
BigQueryは、データ分析基盤の構築に欠かせない、サーバーレスなクラウド型DWH(データウェアハウス)です。Googleの大規模分散処理技術を活かした高速クエリや、柔軟にスケールするストレージ、従量課金による高いコスト効率などが特徴で、世界中の企業に幅広く採用されています。
今やDWHの中でも代表的となったBigQueryですが、「興味はあるけれど何から学べばよいか分からない」「ツールの全体像が掴めていない」と感じている方も多いのではないでしょうか。
本記事では、そうした疑問を解消すべく、BigQueryの概要や基本的な操作、データ基盤のイメージを解説します。BigQueryの全体像を把握し、より迅速で正確なデータ活用を実践しましょう。
BigQueryとは?
BigQueryは、Google Cloudが提供するクラウド型のDWH(データウェアハウス)です。
BigQueryは、データを格納するDWHとしての基本的な機能に加え、保存したデータに対して即座にクエリを実行する機能を備えています。画面を切り替えることなく、クエリの作成や実行を行えるため、効率的にビッグデータ分析やリアルタイム分析を行うことが可能です。
近年はAIを活用した分析機能も強化され、自律型データAIプラットフォームへの進化を遂げています。これにより、データの取り込みからAIによる分析、アクションまで、データライフサイクル全体を自動化できます。
BigQueryの主な特徴
BigQueryには、いくつかの選ばれる理由があります。ここでは、他のクラウド型DWHと差別化されるBigQueryの特徴を3つご紹介します。
高速処理
BigQueryは、高速なクエリ処理が特徴です。この背景には、Googleが開発した大規模分散処理基盤「Dremel」の技術があります。
