
第21回では「Azureのデータ分析サービスの現在と未来」と題して、日本マイクロソフト株式会社の武田雅生氏と中里浩之氏に、Microsoft Azureが提供しているサービスの概要・特徴についてお話していただきました。また、Azure OpenAIベースのAI Copilotを導入した「Microsoft Fabric」の概要と特徴についてもご紹介していただきました。
今回の勉強会では、「5社のデータエンジニアが振り返る」と題して、データエンジニアリングやデータ分析基盤に関する「良かったこと・問題だったこと・来年トライしたいこと」などを5名の方々にLT形式でご発表していただきます。
当日の発表内容はこちら
LT1「生データを最速で取り込むチャレンジ~LayerXデータ基盤成長物語part1~」
中山 貴博(civitaspo)氏
株式会社LayerX データエンジニア
Ubie株式会社を退職後、株式会社LayerXのバクラク事業部 Platform Engineering部にて、DevOpsグループ マネージャーとProduct Securtyグループを担当。また、機械学習・データ部 データグループやCTO室も兼任。
バクラクシリーズラインナップ

中山氏:「LayerXはバクラクと呼ばれるサービスを提供しております。バクラクには、現在5つのプロダクトがあります。」
バクラクの特徴
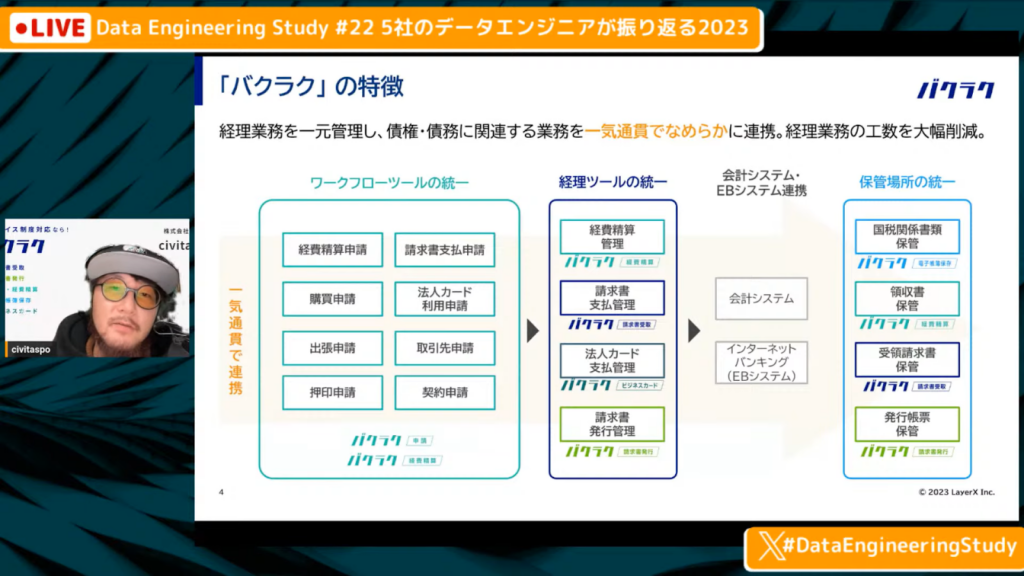
中山氏:「バクラクは、経理業務を一元管理し、債券・債務に関する業務を一気通貫でなめらかに連携します。経費精算の際、領収書の写真を撮ってアップロードする業務を行っている方がいると思いますが、そういった業務において、埋まっていて欲しい項目を勝手に埋めてくれるのが特徴です。
意識しないところに優しさがある、そのようなサービスを提供しています。」
今回のLTの題材

中山氏:「バクラクはサービス提供基盤として、AWSを利用しています。一方、分析基盤にはBigQueryなのですが、BigQueryで分析するためにはデータをAWSから移す必要があります。
そのため今回は、このデータ転送をリアルタイム・ニアリアルタイムで実現する手法をいくつか紹介します。」
生データの取り込みは依然として難易度が高い

中山氏:「『今更データ転送の話?』『生データの取り込みなんてもうすでにコモディティ化しているのでは?』といったことを考える人がいると思います。
確かにそうです。私もEmbulkに関わってきたため、それなりにコモディティ化していることを知っています。一方で、リアルタイム・ニアリアルタイムとなると、まだ難易度が高い状況だと思っています。
また、セキュリティを意識すると選択肢がさらに狭まります。
たとえば、OIDC接続の徹底や、踏み台サーバーを許さないといったケースがあります。ほかにも、BigQueryなどと接続する時に『クレデンシャルのJSONを発行しているか』や、発行しているにしても『ローテーションをしているか』なども問題になります。
業務そのものが面倒であるため、1つのサービスアカウントに強い権限を持たせているケースもあると思います。これらを意識し始めると、選択肢がさらに狭まるのです。
データ量やデータソースの種類によると思いますが、SaaSを利用するとなるとコストを無視できなくなります。私は予算が決まっているのであれば、BIツールに投資した方が事業をドライブできると考えています。もちろん、TROCCO®などのSaaSは良い製品だと思っていますが、私たちはBIツールに投資する決定をしました。
以上より、リスクやコスト、サービスレベルのコントロールを考え、現在生データを取り込む部分を自作しています。」
想定視聴者と得られるもの

中山氏:「バクラクと同様にサービス提供環境をAWS、データ基盤はGCPと呼ばれる構成をにしている会社に所属している方が、データ転送に関して何か良いインサイトが得られると良いなと思っています。」
つづいて、バクラクデータ基盤の歴史についてお話していただきました。
2022年4月時点での分析環境
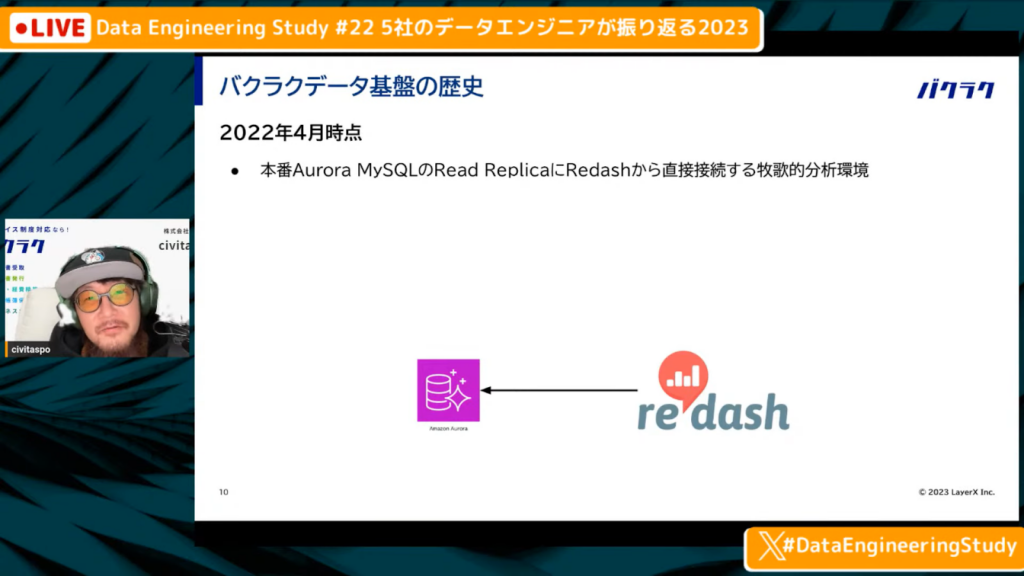
中山氏:「去年の4月は、本番Aurora MySQLのRead ReplicaにRedashから直接接続する、非常に牧歌的な分析環境でした。」
2023年4月時点での分析環境
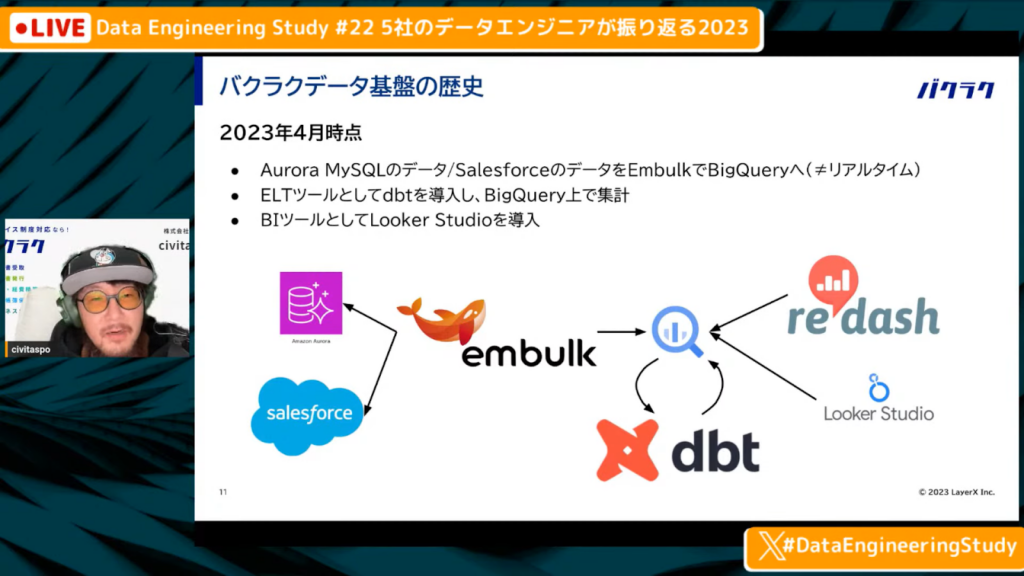
中山氏:「とはいえ、今年の4月にはよくある形のミニマルデータ基盤になりました。Aurora MySQLやSalesforce、HubSpotなどのデータをEmbulkで吸い出してBigQueryに格納し、ELTツールとしてdbtを導入してRedashやLooker Studioで可視化する流れです。」
2023年12月時点での分析環境
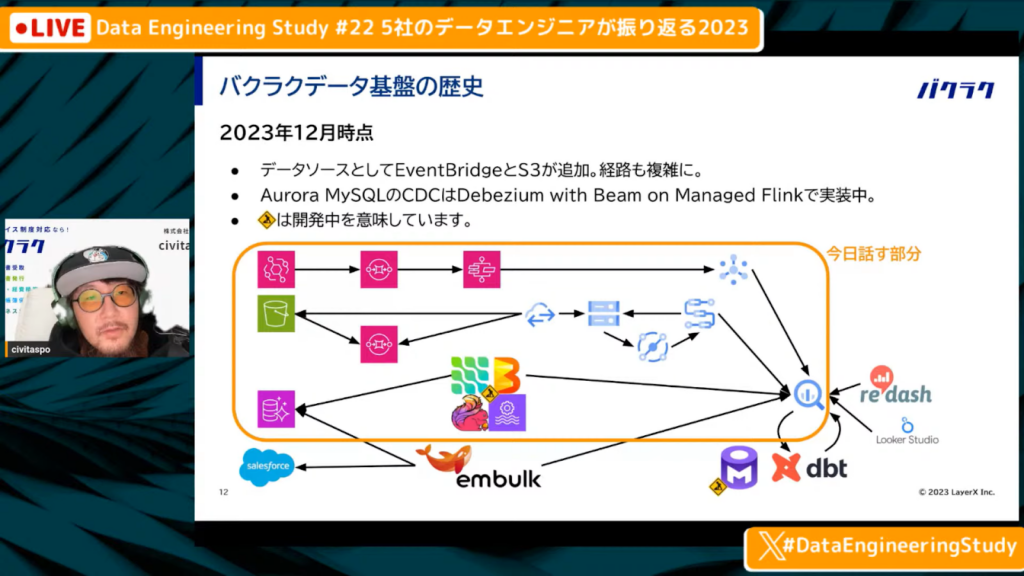
中山氏:「2023年12月時点では、さまざまな経路が増え、複雑になりました。データソースとしてEventBridgeやS3が追加されました。
MySQLのデータに関しても、Embulkのバッチ処理で持っていくのではなく、Debezium with Beam on Flinkを使ったCDCを現在実装中です。工事マークがついているのはアンダーコンストラクションですが、実装しようとしています。右下にOpen Metadataも記載されていますが、Open Metadataも現在作っています。
今回は、増えた3経路について発表していこうと思います。」
EventBridge→Cloud Pub/Sub→BigQueryの構成
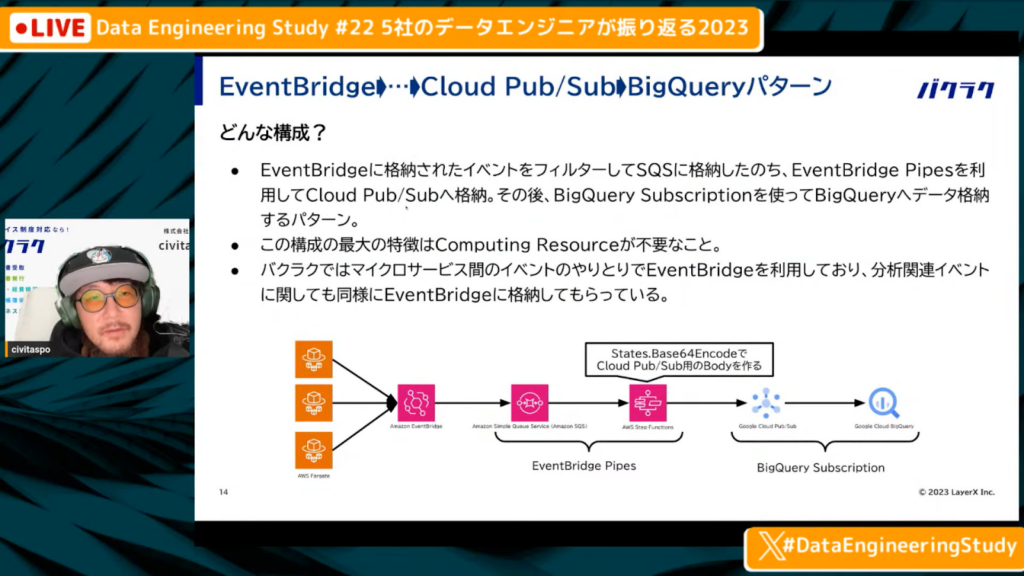
中山氏:「1つめは、EventBridge→Cloud Pub/Sub→BigQueryの経路です。EventBridgeに格納されたイベントをフィルターしてSQSに格納したのち、EventBridge Pipesと呼ばれるAWSのサービスを使って、AWS Step FunctionsのExpressワークフローを立ち上げます。そこから、Cloud Pub/SubのAPIを直叩きして、Cloud Pub/Subに格納された後はBigQuery SubscriptionでBigQueryに投入します。
最大の特徴は、Computing Resourceが不要である点です。
現在バクラクではマイクロサービス間のイベントのやりとりでEventBridgeを利用しており、そのイベントをインターセプトしたり、分析関連イベントに関しても、分析用のログとしてEventBridgeに格納したりしてもらっています。
大体、格納してから30秒、長くても1分ぐらいでBigQueryで見られるようになるデータ設計になっております。」
EventBridge→Cloud Pub/Sub→BigQueryのメリット

