
本記事では、データウェアハウス(DWH)、ETLプロセス、BIツールなどのアップデート情報や最新トレンドを毎月わかりやすくお届けします。
主要なニュースをピックアップしているので、サクッと最新情報をキャッチアップしたい方は、ぜひご覧ください。
Podcast版はこちらです。
Data Engineering Newsの公開時にメール通知をご希望の方は、こちらのフォームよりご登録ください。
| 今月のData Engineering Newsの共同著者は以下のメンバーです。 片貝桃子、伊藤雄、海藤公紀、若松 拓夢、河野浩明、中山愛弓、今川航、西山徹、廣瀬智史 |
Google BigQueryのニュースまとめ
データ品質スキャン結果をDataplex Universal Catalogへ公開する機能が一般提供開始されました
BigQueryのデータ品質スキャンの結果をDataplex Universal Catalogにメタデータとして公開できるようになりました。
これにより、スキーマ情報やデータ分類だけでなく、「データの品質状態(例:NULL率や一貫性)」を横断的に参照・追跡できるようになります。
データインサイトの機能拡張がプレビューになりました
BigQueryのテーブル選択>「分析情報」タブ>「分析情報を生成」からアクセスできる機能がデータインサイトです。
Geminiを活用してテーブルメタデータからテーブルやカラムの説明を自動生成できるようになりました。
これにより、データカタログの充実化とドキュメント作成の効率化が図れます。
データセットとテーブルのIAMタグのSQL管理が一般提供開始されました
BigQueryのデータセットやテーブルに対して、IAM条件付きアクセス制御に使う「IAMタグ」の付与・変更を、SQL文から実行できるようになりました。
これにより、タグベースのアクセス制御をSQLで一元管理できるようになり、CI/CDパイプラインへの組み込みや自動化が容易になります。
BigQuery MLでの複数時系列の一括予測が一般提供開始されました
BigQuery MLで、ARIMA_PLUS_XREGモデルを使った複数時系列の一括予測が一般提供されました。
これまでは「1系列=1モデル」でしたが、「複数系列をまとめて1モデルで予測」できるようになります。
TIME_SERIES_ID_COL オプションを使うことで、商品ごとや店舗ごとといった単位で、複数の時系列データを同時に予測できます。これにより、大量の系列を効率的に処理し、包括的な予測・分析が可能になります。
Vertex AI Provisioned ThroughputとGeminiモデル連携が一般提供開始されました
GeminiモデルをBigQueryやVertex AI経由で利用する際に、事前に性能を予約できる「Provisioned Throughput」が使えるようになりました。
従来は ML.GENERATE_TEXT() や AI.GENERATE() を呼び出すたびに都度課金され、混雑状況に応じて応答速度が変わる可能性がありましたが、Provisioned Throughputにより、生成AIを使ったバッチ処理やアプリケーションで安定したスループットと予測しやすいコストでの運用が可能になります。
対応しているGeminiモデルの一覧については、公式ドキュメントを参照ください。
Icebergテーブルのマテリアライズドビュー対応が一般提供開始されました
BigQueryが外部Icebergテーブルに対して、マテリアライズドビューを作成できるようになりました。
Iceberg上のデータをBigQueryにコピーすることなく、クエリパフォーマンスの向上・コスト最適化を実現できます。
その他のアップデート
BigLake metastoreの機能拡張がプレビューになりました
Apache Iceberg RESTカタログを利用できるようになり、オープンソースエンジン(例えばApache Sparkなど)からCloud Storage内のIcebergデータへの直接アクセスが可能になりました。
既にCloud StorageにIceberg形式でデータを保存している場合、それをBigQueryのエコシステムだけでなく、様々なオープンソースツールからも活用できるようになります。
