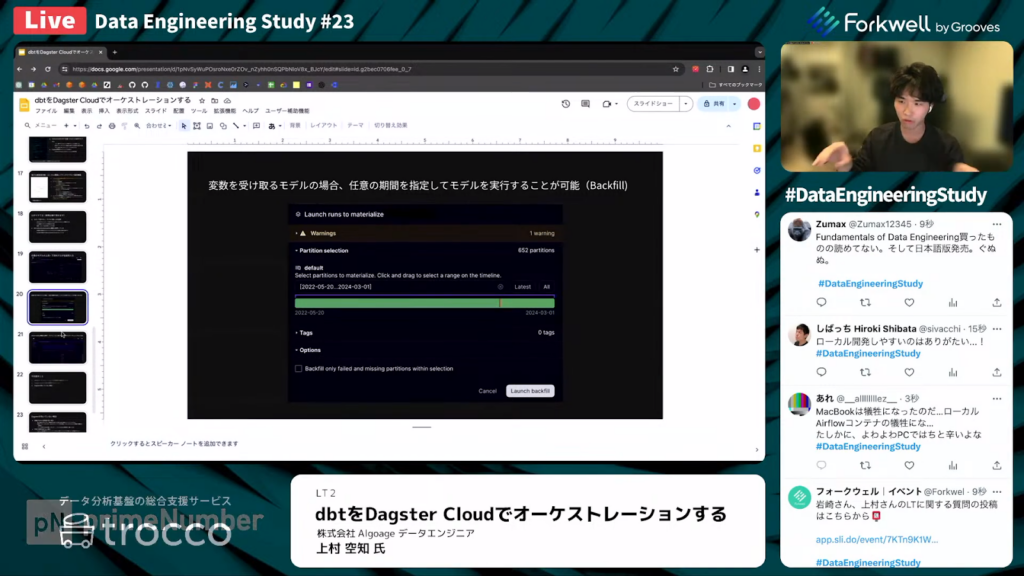
上村氏:「変数を受け取るモデルの場合、ある一定の期間にわたって連続的にインクリメンタルモデルを実行できます。いわゆるバックフィルです。」
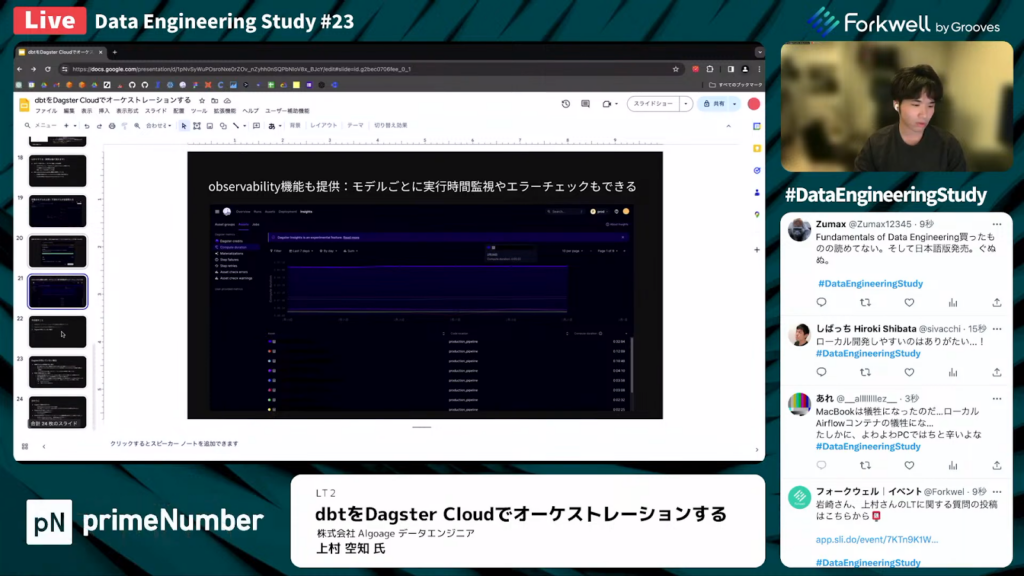
上村氏:「dbt-nativeなobservability機能です。モデルごとの実行時間監視やエラーチェックができます。」
さいごに、Dagsterが向いていないケースについてお話していただきました。
Dagsterが向いていないケース
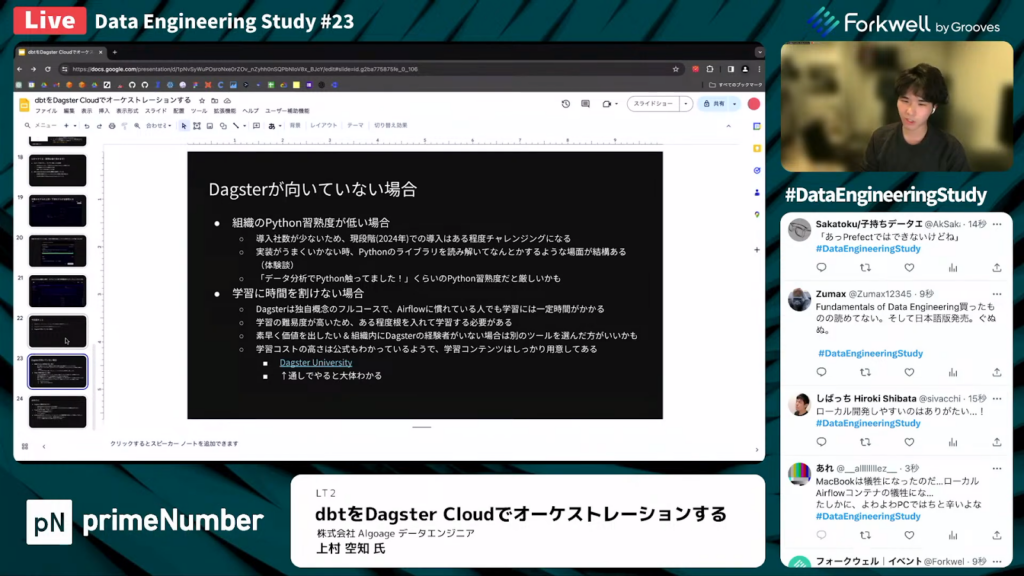
上村氏:「実際、Dagsterが向いてないケースもあります。
たとえば、組織のPythonの習熟度が低い場合は向いていません。現段階(2024年)での導入はある程度チャレンジングになる認識があります。実装がうまくいかない時に、Pythonのライブラリを読み解いて何とかする場面が多くありました。そのため、データ分析でPythonを触っていた程度の習熟度だと厳しい印象です。
また、学習に時間を割けない場合もDagsterは向いていません。Dagsterは独自概念のフルコースであるため、基本的にはAirflowに慣れている人でも、学習には一定の時間がかかります。ただ、学習のコストの高さは公式も分かっているようで、Dagster Universityと呼ばれる学習コンテンツがあります。こちらを通してやっていただくと、大体は分かるようになります。」
おわりに
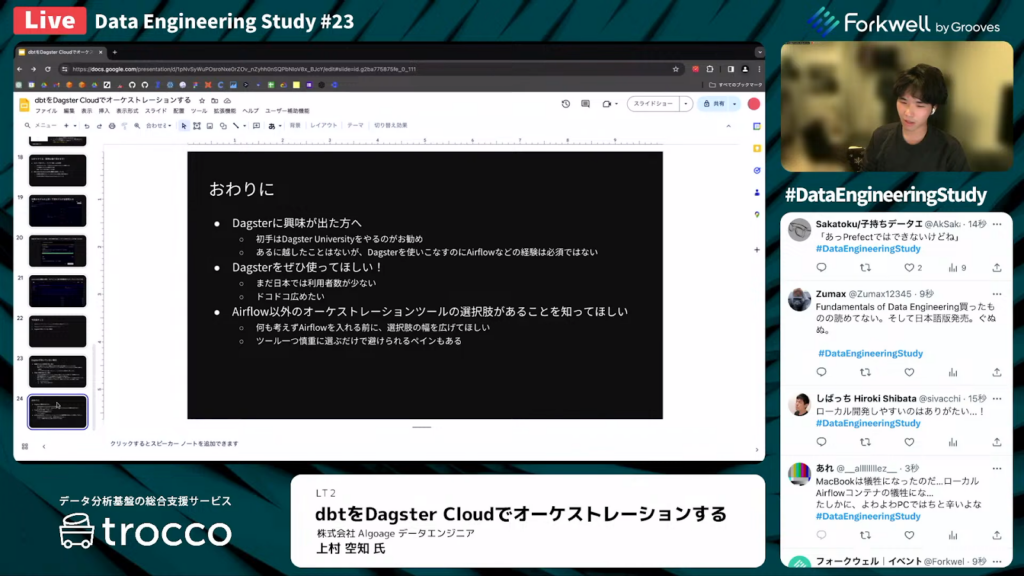