中山氏:「Computing Resourceがないのはもちろん嬉しいのですが、EventBridgeのイベントをBigQueryで見られる点が非常に良かったなと思っています。EventBridgeはさまざまなSaaSと連携できます。
SalesforceやKARTEなど、パートナーとして登録されているサービスはSaaSの変更イベントを受け取って分析できるようになります。
また、AWSでいくつかテンプレートを用意してくれており、自前でイベントを受け付けるエンドポイントを書くことも簡単です。GitHubのイベントを受け付けてFour Keys分析したいといった要望もWebhookを受け付けるエンドポイントをテンプレートに沿って実装するだけで対応できます。」
EventBridge→Cloud Pub/Sub→BigQueryの注意点

中山氏:「Computing Resourceレスにこだわった結果、Step FunctionsのStates.Base64Encodeという組み込み関数の処理できる量が小さいです。そのため、大きなデータ(横長のデータ)を取り扱う場合は、AWS Lambdaや後述のBeamなどを使ってもらうといいと思います。」
S3→GCS→Cloud Workflows→BigQueryの構成
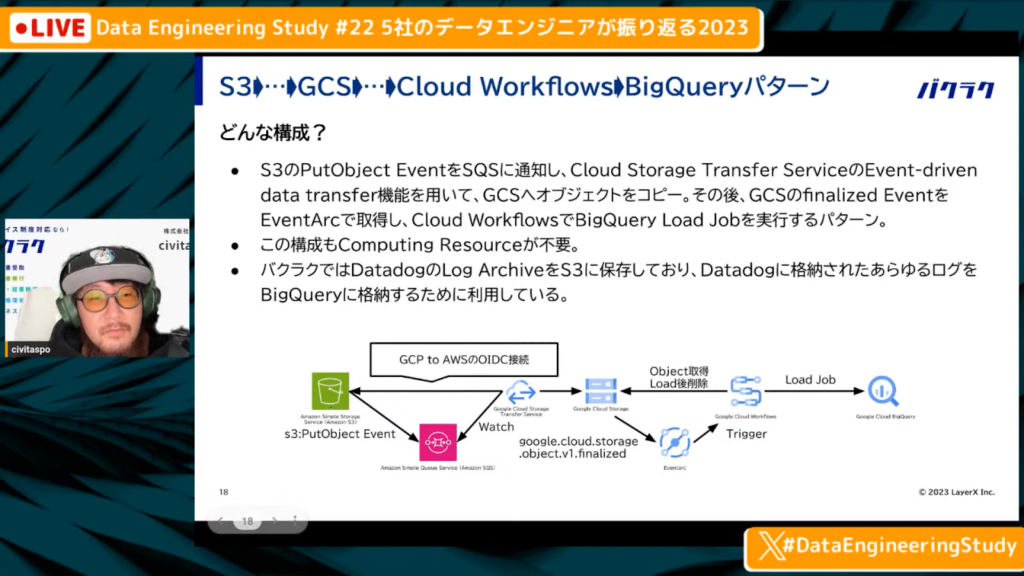
中山氏:「まず、S3にオブジェクトをプPutします。PutしたらPut event S3 notificationでSQSに飛ばして、そのSQSをGCPのCloud Storage Transfer ServiceのEvent-driven data transferと呼ばれる機能を用い、GCSへオブジェクトをコピーします。この機能はSQSをウォッチしてS3にオブジェクトが置かれた瞬間、コピーしてGCSに持っていきます。GCSにオブジェクトを置いたら、そのfinalized EventをEventArc経由でCloud Workflowsに伝えて、Cloud WorkflowsでオブジェクトをBigQuery Load Jobを実行するパターンです。
この構成もComputing Resourceが不要です。バクラクの場合は、DatadogのLog ArchiveをS3に保存しており、保存したLog ArchiveをBigQueryに格納するために使っています。DatadogのLog ArchiveはGCSとS3の両方に書き込むことができないため、このような構成を取っています。
また、AWSが提供しているDatabase Migration Serviceを使うと、データベースのCGCの情報をS3に置けるため、そういったケースにも使えるかなと思っています。」
S3→GCS→Cloud Workflows→BigQueryのメリット

中山氏:「S3にオブジェクトをPutしてから1分以内の速さでBigQueryにデータを格納でき、さらに非常に安く実現できます。
この構成でコストがかかるのは、S3のインターネットアウトとCloud Workflowsのみです。S3のインターネットアウトはどのような手法をとってもかかるため割愛します。Cloud Workflowsは大体1オブジェクトあたり3Steps程度必要であるため、仮に10万オブジェクトを送ったとしても、$3程度の安さです。
BigQueryへのLoadなどは基本的に無料のオペレーションのため安価です。」
S3→GCS→Cloud Workflows→BigQueryの注意点
中山氏:「当然ですが、BigQuery Load Jobやテーブルごとに1日あたりの上限があるため、その上限を超えないようにデータ転送を設計しましょう。」
Debezium with Beam on Managed Flinkの構成

中山氏:「Debezium with Beam on Managed Flinkパターンの構成は、Apache BeamのI/O ConectorとしてDebeziumを使用し、BigQueryにデータ格納するパターンです。
Debeziumを運用しようとすると、Debezium ServerやKafka/Kafka Connectの運用が不要になります。代わりに、Amazon Managed Service for Apacheの運用が必要になります。
『運用対象がずれただけでは?』と思う方がいらっしゃるかもしれませんが、CDCのデータをBeamを使ってさまざまなところに伝播できるレポーティングデータベースのように、BigQueryのみならずサービスが使うデータベースやMLが使うデータベースなどにも転送できるようになります。そのため、単純にDebeziumを運用するよりも非常に汎用性の高いソリューションになります。
現在Under Constructionのため、詳細は割愛します。」
より一層事業貢献ができるデータ組織へ

中山氏:「今回話した内容はデータエンジニアリング関連であるため、事業と直結しているように見えないと思いますが、実際にはデータを使って事業に活かさなければ意味がないです。そういった部分まで含めて、対応できる人材を募集しております。」
LT2「2023サンフランシスコ出張報告 〜ダッシュボードが自動生成される時代に、データ人材に求められる働き方を考える〜」
ゆずたそ氏
合同会社風音屋 代表
個人開発のWebサービスがGigazineに掲載。PyConJPやDevelopersSummitでベストスピーカーを受賞。日経産業新聞1面やForbesJapanに取材掲載。著書に『個人開発をはじめよう!』『実践的データ基盤への処方箋』『データマネジメントが30分でわかる本』など。
2023年を代表するテクノロジー
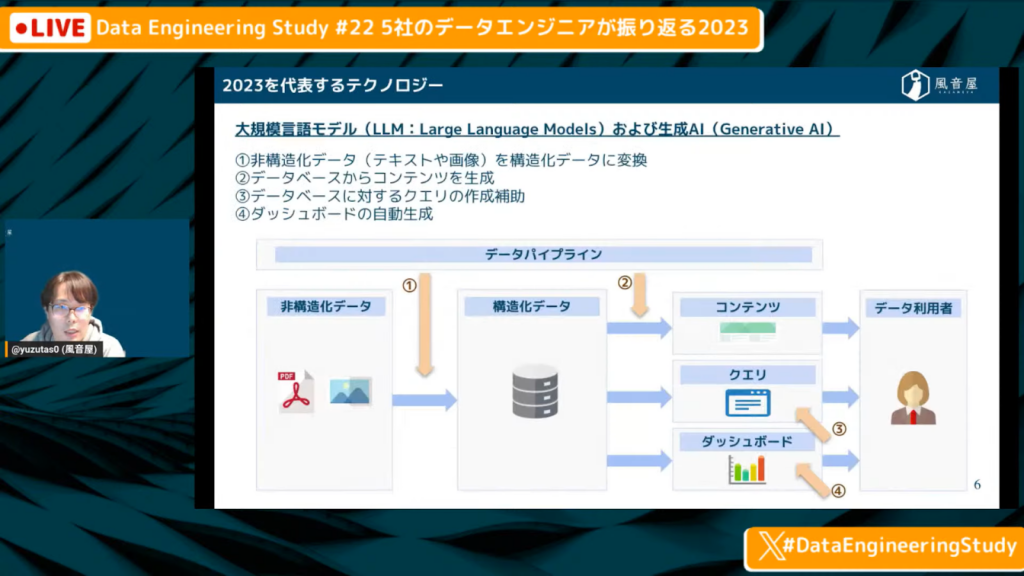
ゆずたそ氏:「今回のテーマである、2023年のデータエンジニアリングと自社の取り組みの振り返りにあたって無視できないことは、やはりLLM(Large Language Models)と生成AIだと思っています。
データエンジニアリングの分野においは、
- 非構造化データ(テキストや画像)を構造化データに変換
- データベースからコンテンツを生成
- データベースに対するクエリの作成補助
- ダッシュボードの自動生成
LLMと生成AIが利用されるケースは、以上の4つがあると思います。」
非構造化を構造化データに変換
ゆずたそ氏:「テキストや画像などのデータをLLMに読ませて、商品名から商品の分類を作るカテゴリー判定や、犬の写真から『この写真には犬がいる』といったラベルをつけるなど、構造化データに変換する部分で使えると思います。
これについては、今年4月の風音屋の勉強会や5月のGoogleのイベントでこれらの事例をいくつか紹介しているため、省略します。是非そちらも見てください。
ただ今年の前半と後半で違うのは、今年の後半では各データウェアハウスでSQLを使ってGenAIを実行できるとアナウンスされ、データパイプラインに乗せやすくなったことです。
これまではGPTのAPI経由でしかできませんでしたが、SQLで実行できるようになってきたため、より一層やりやすくなるはずです。」
データベースからコンテンツを生成
ゆずたそ氏:「2つ目は、(データベースから)コンテンツを作る部分です。これはウェブページ作ったり社内向けの通知を作ったり、人によってはYouTube動画の台本を作ったりバナー広告の画像を作ったり、さまざまなコンテンツを作ったりする機能があります。
ただ今の段階では、PoC段階やデータウェアハウスを使っていない取り組みの方が多いようです。技術的には、dbtからSQL経由でLLMを使ってテキストを大量生成することは既に可能であるため、おそらく来年以降に事例が増えるのではないかと思います。」
データベースに対するクエリの作成補助

ゆずたそ氏:「3つ目は、データベースに対するクエリの作成補助です。こちらは、データ分野に限らずかなり前からまGitHub CopilotやChat GPTのCode Interpreterなど、さまざまな商用製品が出ています。
データ分野に特化すると、Snowflake Copilotなど各ベンダーが補助機能の提供を発表しています。風音屋のクライアントの例ですと、SlackBotでデータ利用者の問い合わせに対応したり、SQLの作成を補助する独自ツールを社内で提供したりしている事例が今年は出てきました。」
ダッシュボードを自動生成する
ゆずたそ氏:「さまざまな用途がある中で、今回のメインテーマはダッシュボードの自動生成です。4つの用途の中でも、ダッシュボードの自動生成はインパクトが大きいと思います。」
サンフランシスコ出張報告
ゆずたそ氏:「Google Cloud NEXTと呼ばれるイベントに合わせて、サンフランシスコに社員3名と出張に行ってきました。その時の出張報告はブログに書いているため、もしよろしければご覧ください。」
Google Cloud NEXTとは

ゆずたそ氏:「Google Cloud NEXTとは、年に1回Google Cloudが開催しているテクノロジーカンファレンスです。」
データエンジニアリング分野のセッションが多々開催

ゆずたそ氏:「データエンジニアリングはやはり非常にホットな分野であるため、さまざまなセッションが開催されていました。」
最大のインパクト

ゆずたそ氏:「その中でも1番インパクトがあったのは、やはり10秒でダッシュボードを作れるようになったことです。製品のデモとは分かっていましたが、それでも感動したのが正直な気持ちです。」
Duet AI for Looker StudioPro
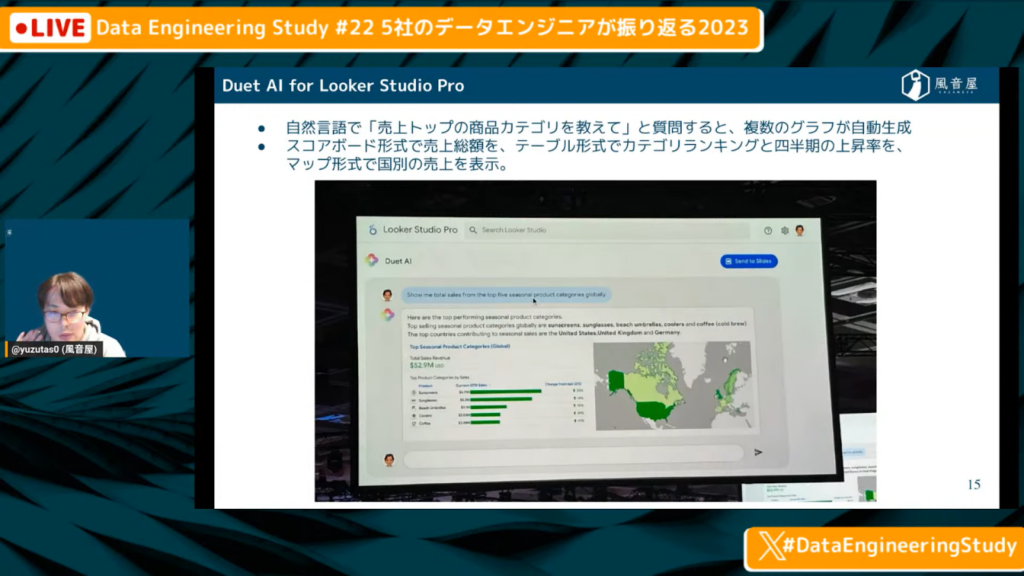
ゆずたそ氏:「たとえば、Duet AI for Looker StudioProと呼ばれる自然言語で『売上トップの商品カテゴリーを教えて』と質問すると、複数のグラフが自動生成されます。
スコアボード形式で売上の総額を出したり、テーブル形式でカテゴリーのランキングや四半期の上昇率を出したり、地図で国別の売上を表示したりできます。」
Duet AI for Looker
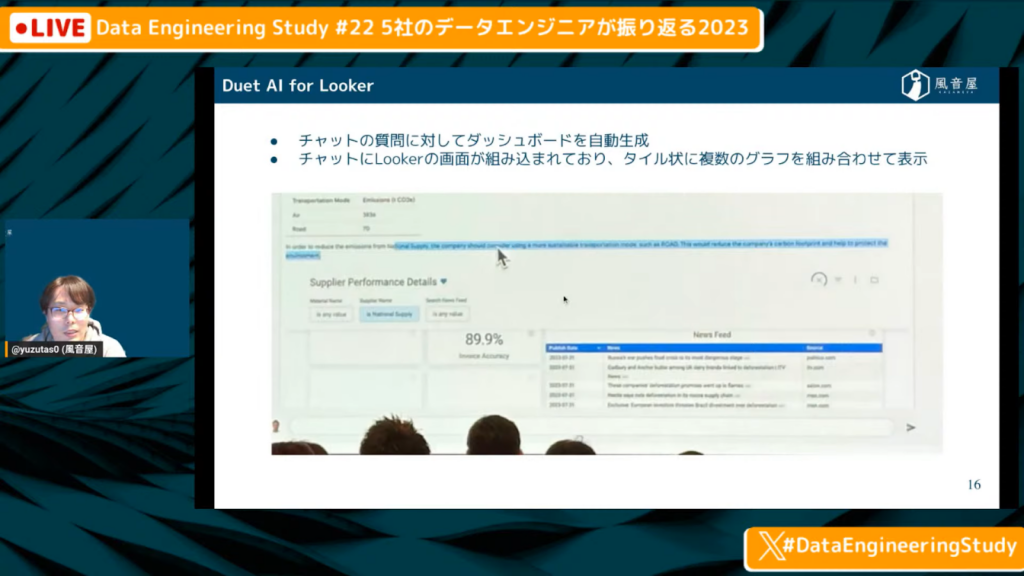
ゆずたそ氏:「Duet AI for Lookerでは、チャットの質問に対してダッシュボードを自動生成できます。また、チャットに(Lookerの)画面が組み込まれており、タイル状に複数のグラフを表示できます。」
Amazon Q in Quick Sight