Dremelは、クエリを何千ものサーバーに同時に分散する「ツリーアーキテクチャ」と、データを列単位で格納する「カラム型データストア」の2つの技術を組み合わせています。これにより、大規模分散処理やトラフィック最小化を両立し、膨大なクエリデータであっても高速処理が可能です。
実際に、マーケティングデータやログデータなどのような膨大なデータでも、BigQueryは数秒〜数分で処理を完了できます。ストリーミング機能を活用すればリアルタイム分析が可能となり、クエリの実行速度を飛躍的に向上させられます。
完全マネージド型のアーキテクチャ
BigQueryは、サーバレスで提供される完全マネージド型のDWHです。Google側が全てのリソース管理を行うため、ユーザーはインフラの構築や管理を意識せずに利用できます。
たとえば、サーバレス設計の恩恵として、仮想マシンやコンテナの作成、実行環境の起動・停止といった作業が不要になります。また、処理負荷に応じてコンピューティングリソースを自動で増減させる「自動スケーリング」の仕組みにより、ユーザーがあらかじめ「何コア必要か」「何台のノードが必要か」を設定する必要がありません。
したがって、ユーザーの運用負荷を大幅に軽減でき、データ活用に集中できるようになります。また、導入時の初期設定が簡単なため、スムーズに運用を開始できます。
Googleの他サービスとの連携が容易
BigQueryは、Google Cloud内のさまざまなサービスとシームレスに連携できる点も大きな強みです。これにより、データの取り込みから分析、可視化、機械学習まで、統一された環境で効率よく業務を進められます。