Colab Enterpriseノートブックの機能拡張がプレビューになりました
Geminiによるコードの説明やエラーの修正支援が利用可能になりました。
これにより、複雑なSQLクエリやPythonコードの理解、デバッグ作業が効率化されます。
BigQueryコンソールでダークテーマがプレビューになりました
ユーザーの好みに応じた作業環境のカスタマイズが可能になります。
新しい配列操作関数がプレビューになりました
以下の配列操作関数が追加されました:
– `ARRAY_FIRST`: 配列の最初の要素を返す
– `ARRAY_LAST`: 配列の最後の要素を返す
– `ARRAY_SLICE`: 配列から連続する要素を取得
これらの関数により、配列データの操作がより直感的かつ効率的になります。
SQL翻訳機能の強化が一部一般提供開始・プレビューになりました
SQL翻訳機能(SQLトランスレータ)は、BigQuery Migration Serviceに含まれる機能の一つで、別のSQL言語のクエリをGoogleSQLクエリに変換する機能です。
Geminiによる強化が行われており、SQL移行プロジェクトの効率がより向上することが期待できます。
– Geminiベースの構成YAMLファイルでAI提案を生成(一般提供開始)
– バッチSQL翻訳後のGeminiベース提案を含む翻訳出力のレビュー機能(一般提供開始)
– インタラクティブSQL翻訳でのGeminiベース翻訳ルールの作成と適用(プレビュー)
本章の執筆者:片貝桃子(Data Analyst)
Snowflakeのニュースまとめ
2025年6月のSnowflake Summit 2025では、AIとオープンプラットフォーム化への大転換が発表されました。エンタープライズAIの民主化、オープンな相互運用性の全面的な採用、パフォーマンスとコスト管理の自動化という3つの主要テーマに沿って、100以上の機能が発表されました。
Snowflake Intelligence: 自然言語での対話型データ分析が提供されました
Snowflake Intelligenceは、ビジネスユーザーが自然言語を用いて企業のデータと対話するための新しい統合的な会話型エクスペリエンスです。ai.snowflake.comからアクセス可能で、構造化データだけでなく、Google DriveやSalesforce、Slackなどの非構造化ドキュメントに対してもクエリを実行できます。
複雑な質問への回答、視覚化の生成、アクションの提案まで行うインテリジェントなデータエージェントとして機能し、既存のセキュリティ制御、データマスキング、ガバナンスポリシーを自動的に継承します。間もなくパブリックプレビューが予定されています。
詳しい内容は公式ドキュメントを参照ください。
Cortex AISQL: SQLでのAI機能が導入されました
Cortex AISQL(パブリックプレビュー)は、AIとMLの機能を新しいネイティブ関数としてSQL言語に直接埋め込む機能です。アナリストは使い慣れたSQL構文を用いて、テキスト、画像、ドキュメントといったマルチモーダルデータに対して複雑な操作を実行できます。
新たに追加された主要な関数には、AI_FILTER、AI_CLASSIFY、AI_AGG、そしてインテリジェントなセマンティックJOINなどがあります。感情分析、ドキュメントの要約、画像の分類といったタスクが単一のクエリ内で完結し、個別のAI/MLツールやPythonパイプラインが不要になります。
詳しい内容は公式ドキュメントを参照ください。
Data Science Agent: MLワークフローの自動化のプレビューが開始されました
Data Science Agent(プライベートプレビュー)は、データサイエンティストの生産性を向上させるために設計されたエージェント型コンパニオンです。データ準備、特徴量エンジニアリング、トレーニングといった定型的なMLワークフローのステップを自然言語コマンドで自動化します。
これを補完するDocument AIでは、複雑なPDFから構造化データを抽出するためのスキーマを意識したテーブル抽出機能(パブリックプレビュー)が追加されました。