ゆずたそ氏:「Google Cloudに限らずいうと、似たようなものは各ベンダーが提供していています。たとえば2週間ほど前にAWSのre:Inventにおいて、BIツールのQuick Sightで同じような機能が紹介されていました。そのため、基本的にBIツールは、今後こういった機能が増えていく未来があるのかなと思います。」
現地でデモを見たり関係者と話したりした所感

ゆずたそ氏:「実際に現地行ってデモを見たり関係者と話したりした感想として、個人的な意見ですが、おそらくChatGPTよりイラストAIを想像してもらった方が感覚を掴めるのではないかと思っています。」
現時点でのイラストAIのFit&Gap

ゆずたそ氏:「現時点でイラストAIにどのような特徴があるかというと、マッチするケースとアンマッチなケースが露骨にあるようですと思います。これはおそらく、ダッシュボード生成AIも同じではないかと思っています。
アンマッチなケースとして、イラストAIはイラストを自由自在に描ける人からすると、『痒いところに手が届かない』『手直しで余計に時間かかる』といった点がありますると思います。
たとえば、人気ゲームのパッケージイラストであれば、書き下ろしの方がマッチするはずですするかなと思います。ゲームをクリアして初めて、『こういった意図があったんだな』『こういった仕掛けがあったんだな』と感じられる渾身の1枚の方がファンの方は感動するでしょう。
イラストAIがマッチするケースとしては、私のように自力でイラストを描けない人からすると、ブログの見出しやLINEやSlackのアイコンを作る際、非常に便利です。自分の好みのテイストにあった学習モデルを選び、プロンプトを調整しながら画像をひたすら作成し、最後にベストショットを選別すれば終了です。」
イラストAIから予想しうるGenerative BIのアンマッチなケース

ゆずたそ氏:「イラストAIと同じく、Generative BIによってダッシュボードを自動で作る際にも、アンマッチなケースは明確にありますあると思います。
一流データアナリストの100点を再現するツールではないでしょう。今のところ、せいぜい50点しか取れないのではないかと思っています。
そのため、クリティカルな業務ではハイスキルな人材をアサインした方が良いでしょう。たとえば、以下のような業務はGenerative BIは不向きです。
- コアとなる経営指標の設計
- プロダクトのグロース戦略に関わる根幹のモニタリング
- IRで投資家に対して開示するデータの取得
- 部署横断で共通指標として管理・定義すべきデータ
- データモデリングが必要になる部分
- データの仕様や歴史的経緯が複雑で、要件定義・テスト設計や複数人レビューが必要となる分析
ビジネスの意思決定においては、『自動生成されたものを使います』といった思考放棄が許されず、根拠に基づいた説明・ブラッシュアップが必要になる場面は多々あると思います。そのため、(そういったケースには)自動生成はあまりマッチしないです。
ただ、ツールを使えるだけ、データを取れるだけのジュニア人材だと、クリティカルな業務での活躍は難しいため、これまで以上にプロフェッショナルなシニア人材に需要が偏ってくるかなと思います。」
イラストAIから予想しうるGenerative BIのマッチするケース

ゆずたそ氏:「ただ、『10秒で50点のダッシュボードを作れる』ことは、非常に革命的なUXですだと思います。当然GenBIが社内のデータを参照しやすいように、データを一元管理したりメタデータを整備したりする必要はありますが、それを差し引いても革命的だと思います。
実際、ちょっとしたビジネス施策のモニタリング程度であれば、50点のダッシュボードで問題ないケースも多々あるはずですと思います。ジュニアのデータアナリストの成果物だと、50点に満たないケースも多いのではないかと思います。それで今の仕事は回っている現場も数多くあるでしょう。
反対に、優秀な人が100点のクオリティで分析しても、そこまでしなくてもよいケースもあると思います。また、100点ではないからこそ気軽に作って、気軽に壊せたり起動修正しやすかったりするケースがあります。
依頼者からすると、データ専門職に仕事をお願いして1週間待つよりも、手元で10秒で作れて格安でPDCAサイクルを回せるため、仕事の仕方が変わってくるでしょう。データを見ることはあくまで手段でしかないため、課題を発見して改善するサイクルを回すところに、よりビジネスユーザーがコミットしやすくなると思います。
したがって、データ利用者の裾野が広がっていき、より多くの人がデータ活用をしやすくなると思います。」
キャリアの方向性①:王道プラン

ゆずたそ氏:「ダッシュボードが10秒で作れる時代が来るかもしれない中で、データエンジニアリングの専門会である風音屋にとっては死活問題です。データ分析人材のキャリアの方向性として、どうすれば今後も生き残れるのかを考えました。
1つ目は王道プランです。これは、分析のスキルを愚直に伸ばすプランです。たとえば、計量経済学と呼ばれる分野の論文を書いて一定の評価をされる人は、ある程度データ分析の人材として強いでしょう。
風音屋で試したこととしては、まず私が東京大学の研究員に就任しました。民間企業のデータを使って論文を執筆し、内閣府『経済分析』と呼ばれる雑誌に投稿しました。また、民間企業のデータを使って、東大生の学部生向けにデータ分析の授業を行いました。そして風音屋のメンバーが20%ルールで大学院に通えるような支援を提供しました。」
キャリアの方向性②:分析特化プラン
ゆずたそ氏:「2つ目は特定の産業や分野に特化して生き残るプランです。
たとえば、製造業のデータマネジメントや人事など個人情報を扱うデータ分析、月面データのデータの位置情報のエンジニアリングなどです。月は地球外であるため、移動軽度やIPアドレスがそのまま使えない中で、位置情報をどのようにデータ処理するのかがコモディティ化していないと思います。
風音屋で試したこととしては、弊社はクライアントワークであるため、短期期間でドメイン知識を叩き込むメソッドを開拓したり、メンバーが『これが自分の武器です』と言えるようにスキル向上を追求できる目標管理のシートや人事評価の作り方などを検討しました。
『いかにその分野に詳しくなるか』『詳しくなるための工夫ができるか』といった仕組みづくりを検討し、試しました。」
キャリアの方向性③:上流工程プラン
ゆずたそ氏:「3つ目は上流工程プランです。これは、データ抽出・集計やダッシュボードの構築だけではなく、より上流のビジネスやプロダクト戦略を作るところまで染み出していくものプランです。
今年風音屋で試したこととしては、クライアント企業の執行役員と一緒にグロースサイクルを描いてプロダクトの成長戦略を模索したり、中途採用したメンバーが入社10日で経営陣に対して分析結果を報告したりしました。」
キャリアの方向性④:活用支援プラン
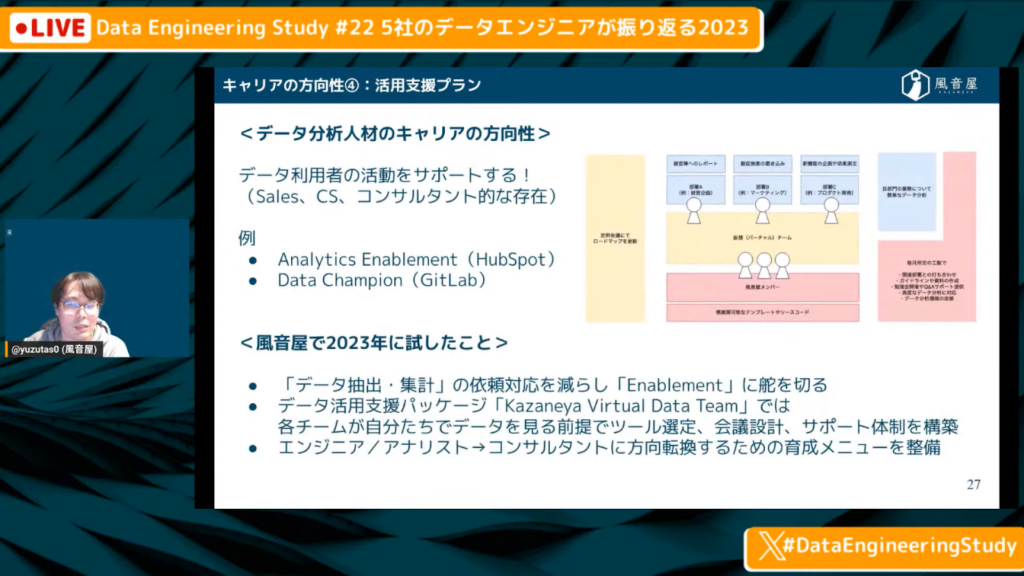
ゆずたそ氏:「4つ目は活用支援プランです。すでに、さまざまな人たちがデータを使っていく未来は見えているでしょう。そういった時に、その人たちの活動をサポートする、セールスやカスタマーサポート、コンサルタントのような動き方ができるのではないかと考えています。
たとえば、HubSpotだとAnalytics Enablementと呼ばれるポジションがあったり、GitHubだとData Campionと呼ばれる位置付けがあったりします。このようなノウハウが公開されているため、同じようなことができるのではないかと思っています。
風音屋で試したこととしては、データ抽出・集計の依頼を減らしてEnablementの方に少し舵を切りました。また最近公開した支援パッケージでは、各ビジネスの担当者たちが自分でデータを見る前提で、ツール選定や会議設計、サポート体制の構築を行う仕組みを作っています。さらにぬい、エンジニアやアナリストがよりコンサルタントのような動き方をするための育成メニューを作っています。」
キャリアの方向性⑤:生成AI担当プラン

ゆずたそ氏:「5つ目は、Generative AIをデータパイプラインに組み込む側に回るプランです。カテゴリー分類などをMLOpsのようなイメージで行います。
もしくは、Generative AIがデータを読み取りやすいように、メタデータや中間テーブルを整備していく方向のアクションがあるかなと思います。
風音屋で今年試したこととしては、LLMやGenerative AIの商用利用でさまざまな検証をしました。またさまざまな会社でdbtやdataformなどの中間テーブルを整備するためのツールを導入していきました。さらに、社員が社内やクライアント向けに『30分で分かるデータモデリング』といった記事を作って、ノウハウを固めました。」
キャリアの方向性を決める前に
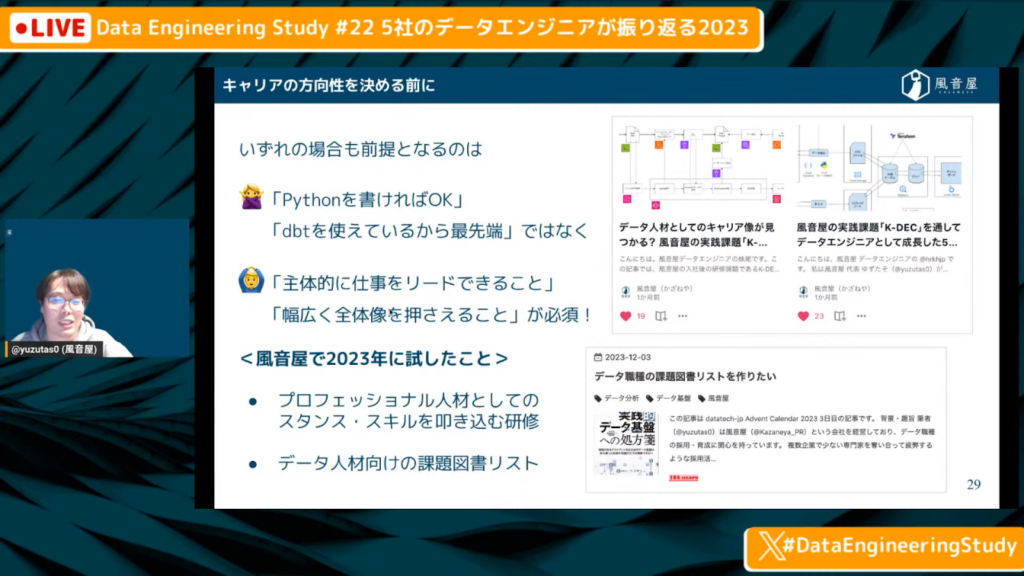
ゆずたそ氏:「どのようなキャリアの方向に行くにしても前提となるのは、やはり『Phythonを書ければOK』『dbtを使えているから最先端』ではなく、主体的に仕事をリードできたり、広く全体像を抑えられたりすることが必須だということです思っています。作業者になってしまった瞬間、キャリア的に奪われる側になってしまうでしょう。
風音屋で試したこととしては、プロとしてのスタンスやスキルを叩き込む研修や、データ人材向けの課題図書リストを作ったりしました。課題図書リストは先日ブログで出しているため、よかったら参考にしてみてください。」
まとめ