たとえば、Cloud Storageと連携すれば、大量のCSVやJSONデータを即座に分析基盤へ取り込めます。また、Vertex AIと組み合わせれば、BigQuery MLを使って構築したモデルをすぐに予測へ活用することも可能です。
さらに、GoogleスプレッドシートやGA4などのサービスともシームレスに連携できるため、既に自社内でGoogleのサービスを利用している企業におすすめです。
BigQueryの導入前に知っておくべきポイント
ここでは、BigQueryの導入・運用にあたって理解しておくべきポイントをご紹介します。
BigQueryの基本概念
BigQueryでは、SQLを使用してクエリを実行します。クエリを正しく実行するためには、データの格納場所やリソース構造を理解することが重要です。
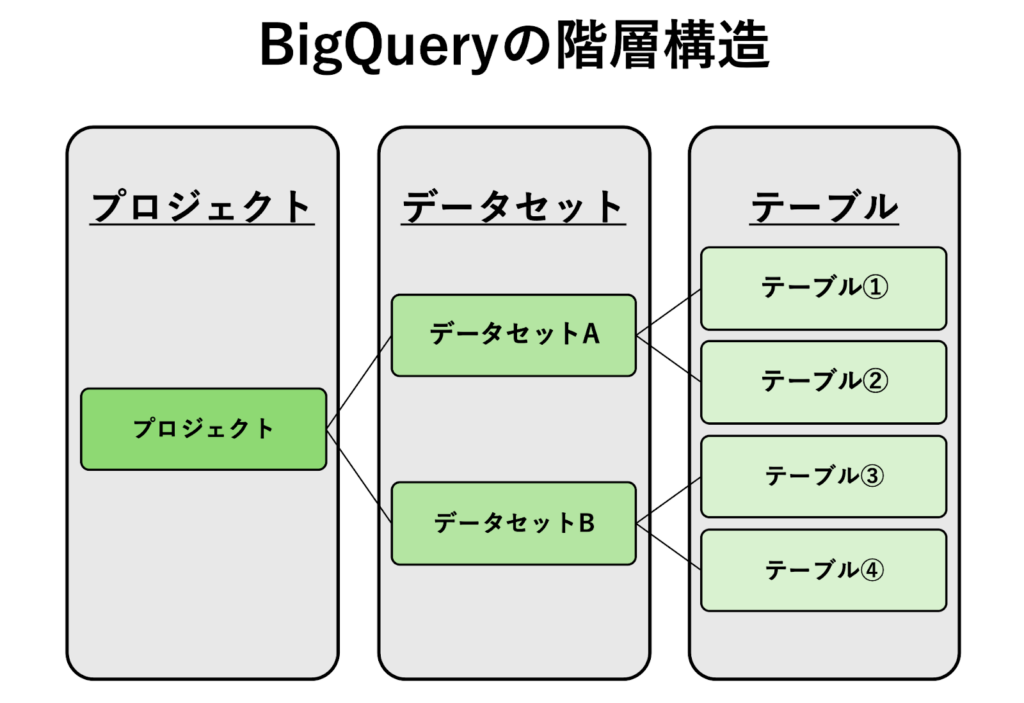
BigQueryの構造は、以下の3要素による階層構造になっています。
- プロジェクト
BigQueryにおける最上位の管理単位であり、リソース管理と課金の基準となります。プロジェクトには一意のIDが割り当てられ、すべてのデータセットやテーブルは、特定のプロジェクトの中に作成されます。 - データセット
テーブルやビューをグループ化するためのコンテナのような存在です。データを整理・分類するために用いられ、「売上データ」「マーケティングデータ」など、用途や部署ごとに分けて管理できます。アクセス権限の設定はデータセット単位で行います。 - テーブル
実際のデータが格納されている場所で、リレーショナルデータベースと同様に行と列で構成されます。クエリの対象はこのテーブルであり、ユーザーはSQL文を使ってテーブルの中のデータを検索・集計・分析します。