詳しい内容は公式ドキュメントを参照ください。
Apache Icebergサポートが大幅強化されました
Apache Icebergサポートの大幅な強化が発表されました。目玉機能のCatalog Linked Databases(間もなくパブリックプレビュー)により、SnowflakeはAWS GlueやDatabricks Unity Catalogなど任意のIceberg REST互換カタログと統合し、任意のIcebergテーブルに対して読み取りと書き込みの両方が可能になります。
その他の主要なアップデートには、宣言的なパイプラインを実現するDynamic Tables on Iceberg、IcebergテーブルでのVARIANTデータ型のサポート(プライベートプレビュー)、Merge on Read(プライベートプレビュー)などのパフォーマンス改善が含まれます。
詳しい内容は公式ドキュメントを参照ください。
UNION BY NAMEオペレーターが導入されました
このオペレーターを使用すると、行を位置ではなく名前で結合できます。ある入力には存在するが別の入力には存在しないカラムは、結合結果セットでNULL値が埋められます。
詳しい内容は公式ドキュメントを参照ください。
行レベル削除が有効なアンマネージドApache Iceberg™テーブルでのストリームがサポートされました
行レベル削除が有効なアンマネージドIcebergテーブルに対してストリームを作成できるようになりました。
詳しい内容は公式ドキュメントを参照ください。
その他のアップデート
Adaptive Compute: 自動化されたコンピュートサービスがプレビュー開始されました
Adaptive Compute(プライベートプレビュー)は、インフラ管理を抽象化する新しいタイプのコンピュートサービスです。ウェアハウスのサイジング、同時実行設定、そしてアカウント内の最適サイズの共有コンピュートリソースへのインテリジェントなクエリルーティングを自動的に処理します。パフォーマンスチューニングとコスト最適化に通常必要とされる手作業と専門知識をなくすことを目標としています。
詳しい内容はリンクを参照ください。
Standard Warehouse Generation 2 (Gen2)が提供開始されました
Gen2は、アップグレードされたハードウェアを利用し、追加のパフォーマンス強化を含むSnowflakeのStandard Warehouseの更新版です。クエリパフォーマンスが大幅に向上し、Snowflakeは過去1年間でコアな分析ワークロードにおいて平均2.1倍のパフォーマンス向上を報告しており、DELETE、UPDATE、MERGE操作も改善されています。移行にはコードの変更は不要です。
詳しい内容は公式ドキュメントを参照ください。
Malicious IP Protectionサービスが提供開始されました
Malicious IP Protectionサービスは、すべてのSnowflakeアカウントを自動的に保護し、既知の悪意のあるIPアドレスからのネットワークアクセスやログイン試行をブロックします。このサービスはデフォルトで有効になっており、管理者による設定は不要です。
詳しい内容は公式ドキュメントを参照ください。
セマンティックビューの定義が一般提供開始されました
セマンティックモデルに対応するスキーマレベルのオブジェクトであるセマンティックビューを定義する機能が一般提供されました。セマンティックビューは、SQLコマンド(例: CREATE SEMANTIC VIEW)や、SnowsightのCortex Analyst Semantic View Generatorを使用して作成・管理できます。LLMの推論とルールベースの定義を組み合わせることで、応答の精度を向上させることができます。
詳しい内容は公式ドキュメントを参照ください。
セマンティックビューのクエリがプレビュー開始されました
セマンティックビューをクエリする機能がプレビューとして利用可能になりました。SELECTステートメントでSEMANTIC_VIEW句を使用し、取得したいディメンションやメトリックを指定できます。結果をディメンションに基づいてフィルタリングすることも可能です。