ゆずたそ氏:「2023年の出来事は、まずサンフランシスコに行ってきました。LLMやGenerative AIがデータパイプラインに組み込む事例が一気に増えたと思います。そして各ベンダーは、10秒でダッシュボードを作れる未来を提示してきました。データ職以外の人たちが50点のダッシュボードを10秒で作ってPDCAサイクルを回せる未来が見えたかもしれません。
それに対して、私たちのようなデータ人材に関わる会社としては、ツールを使えるだけのジュニアな人材にとっては逆風だと思いました。分野に特化したり、上流工程に染み出したり、より多くの人たちのデータ活用を支援したり、Generative AIを組み込む側に回ったりといった、キャリアの方向性があるのではないかなと考えました。
ただ、どの場合もシニア人材として活躍できる土台のスキルが必要だと思います。それらを踏まえて、データ人材のキャリアを開拓できるようなさまざまなアプローチを実験しました。
今回の話に興味がある方がいらっしゃいましたら、是非カジュアル面談に応募してください。」
LT3「Dataplexとdbt-osmosisを活用した「がんばらない」データカタログとメタデータ管理の運用」
吉田 康久氏
株式会社10X データエンジニア
NTTでは機械学習の研究者、株式会社はてなではWebアプリケーションエンジニア、株式会社モノタロウではデータエンジニアなどデータに関わる幅広い仕事に携わる。2022年9月に10Xに入社し、データマネジメントの業務を中心に担当。データエンジニアリングやデータ活用に関するコミュニティdatatech-jpの運営も行う。
Stailerとは
吉田氏:「今回はデータカタログとメタデータ管理の話をするのですが、それらが必要になった背景などを説明するため、どういった事業をしているか軽く説明します。
私の会社10Xでは、Stailerと呼ばれるプロダクトを運用しており、ネットスーパーやネットドラッグストアを運用するためのお客様アプリの提供をしています。また、ネットスーパーなどを運用するためには、ピッキングやパッキングなどのオペレーションが必要になるため、スタッフアプリの提供もしています。」
マスタの半自動生成にも対応
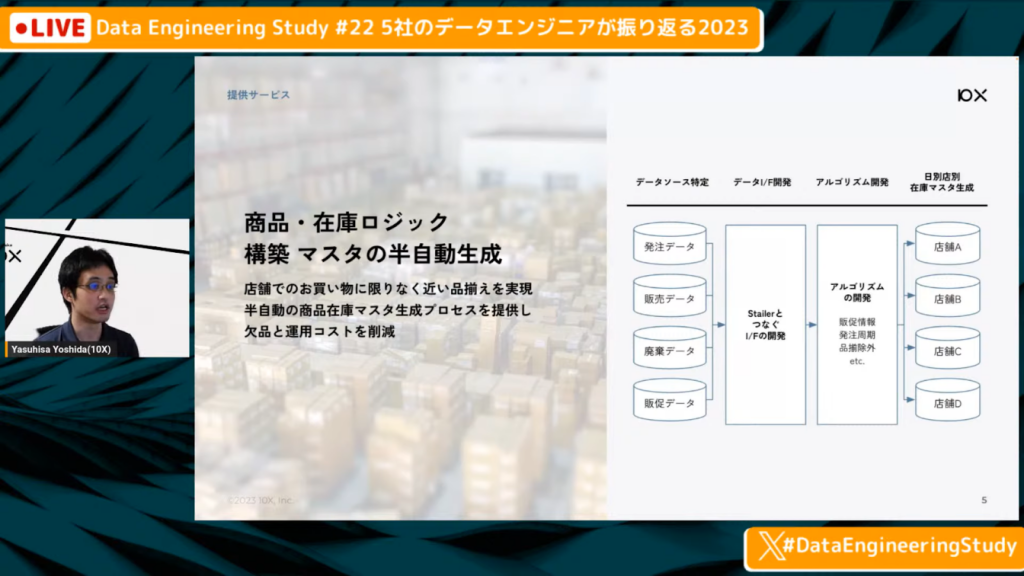
吉田氏:「あるいは、在庫のマスタなどが必要になるため、さまざまな形式のデータをStallerと呼ばれる共通の箱に加工するためにdbtでSQLを書いています。」
データ活用が不可欠な事業
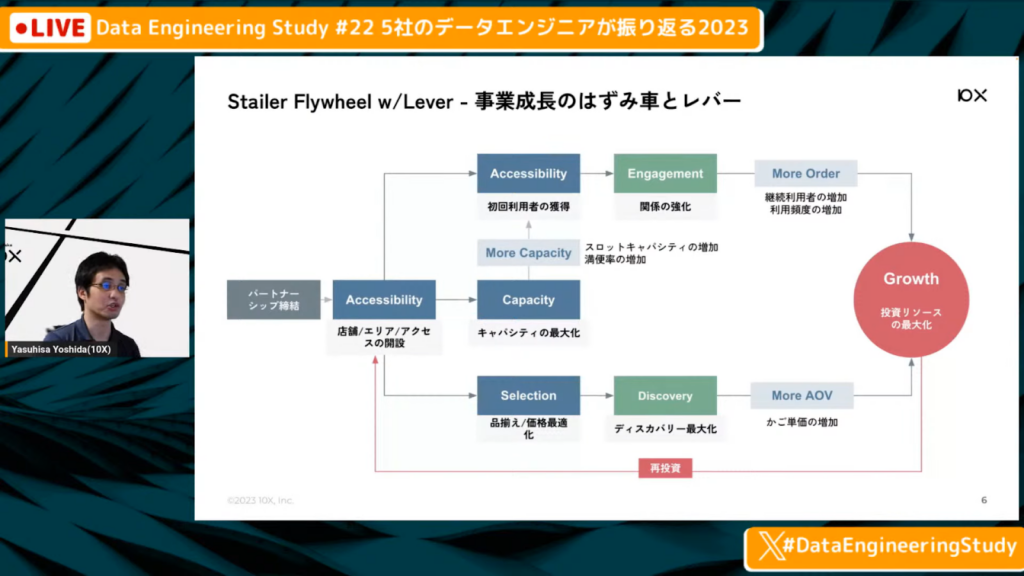
吉田氏:「ネットスーパーを開ける際に、『さまざまな店舗がある中で、どこから開ければよいか』といったアクセシビリティが問題になります。開けた後は『最初のお客さんをどのように確保するか』であったり、『お客さんにどのように買ってもらうか』や、お客さんが増えるとオペレーションがボトルネックになるため、『キャパシティをどうやって最大化するか』が課題になります。
このように、パートナーさんによって課題がさまざまですし、同じパートナーさんでも店舗によって課題が違うケースけーすがあるため、一筋縄では課題が解決できません。
このようなさまざまな種類の課題を解決するために、データが不可欠な事業なのです。」
入社直後に実施したこと

吉田氏:「私が入社してから、どういったところができている、/できていないといった、データマネージメントの成熟のアセスメントを実施しました。表に記載されている『レベル感』を見てもらうと分かりますが、最大でも「2」ほどであるため、まだまだやるべきことがあるイメージでした。
さまざまなところを整理したうえで、中心的に取り組みたいところとしては、データセキュリティとデータ品質の向上に取り組むことですを掲げています。今年に関しては特に、データセキュリティに関して大きく進捗できた1年だったかなと思っております。
アセスメントの話は過去の発表を公開しているため、そちらを参照していただければと思います。」
最近の課題:データディスカバリー
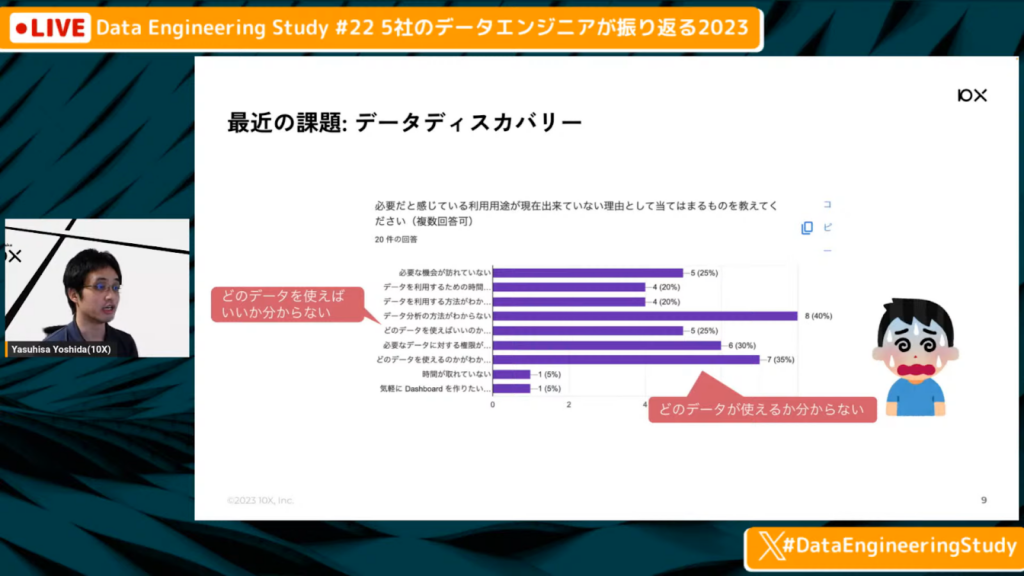
吉田氏:「データセキュリティに関しては進捗してきたのですが、社内でアンケートを取ってみた結果、データセキュリティに関しては進捗してきたものの、データディスカバリーの課題が目立ってくるようになりました。たとえば、『どのデータを使えばよいか分からない』『どこにどういったデータがあるか分からない』といったなどです声が上がりました。」
データディスカバリーが課題になった背景
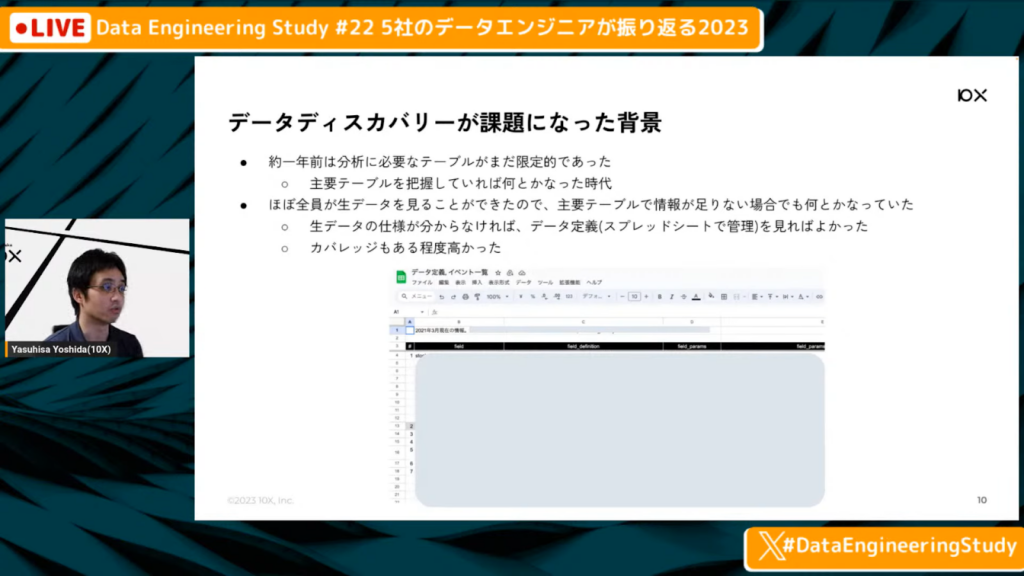
吉田氏:「なぜこういった課題が出てきたかというとを簡単に説明しますと、約1年前だと分析に必要なテーブルは限定的で、3つ、4つほどの主要なテーブルを把握していればなんとかなる時代でした。また、当時はセキュリティがまだしっかりしていなかったため、ほぼ全員が生データを見られましたし、主要テーブルでは足りない場合でも生データを見ればなんとかなるイメージでした。」
さまざま要因によりデータディスカバリーが課題に
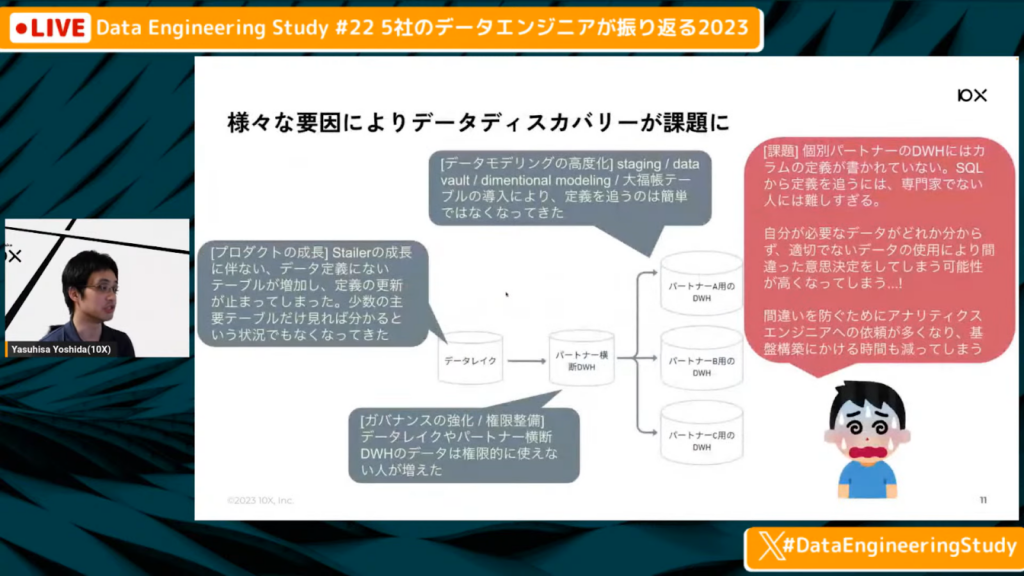
吉田氏:「しかし先ほどさまざまな箇所がボトルネックになる話をしましたが、事業やプロダクトの成長に伴って、3つ、4つのテーブルだけ見ていればよい世界ではなくなってしまいました。それ以外のさまざまなテーブルでも、データの定義が書いてあるところのカバレッジが全く足りない状況になっていました。
また競合となるパートナーがいた場合に、競合の側の詳細データを見られるとコンプライアンス的によくないと考え、自分の担当しているパートナーのデータのみ見られる仕様に強化をしました。そのため、データレイクやパートナーが横断して入っているデータしかメタデータがついていない状況でした。
昔であれば、非常にシンプルなSQLで作られていたため、自分が見られるところの定義などが分からない場合でもは、非常にシンプルなSQLで作られていたため、その部分の関係性を簡単に紐解けました。しかし、データモデリングやステージング、ディメンショナルモデリングなどが進化しており、6層、7層になってしまうため、アナリティクスエンジニア以外がスキルの定義を正確にたどることが難しくなっています。
そのため、分析をする時に細かいところはアナリティクスエンジニアに依頼をするようになり、基盤を作る側の時間も減っていき、メタデータを付与する時間もないといった、負のスパイラルに陥っていました。」
データカタログやメタデータの導入が必要

吉田氏:「こういった課題を解決するためには、データカタログやメタデータ管理をしていくことが重要だと思っています。Data Engineering Study #16にて、データカタログの話をしているため、見ていない方は是非見ていただければと思います。」
導入時に検討したこと

吉田氏:「当講演では、ZOZOやLINEなどの大きい会社がデータカタログをフルスクラッチした趣旨の発表でしたが、我々はスタートアップであるため、その部分を頑張る工数はありませんでした。
10XではOpen Metadataの導入も検討しましたが、運用の裏側でAirflowが動いてほしいものののですが、その運用を頑張るなら他の部分に注力したいと思いました。
(データカタログやメタデータの導入時には、)データユ―ザーにとって使いやすいことも条件にありました。
10Xはdbtを使っているため、dbt docsが簡単に使えます。しかし、dbt docsは比較的開発者向けのドキュメントになっており、データユーザーにとって分析には使いません。また、中間レイヤーのテーブルも見られてしまいますが、データユーザーには閲覧権限がないため、その機能は不要です。このように、欲しいものがきちんと見られるかが怪しい点がありました。」
Dataplex(旧Data Catalog)の導入