BigQueryの料金モデル
BigQueryの料金は、コンピューティング料金とストレージ料金の2種類です。それぞれの詳しい料金モデルは以下の通りです。
コンピューティング料金
コンピューティング料金とは、クエリの実行によって発生する料金のことです。クエリで処理されたデータ量(TiB単位)で課金される「オンデマンド料金モデル」か、クエリの実行に使用されたコンピューティング容量(スロット時間単位)で課金される「容量ベースの料金モデル」を選択できます。
オンデマンド料金モデルでは、クエリで処理されるデータは毎月1TiBまで無料で、それ以降は1TiBあたり$7.5が加算されます。(Tokyoリージョンの場合)
容量ベースの料金モデルでは、エディションごとに料金が異なります。エディションは、「Standard」「Enterprise」「Enterprise Plus」の3種類です。また、それぞれのエディションにおいて、従量課金制と1年・3年の契約期間による割引料金が提供されています。ただし、Standardエディションでは、契約期間による割引価格は提供されていません。
たとえばTokyoリージョンの場合、以下のような料金モデルとなります。
| Standard | Enterprise | Enterprise Plus | |
| 従量課金制 | $0.051 / slot hour | $0.0765 / slot hour | $0.1275 / slot hour |
| 1年契約 | – | $0.0612 / slot hour | $0.102 / slot hour |
| 3年契約 | – | $0.0459 / slot hour | $0.0765 / slot hour |