詳しい内容は公式ドキュメントを参照ください。
Snowpipe Streamingの高性能アーキテクチャがプレビュー開始されました
Snowpipe Streamingの新しい高性能アーキテクチャのプレビューが発表されました。これは大幅に強化されたスループットと最適化されたストリーミングパフォーマンスを提供し、予測可能なスループットベースの料金モデル(非圧縮GBあたりのクレジット)を採用しています。新しいSnowpipe Streaming SDKを使用し、データフロー管理用のPIPEオブジェクトを導入することで、取り込み中の軽量な変換とサーバーサイドスキーマ検証が可能になります。
詳しい内容は公式ドキュメントを参照ください。
Snowflake Horizonの外部データディスカバリがプライベートプレビュー予定となりました
Snowflakeの組み込みガバナンスソリューションであるSnowflake Horizonは、その範囲を拡大しています。外部データディスカバリ(間もなくプライベートプレビュー)により、HorizonはSnowflakeの外部にある資産、例えば他のリレーショナルデータベースやBIダッシュボード内の資産を発見し、統治できるようになります。これを補完するのが、自然言語を使用してガバナンスタスクを実行するためのCopilot for Horizon Catalog(間もなくプライベートプレビュー)です。
詳しい内容は公式ドキュメントを参照ください。
Snowflake Native App Framework関連のアップデートがされました
- 制限付き呼び出し元権限: ストアドプロシージャやSnowpark Container Servicesサービスが呼び出し元権限で実行できるものの、呼び出し元の特権は制限される機能がプレビューでサポートされました。 詳しい内容は公式ドキュメントを参照ください。
- 機能ポリシー: 消費者がアプリが作成できるオブジェクトの種類を制限できる機能ポリシーが導入されました(プレビュー)。例えば、アプリがウェアハウスを作成するのを禁止するポリシーを設定できます。 詳しい内容は公式ドキュメントを参照ください。
- Snowflake MLのサポート: Snowflake MLで作成されたモデルのサポートが追加されました(プレビュー)。プロバイダーは、事前トレーニング済みモデルへのアクセスをアプリに含めるか、アプリのインストール後にモデルをトレーニングできます。
詳しい内容は公式ドキュメントを参照ください。
開発者体験の向上に関するアップデートがされました
開発者のワークフローを改善するための一連のアップデートが発表されました。Snowpark Python用のArtifact Repositoryが一般提供(GA)となり、UDFやストアドプロシージャでのPyPIパッケージの使用が簡素化されました。
Snowflake CLIは、プライベートリンクでのログイン、OAuth、インタラクティブなSQLモードのサポートなど、数多くのアップデートを受けました。また、Snowflake Workspacesが、当初はdbtとSQL向けに、より統合された開発環境を提供するための新しいUIとして導入されました。
詳しい内容は公式ドキュメントを参照ください。
dbt ProjectsのネイティブサポートがSnowflakeに統合されました
Snowflakeはdbt Projectsのネイティブ統合を発表し、ユーザーはSnowflakeプラットフォームとSnowsight UI内で直接dbtデータパイプラインを構築、テスト、デプロイ、スケジュールできるようになりました。
この統合は新しいdbt Fusionエンジンによって強化されており、解析時間を最大30倍高速化し、ウェアハウスにクエリすることなくリアルタイムでSQLを検証できます。dbt Coreを別の環境で実行する必要がなくなり、開発ライフサイクルが合理化され、Snowflakeのガバナンス機能や可観測性機能と統合されます。
詳しい内容は公式ドキュメントを参照ください。
Snowflake Openflow: マネージドデータ統合サービスが発表されました