吉田氏:「さまざまな問題を解決してくれて運用が楽なものを探していた結果、Dataplex(旧データカタログ)と呼ばれるものを導入しました。」
Dataplexは検索が強い
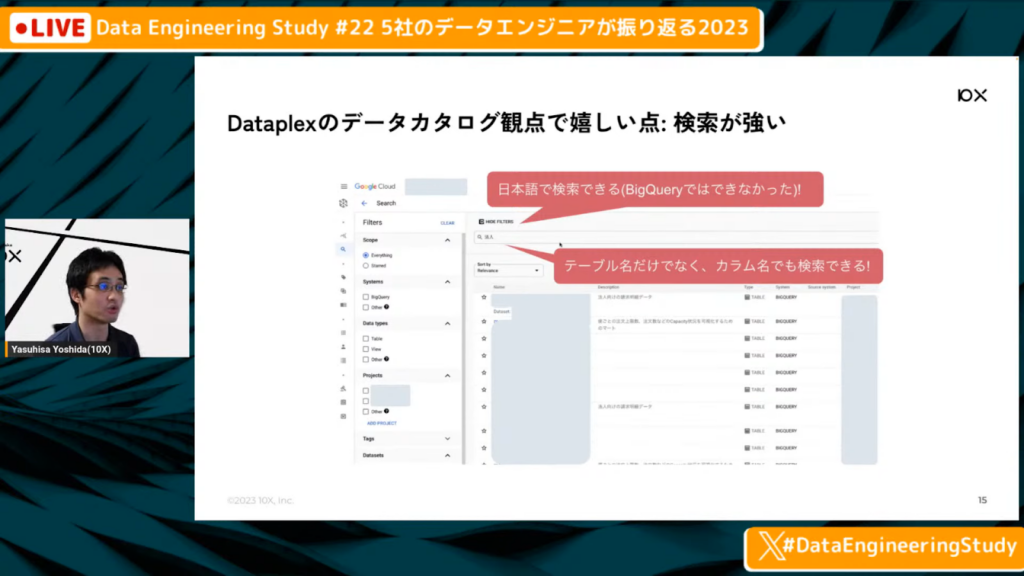
吉田氏:「Dataplexにはメリットがいくつかあります。
BigQueryでは、デスクリプションに日本語が書いてあってもその語を検索できないのですが、Googleが作っていることもあり、日本語検索が自由にできます。また、テーブルのデスクリプションのみならず、カラム名のデスクリプションも検索で引っ掛けられます。ほかにも、スターマークをつけているテーブルに絞って検索できます。
10X内だと1500以上のテーブルをdbtなどで管理しているため、検索したときに複数のテーブルが検索に引っかかるケースがあります。この際、ドメイン知識がない人や中途で入った人だと、検索結果のどれを使えばよいのかわかりません。
しかしDataplexの検索の画面は、BigQueryの中で頻繁に参照されているテーブルを上位に引き上げてくれる機能があるため、初めて使う人でも、明らかに見当違いなテーブルを参照してしまうケースは避けられます。
またIAMと統合されているため、閲覧権限があるテーブルやデータセットのみ出してくれる点も便利です。
Dataplexはデータリネージがわかる
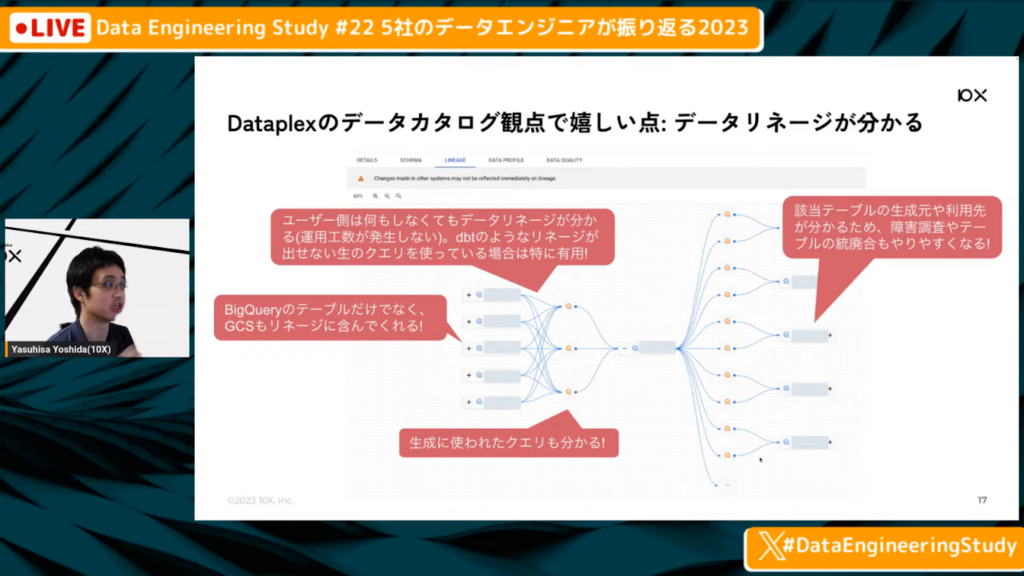
吉田氏:「データリネージがわかる点もありがたい点です。
特定のテーブルを作るために必要なものや、参照しているもののリネージが分かります。dbtを使っていると当たり前に感じますが、dbtを使っていない場合でも使えますし、digdagのような古いものを使っている場合にもリネージが自然と出るため嬉しいです。
BigQueryのみならず、GCSのバケットなども含んでくれますし、生成に使われたクエリも分かるため、再生成もやりやすいです。
また、該当テーブルの生成元や利用先がわかるため、障害調査やテーブルの統廃合もやりやすいです。さらに、普通にBigQueryを使っていると勝手に作ってくれるため、運用コストもかからない点がよいなと思っています。」
継続的なメタデータの管理が課題

吉田氏:「データカタログはDataplexに決まりましたが、メタデータの管理をどうするかが次の課題になりました。とくに、カバレッジをどのように担保するかや、継続的なメンテナンスをどのようにしていくかが課題になりました。」
人手によるカラムdescriptionのメンテナンスは大変
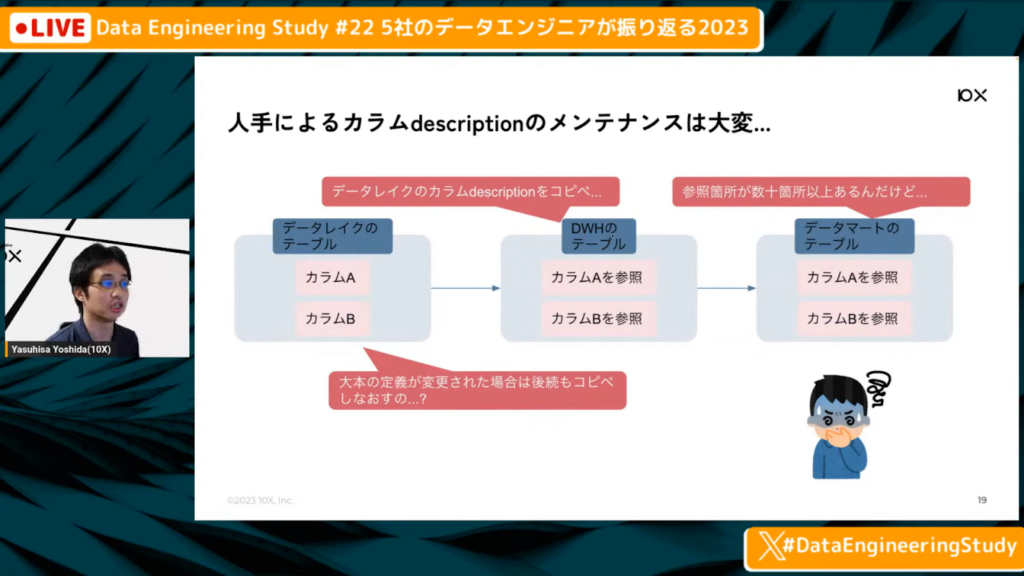
吉田氏:「3層の分かりやすいデータウェアハウスの構造です。データレイクのカラムにdescriptionが書かれており、参照しているデータウェアハウスやデータマートにカラムdescriptionをコピペします。しかしデータマートのカラムに数十個の参照箇所があると、その都度コピペするのは非常に大変です。また、し、大元の定義が変更された場合はすべてコピペし直しになってしまいます。」
dbt-osmosisの導入

吉田氏:「こういった問題を解決するためのツールを模索していた中で、dbt-osmosisと呼ばれるOSSが便利だったため、導入を検討しました。」
dbt-osmosisによるカラムdescriptionの伝播
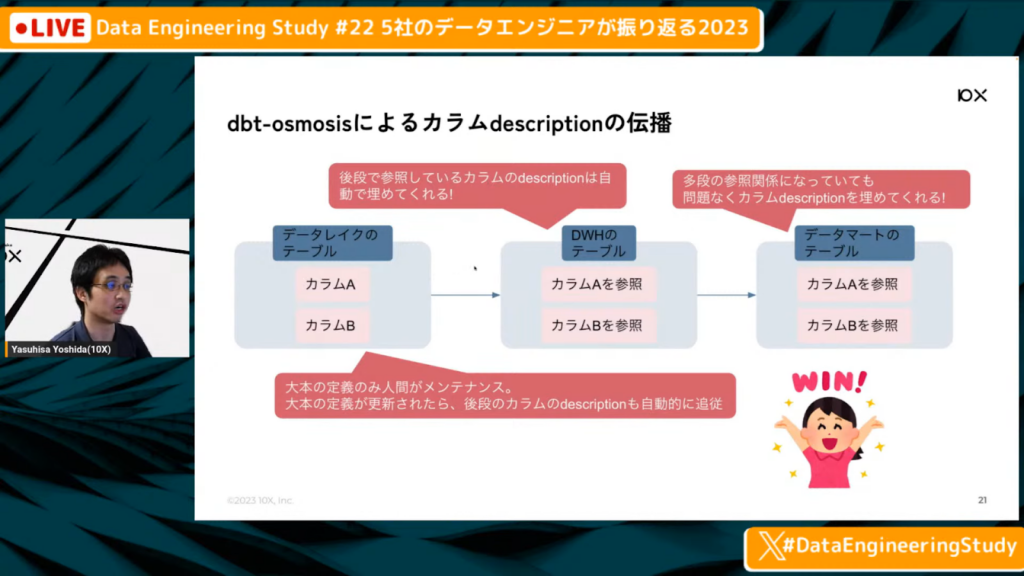
吉田氏:「参照元のカラムがあった場合、dbt-osmosisはその後段で参照しているカラムdescriptionを自動で埋めてくれたり、多段の参照関係でも関係なくカラムdescriptionを埋めてくれたりします。また大元の定義が変更された場合でも、スクリプトを回すと、参照している定義も自動的に埋めてくれます。
そのため、DWHやデータマート、その後段のカラムdescriptionのメンテナンスが簡単ですし、スクリプトを回せばよいだけであるため、簡単に継続できるようになりました。
dbt-osmosisの導入効果

吉田氏:「dbt-osmosisを導入する前は、カラムdescriptionを1割も付与できていない状況だったため、データカタログを導入しても機能しない状態でした。しかしdbt-osmosisの導入後は、カラムdescriptionが5割〜8割ほど付与され、データカタログがしっかりと機能する状況にできました。
また運用コストも非常に削減できましたし、GitHub Actionによって自動的に更新できるようになったため、メンテナンスがアナリストでもやりやすくなった点は大きなメリットだと思います。
自社運用に適用できるよう、dbt-osmosisに貢献
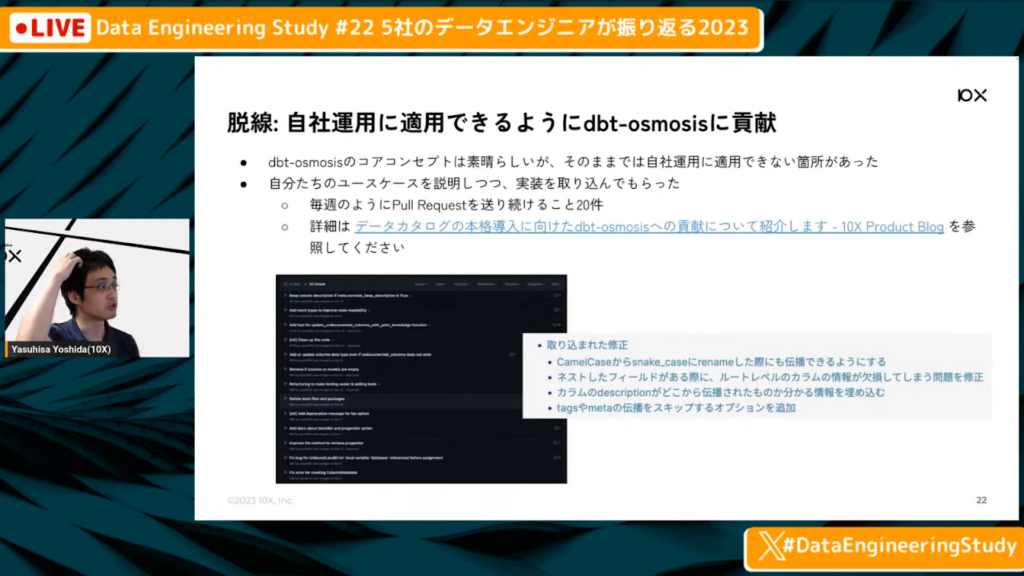
吉田氏:「少し脱線します。dbt-osmosisは非常に良いコンセプトでしたが、そのままでは自社運用に適用できない箇所がありました。そのため、今年の夏にdbt-osmosisへPull Requestを毎週のように計20件ほど送り続け、さまざまな修正を取り込んでもらい、自社運用できるようにしてもらいました。
10X Product Blogに詳細を書いているため、そちらを参照してもらえれば幸いです。」
取り入れてもらった修正
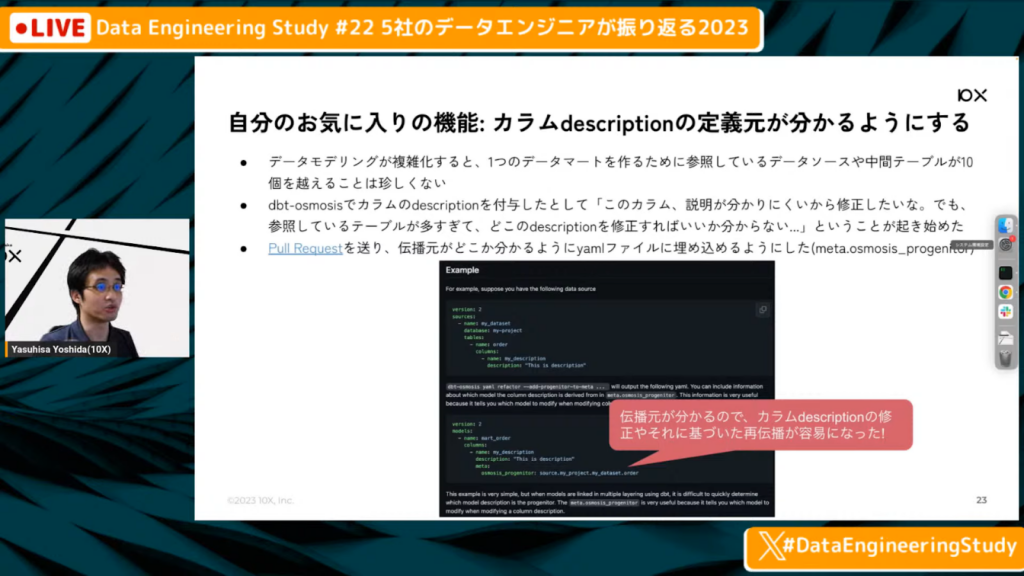
吉田氏:「データモデリングが複雑化すると、1個のデータマートを作るために参照しているデータソースや中間テーブルが10個を超えるケースがあります。そうなると、特定のデータマートのカラムの説明を修正したいと思った時に、10個のテーブルのうち、どれを変えればよいかわからない状況になってしまいます。
自動的に伝播したカラムの元々の定義がどこにあるかわかるように、自動的にyamlファイルに埋められるように、Pull Requestを送りました。また、説明がおかしかったら、どこを変えればよいか分かりやすくする修正などを送って、自社運用に適用できるよう進めていきました。」
まとめ