ストレージ料金
ストレージ料金は、BigQueryに読み込んだデータを保存する料金のことです。特定の期間において、テーブルに保存されているデータの量に応じて課金されます。
たとえばTokyoリージョンの場合、以下のような料金モデルとなります。ただし、毎月10GiBまでは無料です。
| ストレージの種類 | 料金 |
| 論理ストレージ(アクティブ) | $0.023 / GiB/月 |
| 論理ストレージ(長期保存) | $0.016 / GiB/月 |
| 物理ストレージ(アクティブ) | $0.052 / GiB/月 |
| 物理ストレージ(長期保存) | $0.026 / GiB/月 |
| メタデータストレージ | $0.052 / GiB/月 |
無料で利用できる範囲まとめ
以下の範囲であれば、無料かつクレジットカード登録不要でBigQueryを試用できます。
| コンピューティング(クエリ処理) | 1TiB/月まで |
| ストレージ | 10GiB/月まで |
BigQueryと他DWHの比較
BigQuery以外の代表的なDWHとしては、以下のようなサービスが挙げられます。
- Amazon Redshift
- Azure Synapse Analytics
- Snowflake
BigQueryとその他のサービスの違いは以下の通りです。
| BigQuery | Redshift | Synapse | Snowflake | |
| 処理能力 (TPC-H SF100ベンチマーク) | 2分16秒 | 平均3〜4分(Redshift Serverlessを使用) | 8〜11分(Synapse Serverlessを使用) | 2分59秒(単一ノード) |