Snowflake Openflowは、構造化データ、リアルタイムストリーム、非構造化コンテンツを単一のプラットフォームで処理するために設計された、新しいフルマネージドのデータ統合サービスです。
オープンソースのApache NiFiプロジェクトに基づいて構築されており、膨大な数のコネクタライブラリを提供します。顧客のVPC内(BYOC)またはSnowflakeによる管理下でデプロイ可能で、高スループット(10GB/s)、低遅延(5秒のクエリレイテンシ)のAIワークロード向けに設計されています。
詳しい内容はリンクを参照ください。
本章の執筆者: 伊藤 雄(Software Engineer)
AWSのニュースまとめ
Athena マネージドクエリ結果が一般提供開始されました
S3 バケットの事前準備が不要となり、クエリ結果は暗号化された一時領域に自動保存・24 時間後に削除されます。バケット作成・権限設定・クリーンアップといった運用が不要となり、より迅速に分析を開始できます。
詳細は 公式 What’s New をご参照ください。
Glue Data Catalog 使用状況メトリクスが CloudWatch に公開されました
50 種類以上の API 操作が 1 分粒度の CloudWatch メトリクスとして自動的に可視化されるようになりました。API 制限超過を早期に検知できるため、アラーム設定や運用監視が強化されます。
詳細は 公式ブログ をご参照ください。
DynamoDB Zero-ETL が SageMaker Lakehouse と統合されました
DynamoDB の変更データをノーコードで Apache Iceberg テーブルに 15~30 分間隔でレプリケート可能になりました。本番処理に影響を与えず、履歴分析や AI モデル学習などのユースケースに活用できます。
詳細は 公式ブログ をご参照ください。
本章の執筆者: 海藤 公紀(Data Engineer)
Looker Studioのニュースまとめ
検索 API エンドポイントのパラメータの更新がありました
search API エンドポイントのレスポンスに previousPageToken が追加されました。このトークンにより、API ユーザーは検索結果を前後にページングできるようになります。
詳細は公式ドキュメントをご確認ください。
Lookerコネクタの機能強化がされました
Looker コネクタは、プライベート IP(Private Services Access)で構成された Looker(Google Cloud core)インスタンス、またはプライベート IP(Private Service Connect)で構成された Looker(Google Cloud core)インスタンス にLooker インスタンス IDを使用して接続できるようになりました。
詳細は公式ドキュメントをご確認ください。
「その他をグループ化」オプションが有効な場合、比較指標にはデータを表示しないようになりました
「その他をグループ化」オプションを比較指標と併用した場合、誤ったデータが表示されることがありました。この問題への対応として、チャートで「その他をグループ化」オプションが有効な場合、比較指標のフィールドには 「データなし」(no data)という文字列が表示されるようになりました。
本章の執筆者:若松 拓夢 (Data Analyst)
Looker Studio Proのニュースまとめ
Gemini in Looker がデフォルトで有効になりました
2025年6月3日以降に作成されたLooker Studio Proでは、Gemini in Lookerが自動的に有効化されます。適切な権限を持つユーザーは、「ユーザー設定」の「Gemini in Looker」ページで有効化を管理できます。
本章の執筆者:若松 拓夢 (Data Analyst)
dbtのニュースまとめ
Snowflake External OAuthがSemantic Layer queriesをサポートしました
OktaやMicrosoft Entra IDのような外部IDプロバイダー経由でdbt semantic layerを経由したSnowflakeへの操作が出来るようになりました、外部IDでSnowsightへSSOすることは従来から可能でしたが、今後は人がログインしないプログラマティカルな接続でもsemantic layerを利用できるようになります。