吉田氏:「はじめはさまざまなデータの課題がありましたが、まずはデータセキュリティを強化しました。しかしそれが原因となって、次はデータディスカバリーが課題になりました。
そのため、データカタログやメタデータ管理で解決しようと試みますが、その部分にコストをかけることが難しかったため、データカタログではDataplex、メタデータ管理ではdbt-osmosisを導入しました。これらの導入により、データディスカバリーに多くのコストを割かずに、この課題に対応できるようになりました。
これらのおかげで、データユーザーはセルフサービスで自分の分析に必要なデータを見つけられるようになりましたし、データエンジニアはデータ品質などの重要なイシューに時間を割けるようになりました。」
10Xはデータエンジニアやアナリティクスエンジニアを募集中
吉田氏:「こういった背景があるため、マスターデータやデータモデリング、データ品質などの部分をこれからさらに頑張っていきたいと思います。そのため10Xでは、データエンジニアやアナリティクスエンジニアの募集を活発に行っております。
内容が気になる方はカジュアル面談にお声がかけをいただければと思います。」
LT4「デジタル庁のデータ分析基盤「sukuna」の立ち上げと発展 〜 Agile&FragileからTrust&Robustへ」
長谷川 亮(hase-ryo)氏
デジタル庁 Fact&Data Unit データエンジニア
インテージでデータ整備とデータ基盤の運用を担当。Webメディアやリクルートでデータ分析をした後、メルカリにてデータ分析とデータマネジメントを行う。現在はおもにデジタル庁のFact&Data Unitでデータ分析基盤の開発・整備に従事。社会の基本データ(ベース・レジストリ)のオープンデータ化などを行っている。
今回の話のターゲット

長谷川氏:「今回の話は以下のような人に届けばよいなと思っています。
- 社内や行政組織内でデータ分析組織を立ち上げたい、スケールさせたい方
- 今運用しているデータ分析基盤に何らかの課題感を抱いており、作り直したいと考えている方
- 行政組織におけるデータ活用の現状を簡単に知りたい方
持ち帰ってほしい知見は、『データエンジニアも需要を意識してパイプラインを作っていこう』です。」
アジェンダ

長谷川氏:「まず、デジタル庁の話をして、そのデータがどうなっているのかを話します。その後、そこで作ったパイプラインの話をしていきます。」
データ分析基盤についてはデジタル庁公式ノートにて掲載中

長谷川氏:「どのようなデータ分析基盤を作っているかについては、デジタル庁の公式ノートにすでに書いてあるため、お時間がある方は『デジタル庁のデータ分析基盤「sukuna」』の記事を見ていただければと思います。」
政策データダッシュボードで情報透明化
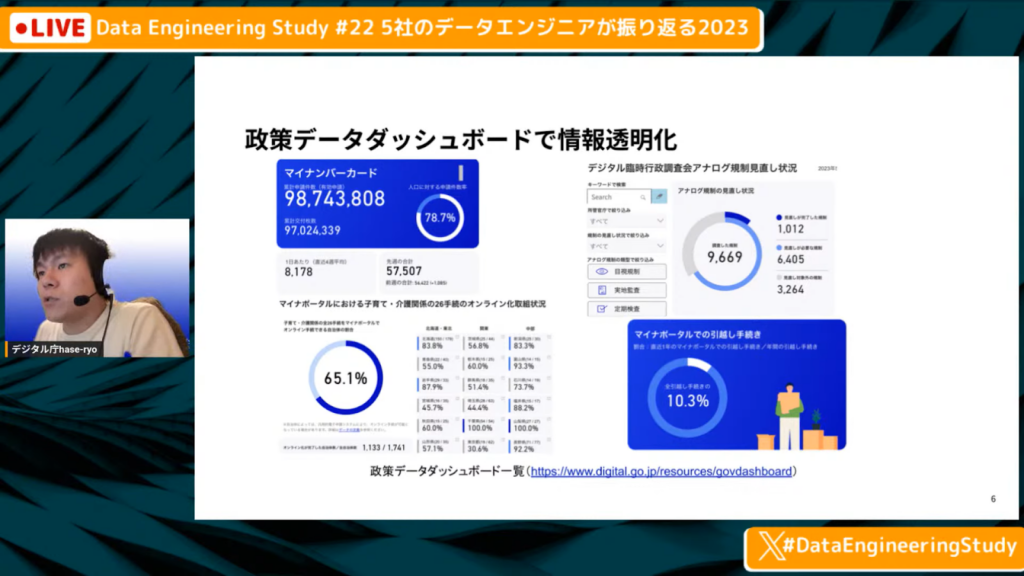
長谷川氏:「実際にデジタル庁で行った成果で1番分かりやすいものは、政策ダッシュボードによる情報の透明化です。デジタル庁の公式ホームページ上にダッシュボードが掲載されているページがあり、そちらでデジタル庁の政策についてダッシュボードで公開しております。こちらはどなたでも見ることができますし、スマホでも綺麗に見られると思います。
スライドの画像は昨日取ってきたものです。が、(画像左上には)マイナンバーの発行枚数があります。また、マイナポータルではいくつかの行政手続きが可能なのですが、自治体によって方法が異なるため、その自治体別の数字が掲載されています。
『郵送/対面のみの対応』と法律で定められており、デジタルでは不可能なケースがあります。そこで、それらを見直していく動きがあるため、見直しがどのように進んでいるか見られるダッシュシボードを公開しています。
この裏に我々が作っているデータ分析基盤があります。」
そもそも中央省庁のデータはどうなっているのか
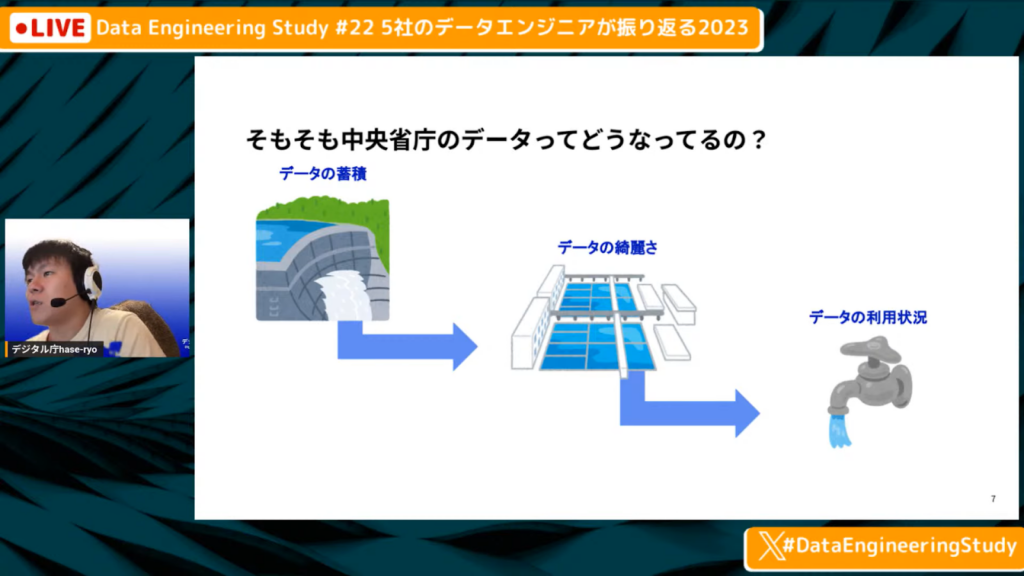
長谷川氏:「中央省庁は民間企業のデータエンジニアからすると中がわからず、なんとなく『遅れているのではないか』と思われていると想像するため、実際どうなっているのかを簡単にご紹介します。
スライドの図は、データの流れを水の流れに例えた図です。水が溜まっているダムから、浄水場を経由して綺麗になり、最終的に我々の家庭の蛇口から出てきます。データに関しても同じことが言えるため、それになぞらえて説明します。」
省庁にデータは溜まっているのか

長谷川氏:「まず、果たして中央省庁はデータを持っているのかの質問にYes/Noでいうと、『YesでありNo』といった状態です。データが蓄積されているかに関しては、政策によってかなりまちまちです。
省庁のパターンとして多いのは、統計データは多いが、ローデータそのものは少ないケースです。行政は基本的に、ローデータは何らかのシステムなどを外注しています。つまり、民間の事業者に委託しているため、その委託事業者側の持っているデータベースなどにローデータがあるケースが多いです。
では、そのローデータを貰えば分析に使えるのではと思いますが、事業者から提供可能かどうかはまた契約や法律などのさまざまな障壁があるため、また別問題になります。
また、そういったデータは分析の観点でモデリングされているわけではないため、分析利用するためのハードルがありますし、そもそも分析利用して良いのかといった問題があります。たとえば、マイナンバーのデータを分析利用する、といった趣旨の文はおそらく書いてありません。
このように、『利用目的に即しているか』『法的に可能なのか』を考慮すると、かなり高いハードルがあります。
また、行政はやはりExcelの利用率が非常に高いです。アンケート形式など、人間が分かりやすい統計の状態で保存されているデータが多いのです。たとえば総務省であれば、自治体に向けて、Excelのデータを約1700の自治体に一斉送信します。それをメールで回収して、総務書の人が必死に約1700のExcelのデータを統合して集計できるようにする、地獄のような作業をするケースが非常に多いです。
ごく稀に、SaaSを利用してAPIからデータ取得可能なものもあります。つまり、データはありますが、分析に利用するにはハードルが高い状態です。」
省庁のデータは使いやすい状態か
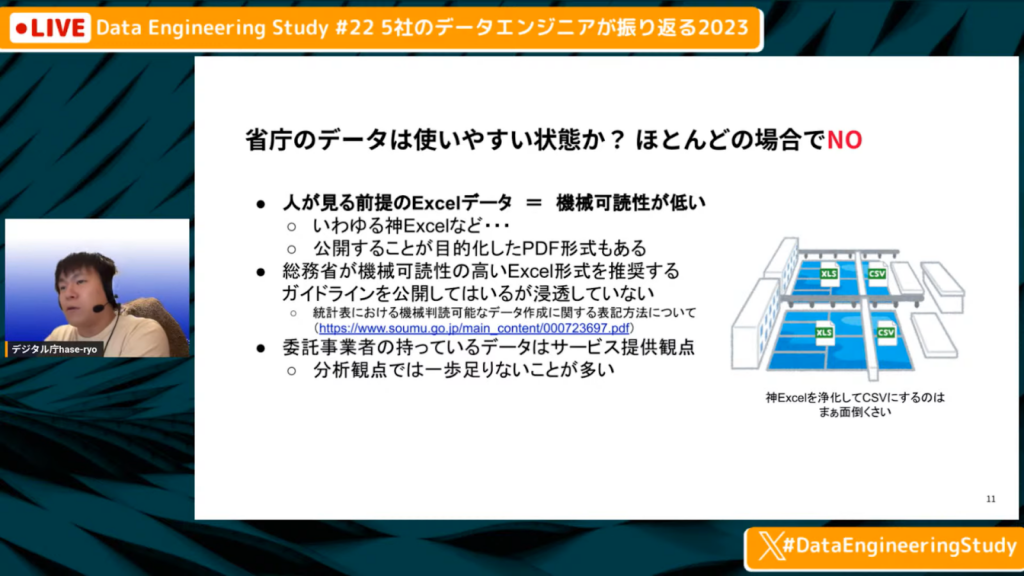
長谷川氏:「省庁のデータは使いやすい状態かと聞かれると、ほとんどの場合はNoです。なぜなら、人が見る前提のExcelになっているため、機械からすれば非常に読みにくいからです。
Excelでいうと、A1のセルはほとんどのケースは空白で、B2のセルなどから題名が入っており、しっかりとした形で入っているケースは非常に少ないです。
また、方眼紙状にしたExcelをセル結合して作る『神Excel』(見た目だけを重視し、利用性に欠けるExcel)がありますが、それらは非常にCSVにしにくいです。
また、『データを公開しなければならない』と法律で定められているため公開しているものの、ただ公開すればよいといった考えで、とりあえずPDF形式にしているケースもあります。しかし、PDF形式のデータは読み取るのが非常に面倒です。
以上より、使いやすいデータはあまりありません。総務省は、機械可読性の高いExcelを作る旨のガイドラインを作成し、それに従うことを公表していますが、正直なところ、あまり浸透しておらず、まだ神Excelは多い状態です。
Excelを、CSVなどのいわゆる『データエンジニア的に使いやすい形』に変換することは、非常に面倒な作業です。」
省庁のデータ活用は進んでいるのか