| アーキテクチャの特徴 | ・完全サーバーレス ・Dremelエンジン | ・RA3ノード ・列指向ストレージとMPP処理の組み合わせ | SQL Pool+Spark Poolの統合 | ・三層分離 ・マルチクラウド・マルチクラスタシェアードデータ |
| 拡張方法 | 完全自動スケーリングが可能 | 手動/自動両方に対応 | DWU単位での性能調整が可能 | 秒単位での非破壊的スケーリングが可能 |
| 親和性の高いサービス | GCP | AWS | ・Azure ・その他Microsoft製品 | GCP、AWS、Azure |
(参考文献:
・Benchmarking , Snowflake, Databricks , Synapse , BigQuery, Redshift , Trino , DuckDB and Hyper using TPCH-SF100

・Cloud Analytics Benchmark
https://vldb.org/pvldb/vol16/p1413-renen.pdf
各DWHの特徴を正しく理解し、自社の要件に適したサービスを選択できるようにしましょう。
BigQueryの始め方
BigQueryを無料で始める方は、まずGoogle CloudのBigQuery登録用サイトにアクセスします。サイトにアクセスしたら、「無料で開始」をクリックします。
国を選択して、「同意して続行」をクリックします。
お支払い方法を選択して、「無料で利用開始」をクリックします。
これでBigQueryの利用設定は完了です。
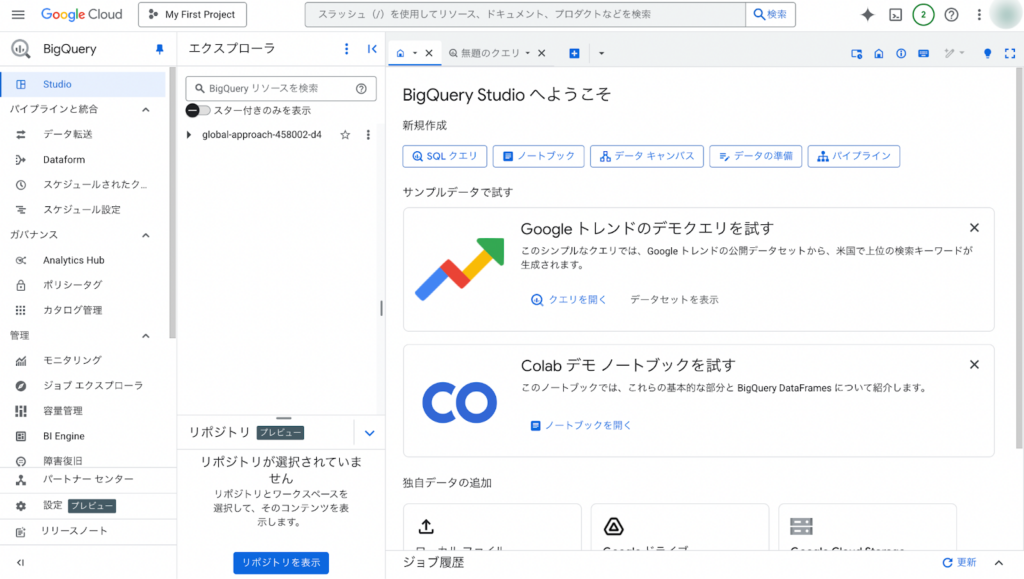
BigQueryの基本操作