システムからのSnowflakeアクセス時にパスワード管理が不要となることでセキュリティ向上にも繋がりますし、それに加えて統一されたデータ定義のみの利用を強制するデータ品質担保にも繋がります。
dbt Fusion Engineがbeta版でDatabricksをサポートしました
従来はSnowflakeのみdbt Fusionエンジンを利用可能でしたが、対応DWHが一つ追加されました。
詳細は公式ドキュメントを参照ください。
本章の執筆者:河野浩明(Data Engineer)
Tableauのニュースまとめ
Tableau Cloud – VizQL Data Serviceが大幅アップデート、Python SDKが公開されました
パブリッシュ済みのTableauデータソースにプログラムで直接クエリできるAPI「VizQL Data Service (VDS)」が大幅に強化されました。特に、Python SDKが提供されたことは大きな進展です 。
このSDKにより、データエンジニアやデータサイエンティストは、使い慣れたPython環境から数行のコードでTableau上の信頼できるデータソースにアクセスし、データを取得・利用できます。
詳細は公式ドキュメントを参照ください。
Tableau Cloud – Map Viewport Parametersで動的な地理空間分析が可能になりました
マップの表示領域(ビューポート)を動的な空間パラメーターとして利用できるようになりました。ユーザーがマップを拡大・縮小したり、表示範囲を移動させたりする操作が、リアルタイムでパラメーターに反映されます 。
この機能により、ダッシュボード上の複数のマップを常に同じ表示領域で同期させたり、マップの表示範囲内にあるデータポイントのみを他のグラフに表示させたりといった、高度なインタラクションが可能になります。
詳細は公式ドキュメントを参照ください。
Tableau Cloud – 複数のSCIM構成がサポートされ、大規模組織のID管理が簡素化されました
Tableau Cloudの単一サイトで、複数のIdP(Identity Provider)に対するSCIM構成が可能になりました。これにより、例えばMicrosoft Entra IDとOktaを併用しているような大規模な組織でも、ユーザープロビジョニングを一元管理できます 。
これまではIdPごとにTableauサイトを分ける必要がありましたが、本機能により単一サイトへの統合が可能となり、ガバナンスの簡素化とコンテンツ共有の促進が期待できます。M&A後のシステム統合や、複数の事業部門が異なるIdPを運用している場合に特に有効です。
詳細は公式ドキュメントを参照ください。
Tableau Cloud – Tableau Embedding API v3でReactコンポーネントが公式提供されました
WebアプリケーションにTableau Vizを組み込むための「Embedding API v3」が更新され、公式のReactコンポーネントライブラリ (tableau-embedding-react) がリリースされました 。
フロントエンド開発で圧倒的なシェアを誇るReactにネイティブ対応したことで、開発者はラッパーコードを自作することなく、Tableau VizをモダンなWebアプリケーションに効率的に組み込めるようになります。
詳細は公式ドキュメントを参照ください。
その他アップデートは公式リリースダッシュボードを参照ください。
本章の執筆者:中山愛弓(Data Analyst)
Databricksのニュースまとめ
マネージドApache Icebergテーブルがプレビューになりました
Databricks上でApache Iceberg形式のマネージドテーブルが作成できるようになりました。
予測最適化やリキッドクラスタリングといったDatabricksの最適化機能も適用できます。
また、Iceberg REST Catalog APIを使って外部のIcebergエンジンからもテーブルの読み書きが可能です。