長谷川氏:「こういった状況もあり、中央省庁でデータ活用は進んでいるのかというと、まだNoが多いです。
ここまで説明した通り、『データが使いにくい形のため、活用も進まない』鶏卵のような関係があります。さらに、KPIを振り返りなど、データをしっかりと見る制度がそもそも少ないです。
行政の使うデータは我々国民が生活するうえで必須のデータであるため、流出すると非常に危険です。そのため、そういったリスクを重めに見ると、もちろん『データは使うのは危険なもの』と、慎重な姿勢を取られる方も非常に多いです。
とはいえ、政策の効果検証についての話が持ち上がった際に、単発的にデータ活用が実施されるケースは多々あります。ただ、単発的に行われる効果検証も、Excelを各自治体にメールで送信/回収して、それらを1つのExcelに統合する面倒なプロセスで行われています。
先進的なデータ活用は、一部の省庁では実は進んでいるところもあありますが、全体的に見るとまだまだといった状況です。」
中央省庁のデータ活用状況まとめ
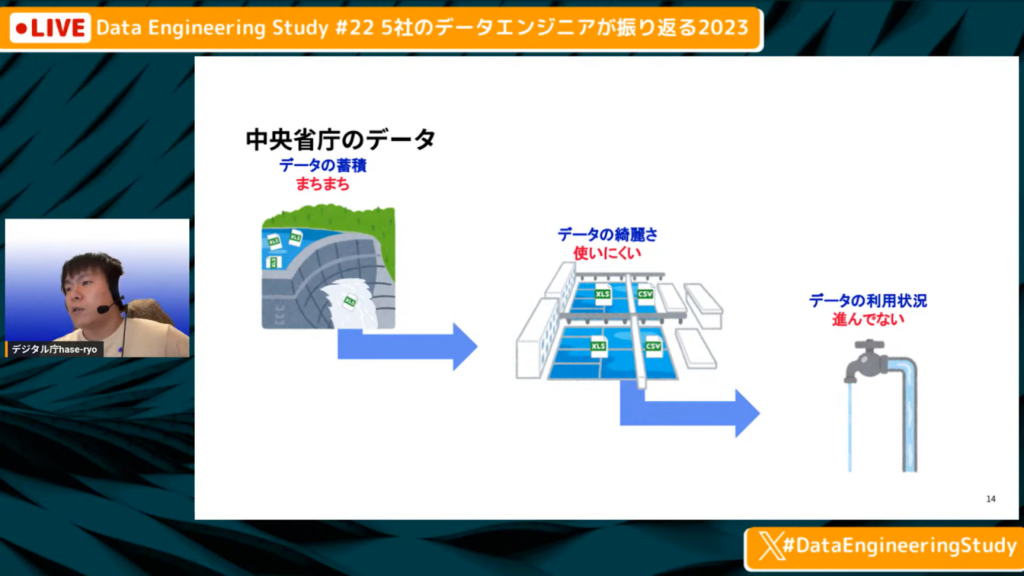
長谷川氏:「データの蓄積は、データの種類によりますが、まちまちでExcelが特に多い状態です。データの綺麗さは、ExcelをCSVに変換するプロセスが面倒な状態です。データの利用状況で言うと、あまり進んでいません。」
EBPM遂行のためには、『使える』『活用できる』を優先
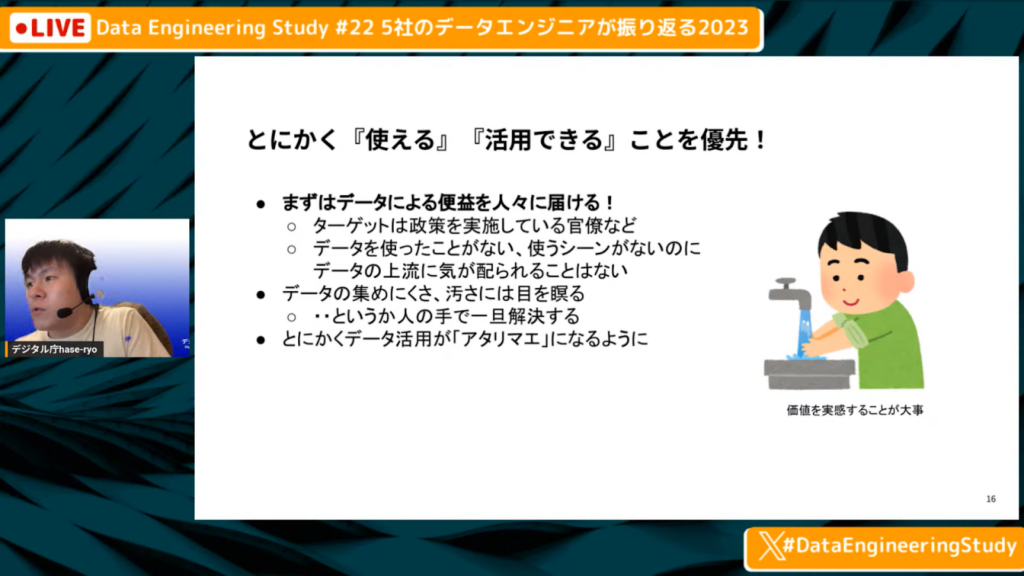
長谷川氏:「EBPM(Evidence Based Policy Making)、つまりデータに基づいた政策を実行していくためにはどうしたらよいのでしょうか。
とにかく、使ってもらうことを優先して、まずはデータによる便益を人に分かってもらう方向に舵を切りました。政策を実施している省庁の官僚などに、そもそも『データは意味がある』と思ってもらう必要があります。
当然、データの価値を知らずしてデータ品質やデータの蓄積、データ基盤に注意が向くわけがありません。その状態では、リソースも割り振られないため、まずはデータ活用の便益を実感してもらうためにさまざまな活動を行いました。
その過程で、データの集めにくさや汚さについては一旦目をつむって、人の手で解決するケースがありました。
蛇口から水が出て嬉しいのと同じように、とにかくデータが活用できるようになり、それによって何かしらのメリットを得られることが、行政内で当たり前になる風潮を作っていこうとしました。
「sukuna」の誕生

長谷川氏:「とりあえずAgileに(機敏に)、Fragileでも(壊れやすくても)パイプラインを敷くことを検討し、データ分析基盤「sukuna」を作りました。
sukunaはGCPの1プロジェクトで完結するような、大掛かりではないデータ分析基盤です。一方、データを取り込む部分はCloud functionでデータを取り込んでいます。また、Pythonでも無理なところは人力でExcel加工している部分もあります。
データレイク・データウェアハウス・データマートの三層構造はBigQuery内で作っています。またどんどんクエリを回して、データアナリストの観点からも、『行政に役に立つ分析結果とは』『データモニタリングとは』といった点を試行錯誤し、何らかの結果を出せるようにしています。
そして、『データPMが一旦受け取ったExcelデータをCSVに直してアップロードし、加工してダッシュボードに繋げ、何らかのグラフを表現して役人のとこに持っていく』プロセスを一気通貫で行える権限を与えています。
もちろん、データを持っている人が別の省庁の人であるケースも多くあるため、その都度別組織との調整を並行して行います。また、『このデータが見られるようになるため、今後この政策が楽になる』といった話をデータ利用者に届け、意思決定してもらう調整も行います。
データパイプラインがある程度安定してきたら、dbtなどのプロダクトを徐々に使いながら、機械にバトンタッチしていく形でパイプラインを作り上げていきました。」
EBPMへの期待が高まりつつある

長谷川氏:「その甲斐あって、データ活用が徐々に広まり始め、冒頭でご紹介したような政策データダッシュボードなどの成果に繋がりました。
ところが、岸田総理大臣が議長のデジタル行財政改革会議で、EBPMに言及された影響で、事態が急速に進み始めました。
何を言われたかというと、ダッシュボード等での見える化の徹底をしたり、ROIや効果検証の前に政策の状況をモニタリングしたりすることです。さらに、データを行政内で負担なく取得できる仕組みの構築に関して、『データの取得方法の刷新』『データ分析の共通基盤化』『データの標準化』などに言及されています。」
今後はTrustかつRobustなデータ分析基盤が求められる

長谷川氏:「そのため、我々のようなデータ分析基盤を生業としている人間としては大変です。今作ったものでは、耐えられないかもしれない可能性が出てきたのです。
先ほどはAgileかつFragileと言いましたが、今後はその反対の、Trust(信頼できる)かつRobust(頑強な)なデータ分析基盤が求められます。
1度蛇口から水が出たら、『蛇口をひねったら水が出るのは当たり前』になるのが人間であるため、データ活用できることは大前提になります。そして、安定して使い続けられる蛇口が求められるように、データに関しても、安定して提供される状態や、データ運用にはリスクがあるため、データ分析基盤に安心してデータを預けられる状態が求められます。
取得方法に関して、まだExcelやAPAに依存している状況があるため、さまざまな取得方法に柔軟に対応できる状態が求められます。そういった刷新を行う際、人ではスケールしないため、仕組みやシステムで担保していく必要があります。そのため同時に、安全性や権限管理の徹底が重要です。
しかし、スケールさせるためのメンテナンス性の高さや開発のしやすさの確保が追いついていないのが現状です。そのため、作成したパイプラインを早速壊して、データ分析基盤の再構築が鋭意進行中です。」
利用者の期待値の変化に追従しよう

長谷川氏:「結論として、利用者側のパイプラインに対する期待値は徐々に変わっていきます。最初は『とりあえず早く届いてくれたら嬉しい』状態だったのが、届いて当たり前になり、『安定性と信頼性こそが大事』とシフトしていきます。そのため、その要望に対して我々も追従していく必要があるのです。」
時には大胆にパイプラインを作り替える
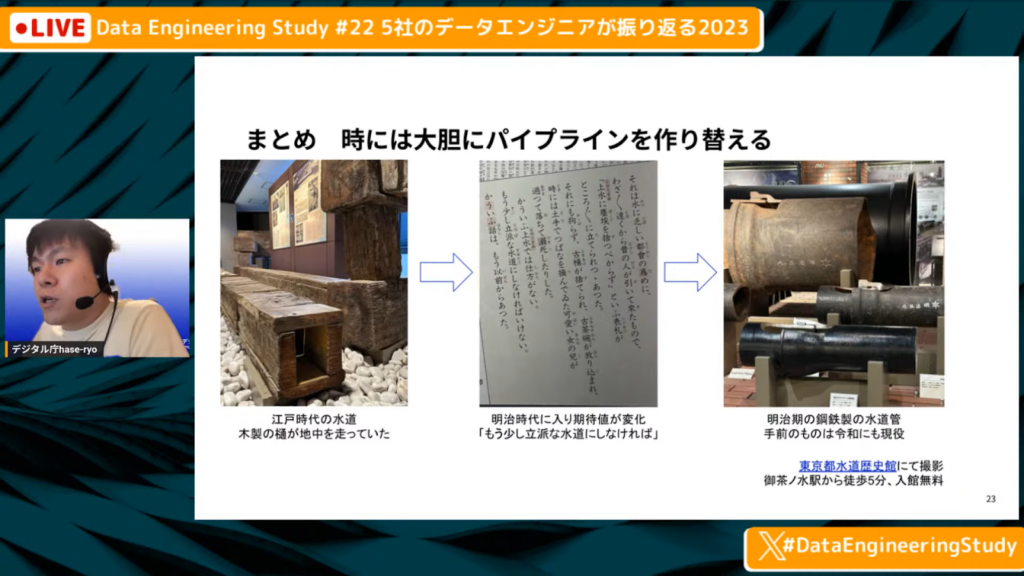
長谷川氏:「時には大胆にパイプラインを作り替える必要があります。
先ほどからスライドでお見せしていたいくつかの写真は、東京の水道の写真で、木製のものは江戸時代の水道だそうです。このような水道が江戸時代の地中に埋まっており、多摩川から水を引いてきて千代田区まで届けていたと言われております。
しかし、200年ほど経って明治時代に入ると、利用者の期待地も変化しました。浄水道が汚れているため、より立派な水道にしなければならないと当時の新聞に掲載されたそうです。そのため、明治期になって今でも見るような鋼鉄性の水道管が作られ、パイプライン全体を入れ替えるプロジェクトがあったそうです。
似たような話がデータについても言えます。このパイプラインでは需要に応えられないと思ったら、思い切って作り替えることが必要だと思います。」
LT5「データエンジニアリングの現在地とData Developer Platform」
山中雄生(Yuki Yamanaka)氏
ノバセル株式会社 データエンジニア
大学院卒業後、2021年ラクスルに新卒入社。ノバセル事業部にてWebアプリケーション開発および、Snowflakeを用いたデータ分析基盤の構築・管理を担当。分社化に伴い、ノバセルに転籍。現在は、データプロダクトチームにてプロダクトマネジメントおよびデータエンジニアリング業務に従事。また、Snowflakeに関する本やブログ執筆、コミュニティ活動に参加しており、2023年 Snowflake Data Superheroesに選出。
データ基盤の民主化

山中氏:「今回のテーマは、データ基盤の民主化です。ビジネスの人たちでもデータを使えるようにするといった一般的なデータの民主化ではなく、開発者がデータ基盤を使って開発していく際の民主化についてお話しします。」
データエンジニアを取り巻く環境

山中氏:「それを話すうえで、今年どのようにデータエンジニアを取り巻く環境が変わってきたかをお話しします。」
データエンジニアとは
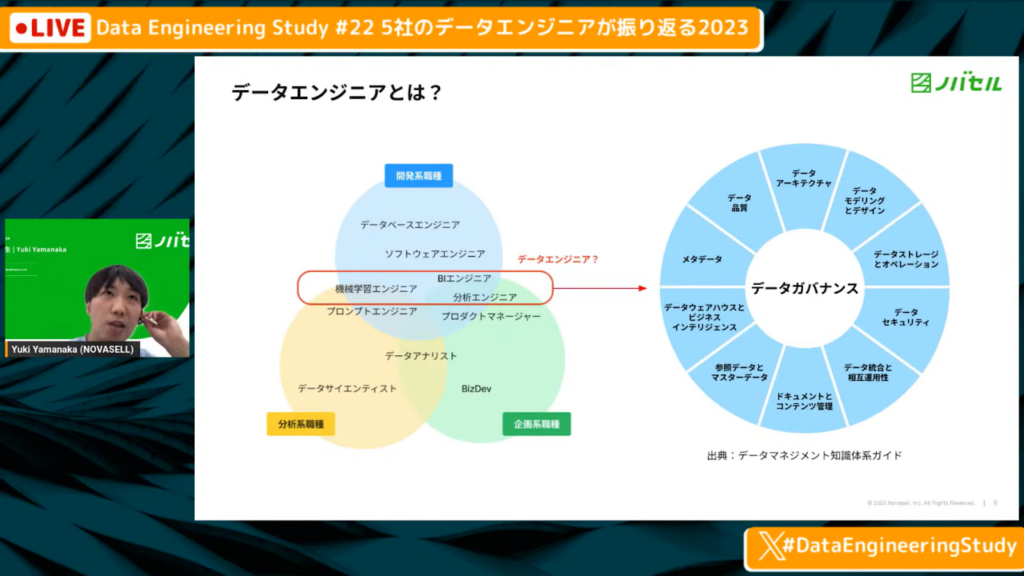
山中氏:「データエンジニアは幅広い定義であると思いますが、私の解釈では開発・分析・企画とある中で、中間の存在だが開発側の人といったイメージです。
データガバナンスの10のホイールズがありますが、ここでは機械学習や分析、BIを扱っている人をデータエンジニアとして話していきます。」
データエンジニアの担当領域は広がっている