ここでは、BigQueryでクエリを実行するまでの基本的な操作をご説明します。
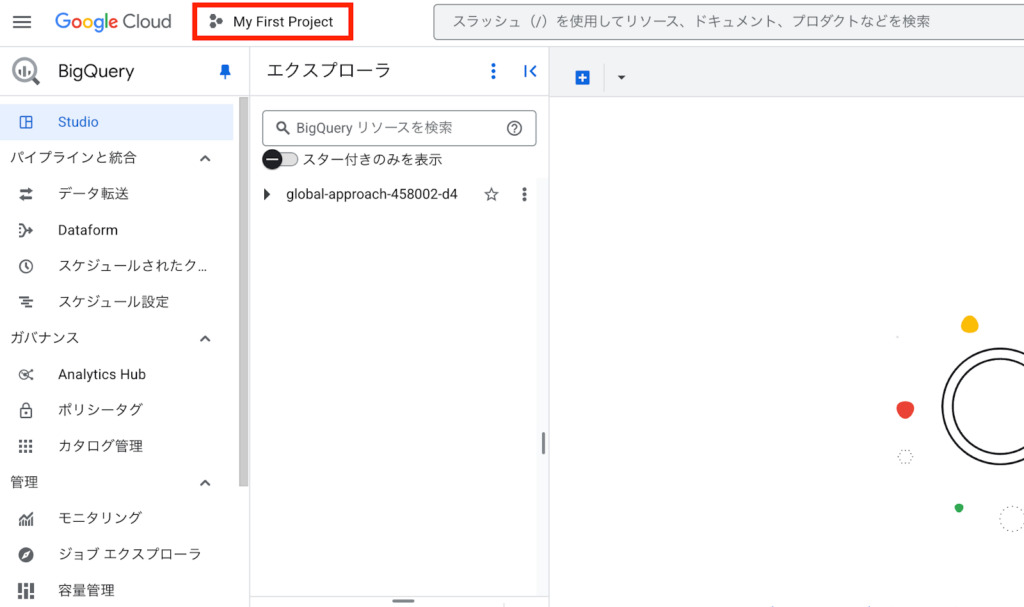
プロジェクトの作成
BigQuery Studioから、画面上部の「My First Project(マイファーストプロジェクト)」をクリックします。
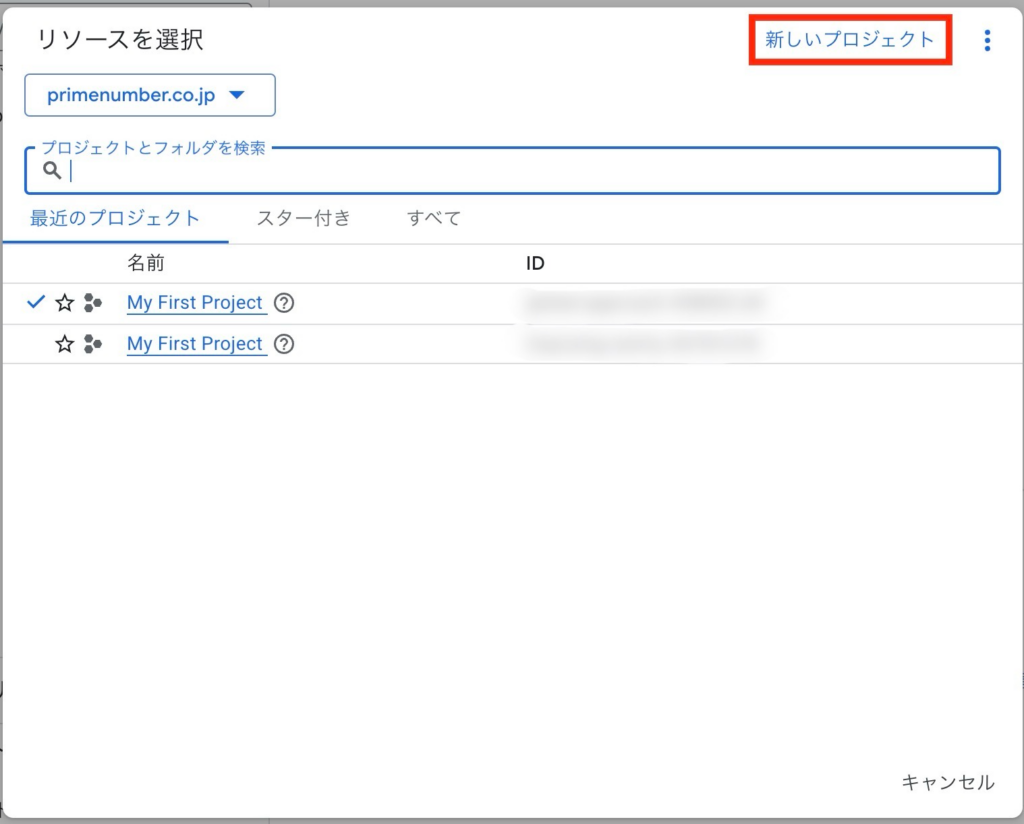
「新しいプロジェクト」をクリックします。
「プロジェクト名」を入力し、「組織」「場所」を選択します。
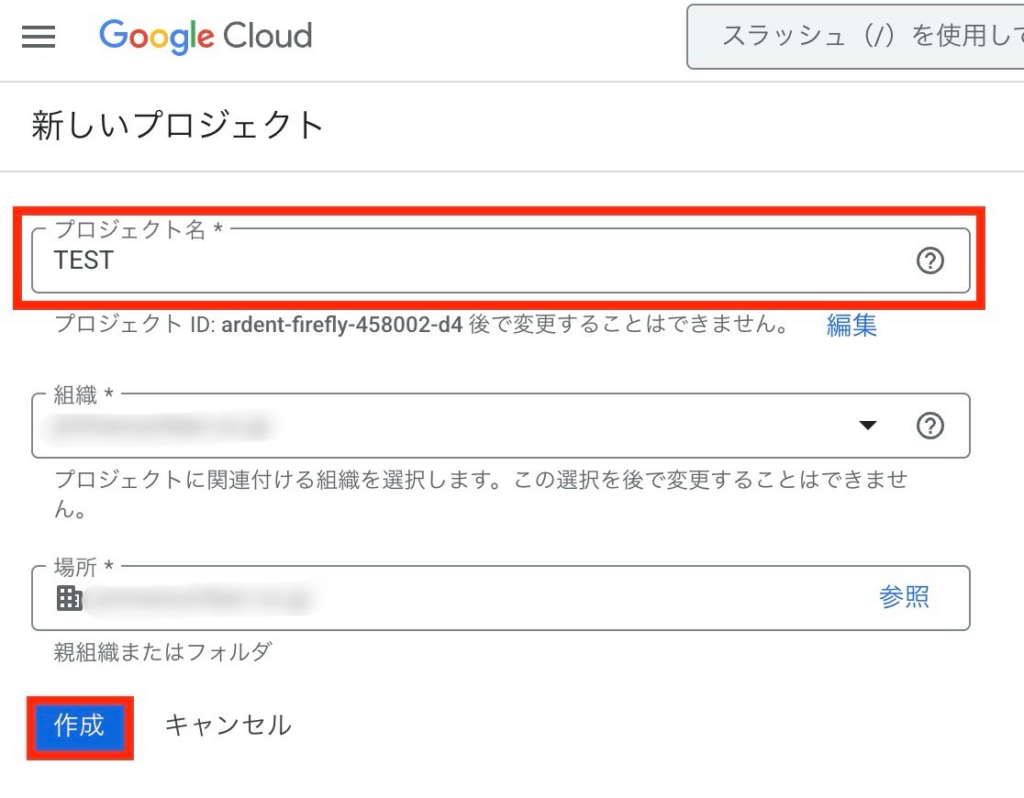
これでプロジェクトの作成は完了です。
データセットの作成
事前に用意したプロジェクトの中にデータセットを作成します。
左側のエクスプローラーには、作成したプロジェクトのIDが表示されています。そのIDの右側にある「︙」をクリックし、「データセットを作成」を選択します。
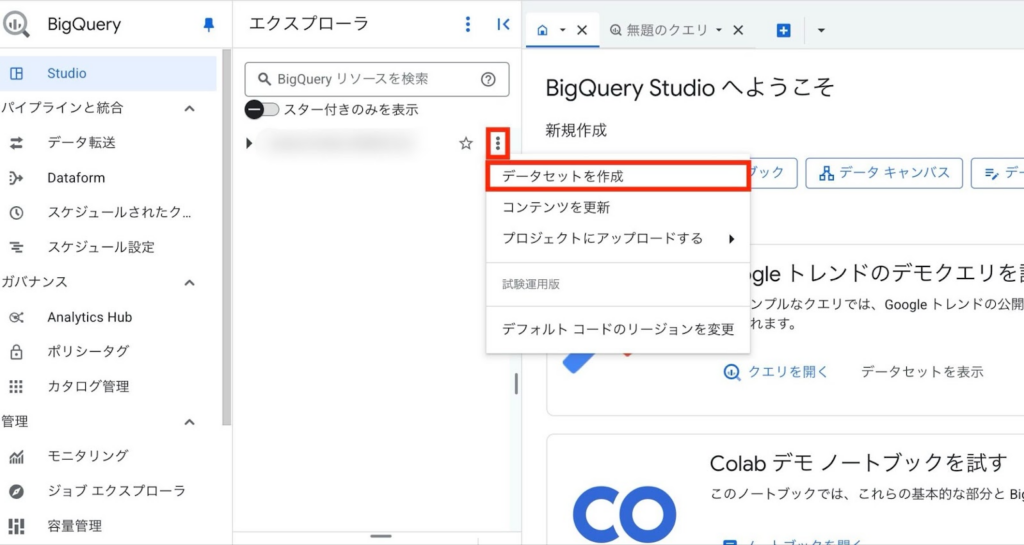
「データセットID」を入力し、「ロケーションタイプ」を選択します。必要に応じて詳細オプションを選択し、「データセットを作成」をクリックします。
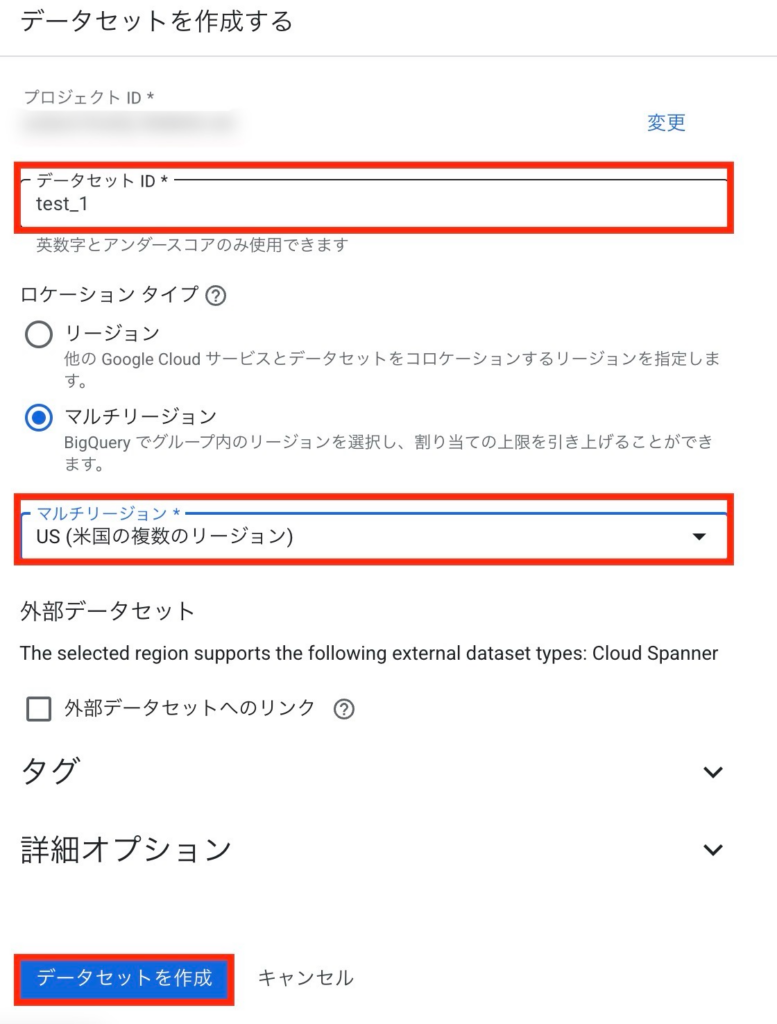
これでデータセットの準備は完了です。
テーブルの作成・データのロード
事前に用意したデータセットの中にテーブルを作成し、実際にデータをロードします。ここでは、データのロード方法別に手順を説明します。
バッチを利用した取り込み
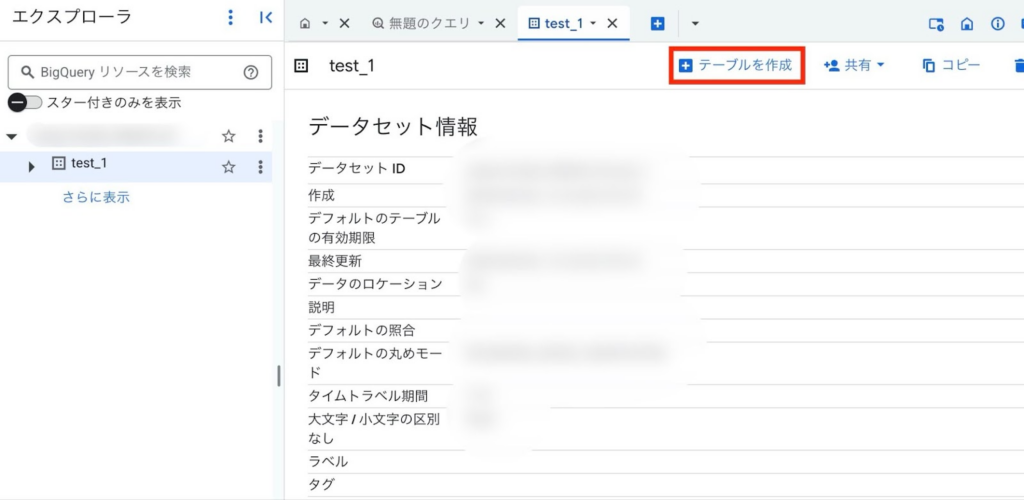
対象のデータセットを選び、画面右上の「テーブルを作成」をクリックします。