上村氏:「今回の話を聞いて、Dagsterに興味が出てきた方は、まずはじめにDagster Universityをやっておくのがおすすめです。ベストプラクティスやフォルダ構成などについても分かるようになります。Airflowの経験はいらないでしょう。
個人的に、Dagsterは日本でより広まって欲しいと思っています。
また、先ほど長江さんも言っていた通り、何も考えずに人気なAirflowをとりあえず導入するのは避けた方がよいと思います。他にもオーケストレーションツールは数多くあるため、選択肢の幅はできるだけ広げて、しっかりとユースケースを確認しておくべきだと思います。
所詮、一つのデータ基盤を構成するただのツールだと思うかもしれませんが、ツール一つを慎重に選ぶだけで、避けられるペインもあります。『たかがツール、されどツール』で、計画的にご利用していただけるとよいと思います。」
過去のData Engineering Studyのアーカイブ動画
Data Engineering Studyはデータエンジニア・データアナリストを中心としたデータに関わるすべての人に向けた勉強会を実施しております。
当日ライブ配信では、リアルタイムでいただいた質疑応答をしながらワイワイ楽しんでデータについて学んでおります。
過去のアーカイブもYouTube上にございます。興味をお持ちの方はぜひご覧ください。
https://www.youtube.com/@dataengineeringstudy6866/featured
TROCCO®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。データの連携・整備・運用を効率的に進めていきたいとお考えの方や、プロダクトにご興味のある方はぜひ資料をご請求ください。