山中氏:「今年はデータエンジニアリングに関して、さまざまなトレンドや展開があったと思います。
開発系で言うと、ソフトウェアエンジニアリングのノウハウが入ってきた印象です。dbtなどのツールのアップデートもありましたし、SREやオブザーバビリティ、テストなどのツールも多々出てきました。
特徴的なのは、データプロダクトの名前で、データをプロダクト的に捉えて、マネージメントや品質管理する話題がありました。マイクロサービスやリバースETLが発展しており、データ中心のアプリケーションデザインなどのデータをより活用していく発展もあったと思います。
分析系に関しては、llmを中心として機械学習の社会実装がますます進んだと思います。
企画系においても、データを元にした事業開発や運営のプラクティスが今年も日本に入ってきて広がっていると思います。
データに関わるエンジニアリングの領域が非常に広がったのが今年の感覚です。」
Data Developer Platform

山中氏:「より多くのエンジニアがデータ基盤に関わっていくと思っています。その中で登場する考え方が、今回お話ししたいData Developer Platformです。
Data Developer Platformとは、ざっくり言うと今年のトレンドだったPlatform Engineeringをデータエンジニアリングやデータ基盤に適用していく考え方です。」
DevOpsの現状
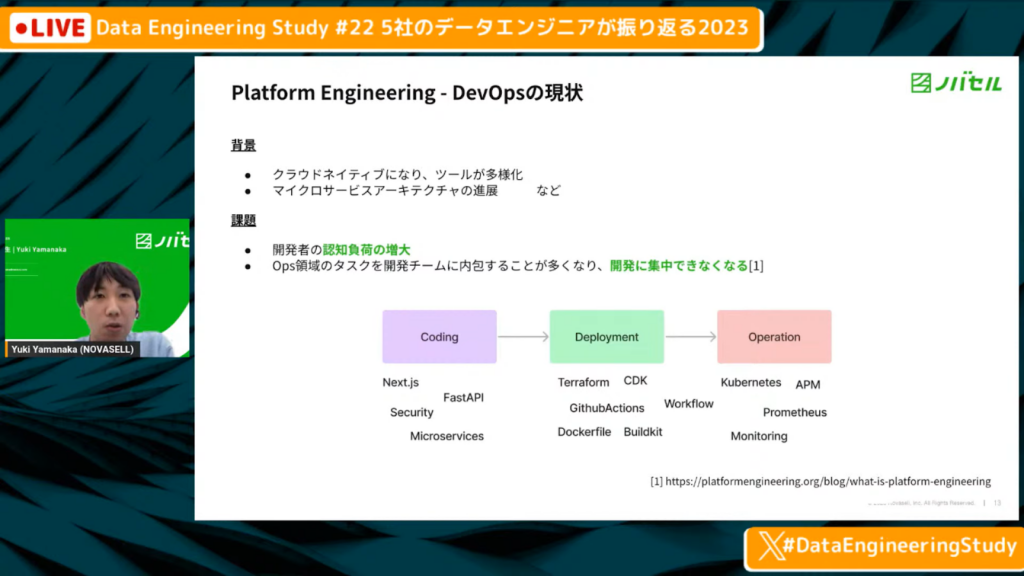
山中氏:「DevOpsの現状に関して、クラウドネイティブのサービスが増えてきており、SaaSツールやOSS含め、対応化してきました。また、マイクロサービスアーキテクチャも広がっており、小さいサービスでコンテナを作ってデプロイするケースが増えてきたと思います。
それに伴い、開発者がコーディング・デプロイ・運用までのプロセスを全てやろうとすると、非常に認知負荷が増大します。さまざまなツールが登場してパンクしてしまい、デプロイできない状態が生まれてしまっています。」
Platform Engineeringとは
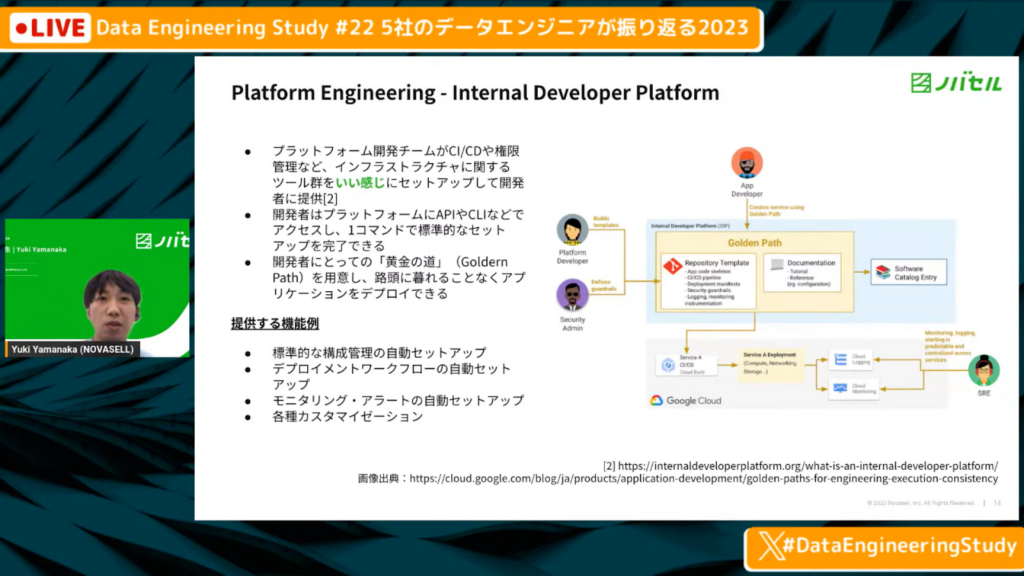
山中氏:「それに対しての解決策が、Platform Engineeringです。プラットフォーム開発チームがCI/CDや権限管理などのインフラに関するさまざまなツール群を開発者に提供し、開発者はそのツールを使ってセルフサービスで開発のホスティングなどを作れます。
詳細については触れないため、レファレンスを見ていただければと思います。」
プロダクトとしてのプラットフォーム
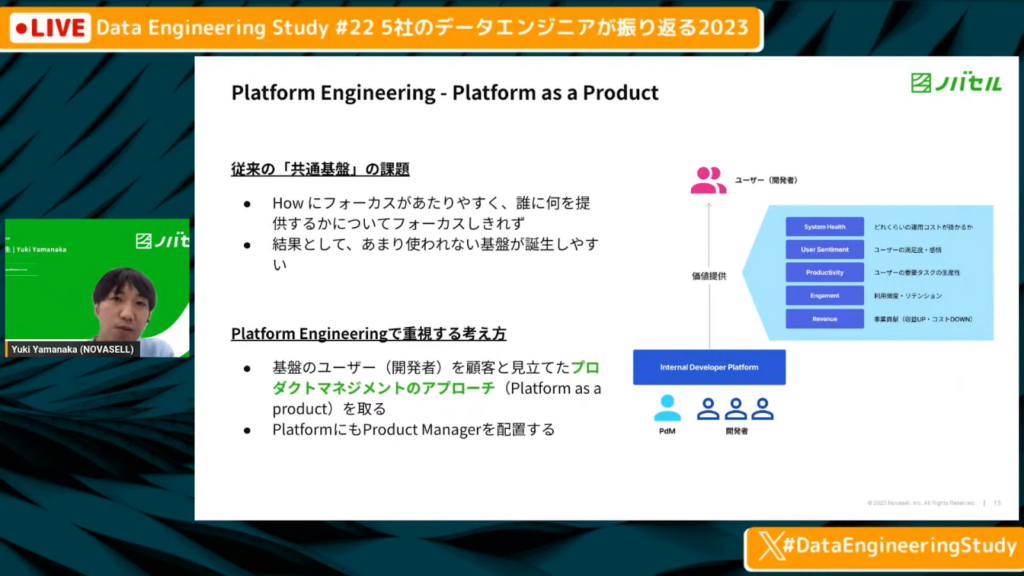
山中氏:「こういった共通基盤の考え方は昔からあり、それ自体はとくに新しい考え方ではありません。しかし、Platform Engineeringで重視する考え方は、セルフサービスでできるようにする点と、プロダクトマネージメントのアプローチをとる点です。
そのため、プラットフォームチームにもPdMのような人がいて、開発者をユーザーと見立てます。そこに対して価値提供をしていき、そのためのメトリクスを設定して継続していくことが1つのコンセプトです。
そして、このPlatform Engineeringをデータ基盤にも適用していきます。」
Data Stackの現状
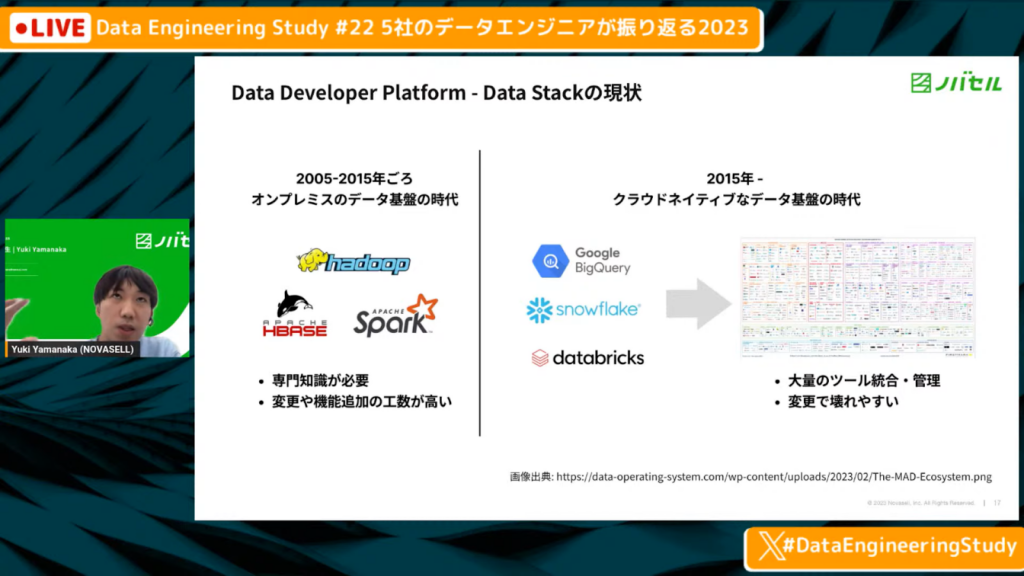
山中氏:「Data Stackの現状に関して、ここ5年ほどでクラウドネイティブなデータ基盤が広がっており、モダンデータスタックに代表されるような非常に多くのツール群が乱立しています。
その中で、ツール統合や管理が非常に大変になっていると思いますし、変更はしやすいが壊れやすい状態が生まれていると思います。これは、Platform Engineeringの課題や背景と非常に近い状態なのです。」
データ基盤を利用したアプリケーション・プロダクトの開発が拡大

山中氏:「さらに、先ほどお伝えしたように、データを使って何かを作ったり事業開発したりするケースが非常に増えてきているため、データ基盤を利用してアプリケーションやプロダクトを作るケースが今後拡大していくと思います。そのため、データ基盤の変更しやすさや、基盤上で何かをするアプリケーションの作成も考えていく必要があります。」
Data Developer PlatformはPlatform Engineeringのデータ基盤バージョン

山中氏:「Data Developer Platformは、Platform Engineeringのデータ基盤バージョンです。データプラットフォームに関するCI/CDや権限管理などを”いい感じ”にセットアップして開発者に提供する考え方です。
実践例としては、先日のPlatform Engineering Meetupでリクルート様が発表されていた内容が該当すると思います。」
Data Developer Platformの5つのコアケイパビリティ

山中氏:「Data Developer Platformは、おもに5つほどコアケイパビリティがありますが、Platform Engineeringにもほとんど同じ項目があります。『設定管理』『インフラストラクストラクチャのオーケストレーション』『環境管理』『デプロイメント管理』『権限管理』です。」
ノバセルでの実装例
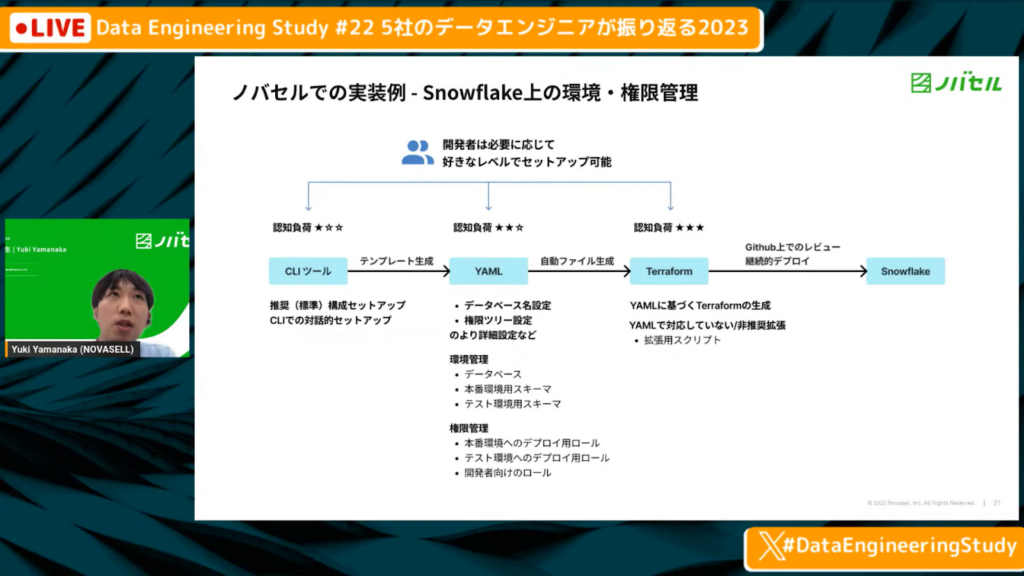
山中氏:「弊社での実装例を軽くご紹介します。ノバセルでは、Snowflake上での環境・権限管理をData Developer Platformの考え方に基づいて行っています。
最終的にSnowflakeにリソースをアプライする部分に関しては、Terraformを使っており、GitHub上でレビューや継続的なデプロイを行っています。ただ、やはりTerraformも開発者が触るのはハードルが高いため、その前段として、推奨の権限管理の仕方をYAMLで設定できるようにしています。
さらに、YAMLすら面倒な場合はCLIでデータベース名だけ入れれば、あとは推奨の構成でセットアップする提供をしています。
それぞれのツールでできることの幅が変わるため、開発者が必要に応じて選択します。パッとセットアップしたければCLIを使い、幅広い設定や複雑な設定はYAMLやTerraformを使います。このような選択を全てセルフサービスでできるようにしています。
引用元

山中氏:「詳細については、レファレンスで確認していただけると幸いです。」
過去のData Engineering Studyのアーカイブ動画
Data Engineering Studyはデータエンジニア・データアナリストを中心としたデータに関わるすべての人に向けた勉強会を実施しております。
当日ライブ配信では、リアルタイムでいただいた質疑応答をしながらワイワイ楽しんでデータについて学んでおります。
過去のアーカイブもYouTube上にございます。興味をお持ちの方はぜひご覧ください。
https://www.youtube.com/@dataengineeringstudy6866/featured
TROCCO®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、データ基盤構築の総合支援サービスです。データの連携・整備・運用を効率的に進めていきたいとお考えの方や、プロダクトにご興味のある方はぜひ資料をご請求ください。