フォーリンApache Icebergテーブルがプレビューになりました
レイクハウスフェデレーションを使って、GlueやSnowflakeといった外部で管理されているIcebergテーブルを読み込むことができるようになります。
AI Gatewayが一般提供開始されました
AI Gatewayは生成AIモデルとそれに関連するモデルサービングエンドポイントへのアクセスを管理および監視するための機能です。
モデルを提供するエンドポイントに対して、以下の機能を通じてガバナンス、監視、本番環境への対応を強化します。
- 権限とレート制限: 誰がどの程度アクセスできるかを制御
- ペイロードロギング: 推論テーブルを利用して、モデルAPIに送信されるデータを監視・監査
- 使用状況の追跡: システムテーブルを使い、エンドポイントの運用状況や関連コストを監視
- トラフィックルーティング: 複数のモデル間でトラフィックの負荷を分散
- 外部モデルのフォールバック: デプロイ中やデプロイ後の本番環境での障害を最小限に
Lakebaseがプレビューになりました
LakebaseはPostgreSQL互換のマネージドOLTPデータベースです。これにより、トランザクションワークロードと分析ワークロードを同一プラットフォーム上で実行できます。
Deployment jobsがプレビューになりました
Unity CatalogのモデルとLakeflow Jobsをシームレスに統合し、新しいモデルバージョンが作成された際に評価、承認、デプロイといったタスクを自動化できるようになります。
ファイル到着トリガーが一般提供開始されました
S3などのオブジェクトストレージにファイルが到着したことを検知してジョブ実行をトリガーできます。
新しいデータの到着が不規則な場合など、スケジュール実行が非効率な場合に有用です。
自動リキッドクラスタリングが一般提供開始されました
Unity Catalogのマネージドテーブルにおいて、クエリのワークロードを自動的に分析し、データレイアウトを最適化するためのクラスタリングキーをインテリジェントに選択・適用することでクエリのパフォーマンスを最適化します。
本章の執筆者:今川航(Data Analyst / Analytics Engineer)
TROCCO®のニュースまとめ
転送設定: Shopify GraphQL APIを用いた転送元Shopifyが追加されました
Shopify REST Admin APIがレガシーAPIとなったことに伴い、 Shopify GraphQL APIを用いた転送元Shopifyをリリースしました。
詳しくは、転送元 – Shopifyを参照ください。
コネクタ新規リリース: 転送元コネクタが追加されました
以下の転送元コネクタが追加されました。
- 転送元Airtable
- 転送元Calendly
- 転送元freee人事労務
- 転送元Kairos3 Marketing
- 転送元Kairos3 Sales
- 転送元Klaviyo
- 転送元Rollbar
- 転送元Talentio
- 転送元Zendesk Sell
コネクタ新規リリース: 転送先コネクタが追加されました
以下の転送元コネクタが追加されました。
- 転送先Google Ads カスタマーマッチ
- 転送先LINE広告 カスタムオーディエンス
転送設定: 転送元Snowflakeでクエリのプレビューができるようになりました
転送元Snowflakeにて、クエリのプレビューが可能になりました。クエリで取得対象となる転送データを事前に確認できるようになりました。
転送設定: データのプレビューをもとに推測してJSONカラムを展開できるようになりました
これまで、JSONカラムを展開する場合は、展開したいJSONのキーごとにそれぞれカラムを定義する必要がありました。
今回のリリースにより、データのプレビューの情報から推測してJSONカラムを展開できるようになりました。
UI・UX: 転送ジョブ詳細画面で、実行に利用した転送設定のリビジョンを確認できるようになりました
転送ジョブ詳細画面で、ジョブの実行に利用した転送設定のリビジョンを確認できるようになりました。
リビジョンのリンクをクリックすると、転送設定の変更履歴にて対象リビジョンの詳細を確認できます。
コネクタAPIアップデート: 転送元Google Ad Manager
転送時に使用するGoogle Ad Manager APIのバージョンを、 v202408からv202502へアップデートしました。
新バージョンについては、Google Ad Manager APIを参照ください。
コネクタAPIアップデート: 転送元Box
転送時に使用するBox Java SDKのバージョンを、v4.0.0からv4.16.1へアップデートしました。
新バージョンについては、Box Java SDKのGitHubリポジトリを参照ください。
お知らせ: 一部プランでお支払い方法にクレジットカードを利用可能になりました
FreeプランからStarterプランへの変更時に、お支払い方法としてクレジットカードを利用できるようになりました。
Terraform Provider for TROCCO: 転送設定・接続情報の対応リソースが拡充されました
Terraform Provider for TROCCOが新たに以下のリソースに対応しました。
- 転送設定(trocco_job_definition)
- 転送元 – HTTP
本章の執筆者:西山徹(Senior Product Manager)
COMETAのニュースまとめ
料金プランが変更され、利用可能ユーザー数が無制限になりました
これまではユーザー数により料金が変動していましたが、7月1日以降のご契約について、利用可能ユーザー数が無制限になりました。あわせて、COMETA AIの機能がGAになり、COMETA AI機能の実行回数による料金モデルが追加されました。
詳細についてはCOMETAのウェブサイトをご確認ください。
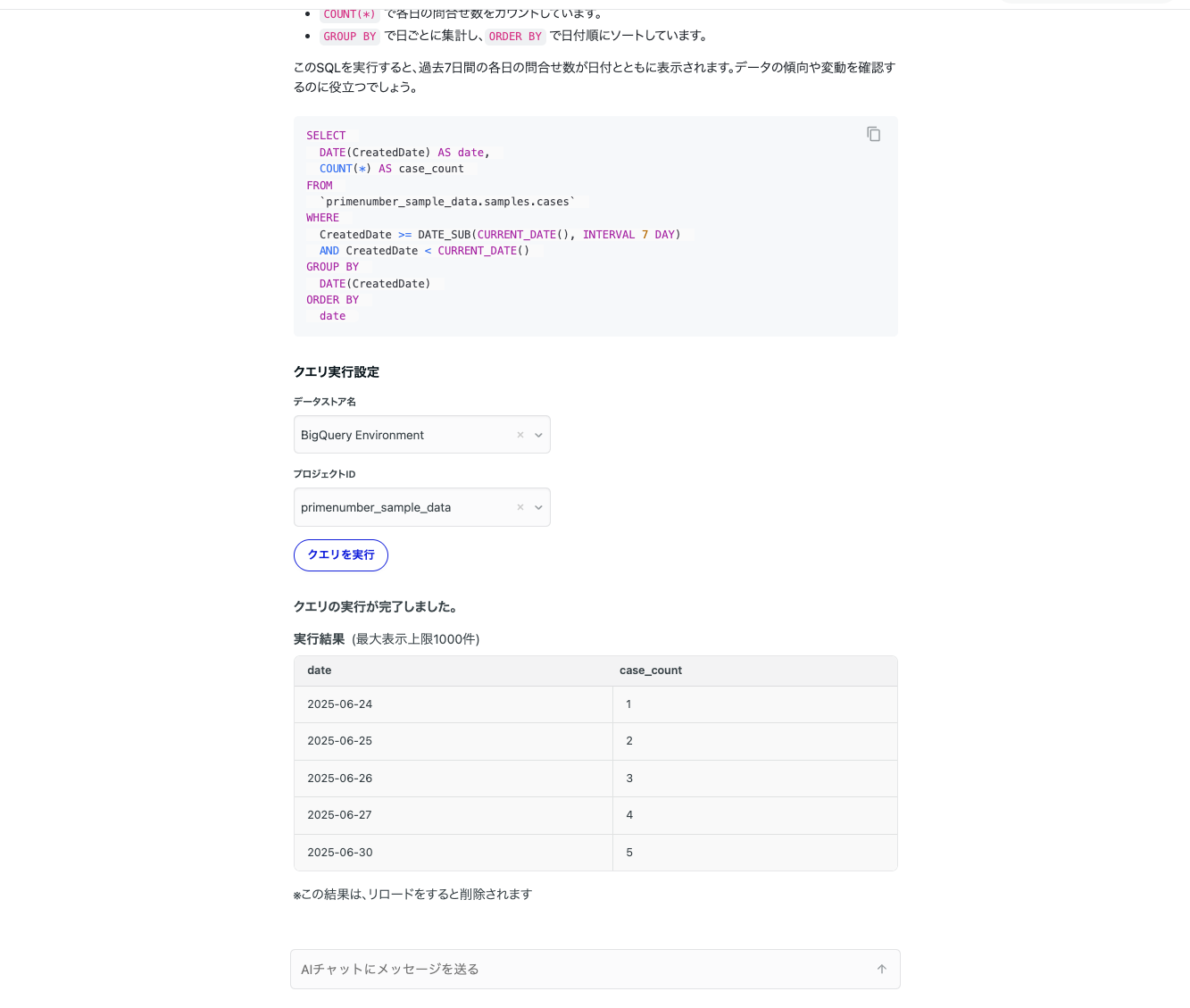
対話型AIアシスト機能で生成されたSQLをそのままUI上から実行してデータを取得できるようになりました
当該機能により、AIとの対話の中でスムーズにデータを確認でき、外部画面へ遷移してクエリを実行する手間を省けます。利用するには、ユーザーは実データ閲覧ロールを持ち、対象のDWHに対する認証情報を登録している必要があります。
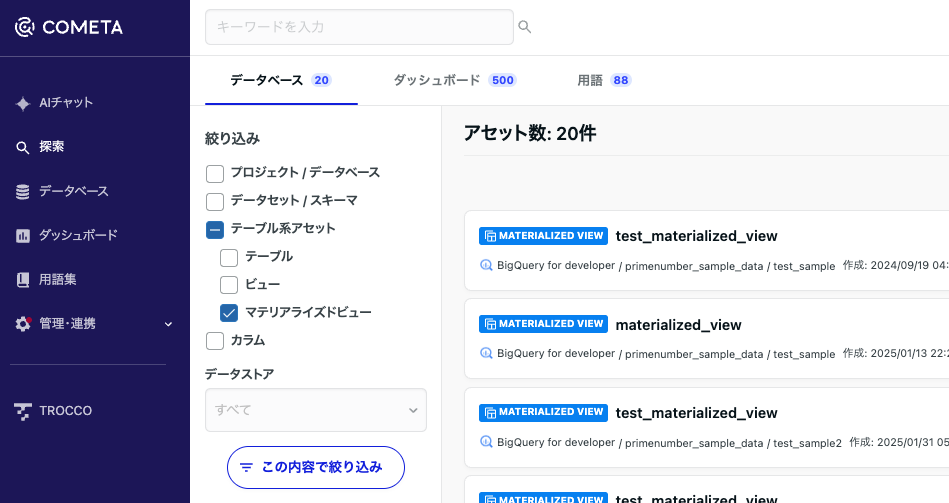
アセット検索画面でビューとマテリアライズドビューをフィルタできるようになりました
これまでは、テーブルのみのフィルタを提供しており、ビューやマテリアライズドビューをまとめて検索する機能のみが提供されていました。こちらのリリースにより、より詳細なフィルタ条件を指定できるようになり、目的のアセットに簡単に辿り着くことができます。
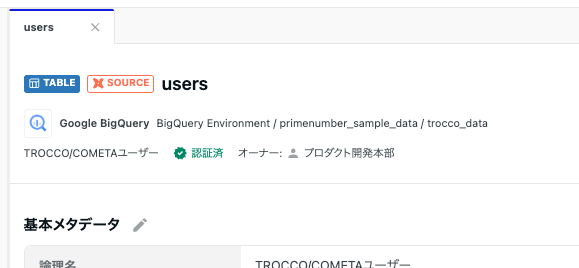
基本メタデータの項目としてオーナーとステータスを管理できるようになりました
カラムやテーブルなどのアセットに関して、基本メタデータの項目としてオーナーとステータスを管理できるようになりました。
この機能により、このアセットの管理者は誰で困った時に連絡する先は誰か、またこのアセットは利用が(非)推奨されているかなど、アセットの状況を管理することができ、不適切なデータ活用を防ぎ、データ活用を推進することができます。
オーナーとステータスはスキーマ(データセット)についても指定可能で、未設定の場合は親のアセットの設定を引き継ぎます。
対話型AIアシスト機能でチャットの履歴が確認できるようになりました
これまでは毎回新規のチャットを作成するごとにチャットがリセットされ、過去のチャットが確認できませんでした。こちらの機能により、過去に行ったAIとのチャットが確認できるようになり、探索したアセットや生成したSQLを後から振り返られるようになりました。
本章の執筆者:廣瀬智史(Staff Product Manager)
Data Engineering Newsは毎月更新でお届けいたします。
記事公開の新着メール通知をご希望の方はこちらのフォームよりご登録ください。ル通知をご希望の方はこちらのフォームよりご登録ください。
」-――-Gartnerが警告する2026年のBtoBマーケティング-2.png)