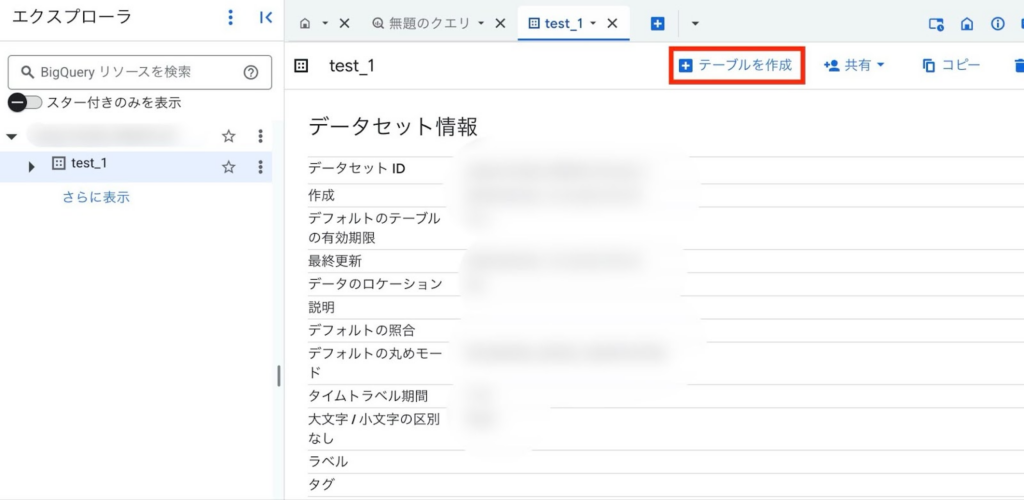
テーブルの作成元を選択します。ここでは、ローカルのファイルからデータをロードします。アップロードするとファイル形式が自動で入力されるため、正しい形式であることを確認します。
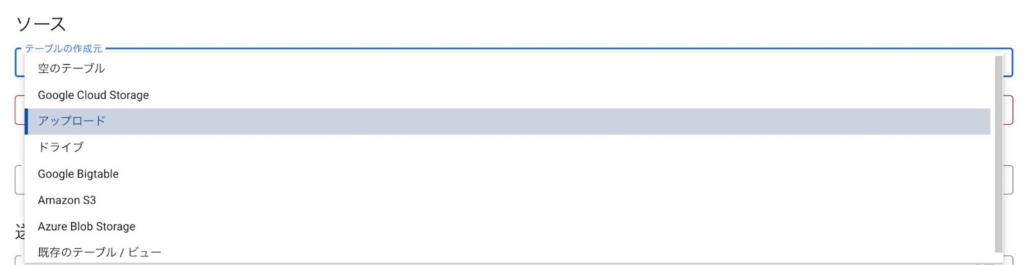

送信先として、事前に用意したプロジェクトとデータセットを選び、テーブル名を入力します。

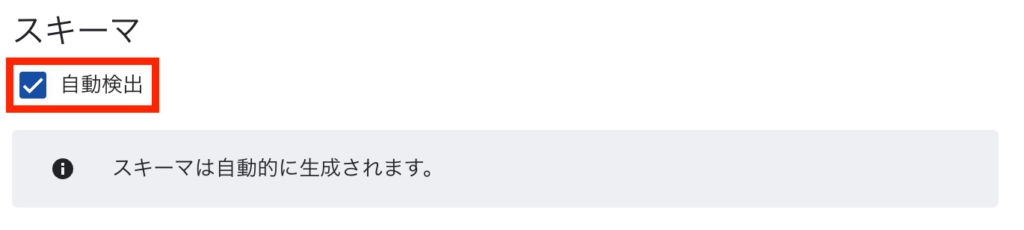
スキーマについては「自動検出」にチェックを入れると、フィールドが自動生成されます。
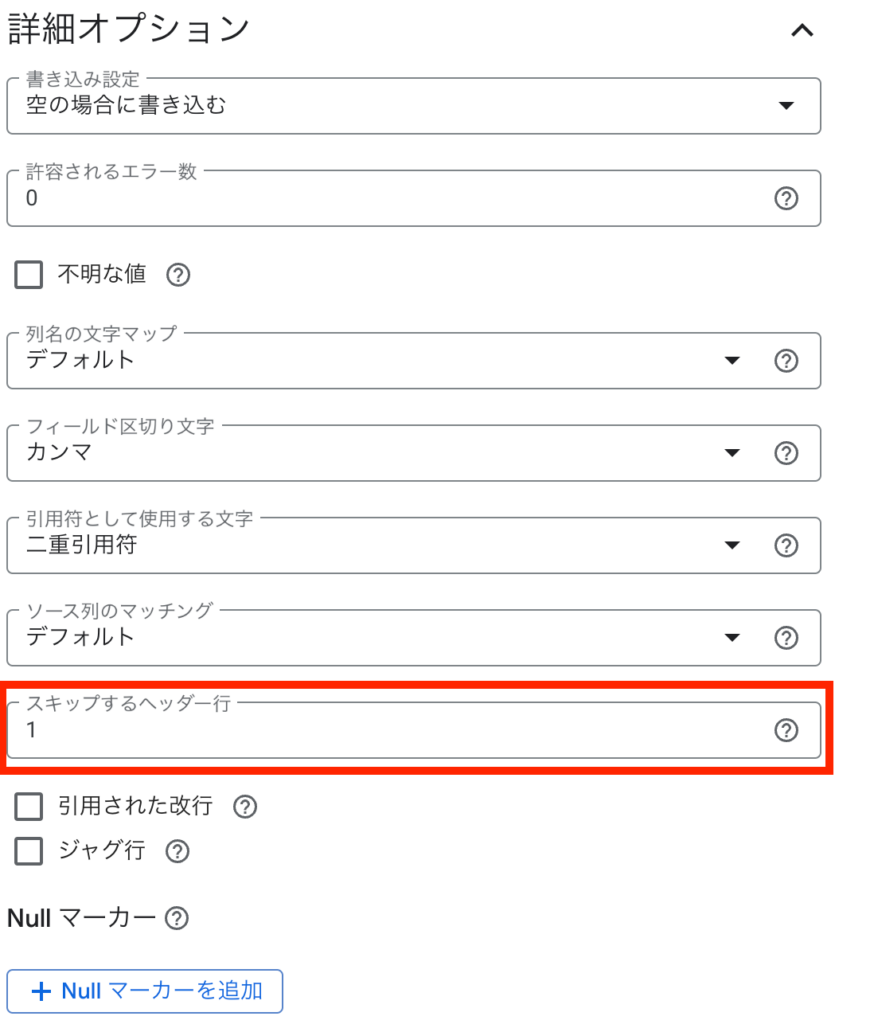
必要に応じて、詳細オプションを設定します。たとえば、ロードしたファイルの一行目がタイトル行となっている場合は、「スキップするヘッダー行」を「1」とします。
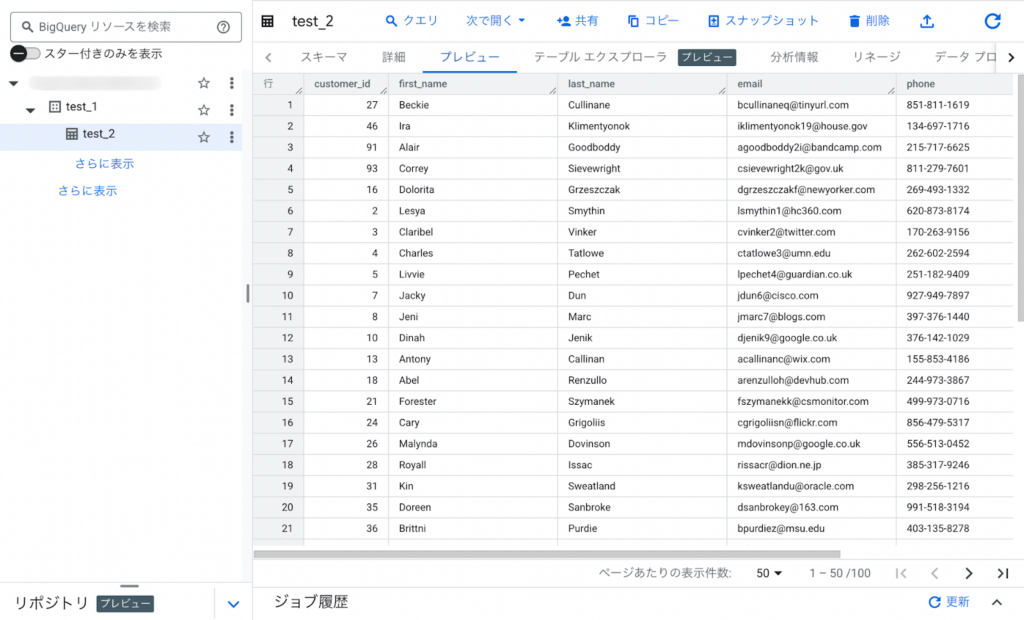
すべての設定が完了したら「テーブルを作成」をクリックします。プレビュー画面でデータの詳細を表示し、正常にロードできているか確認しましょう。
ストリーミングを利用した取り込み
InsertAll APIやStorage Write APIなど、BigQueryが提供するAPIを用いて直接データを取り込むことが可能です。この方法によるデータの取り込みは、主に以下のような手順で行います。
- BigQuery上でテーブルを作成する
- APIクライアントをインストールする
- 作成したテーブルのIDを指定して、データを送信する
(Storage Write APIの場合、専用のWriteStreamを確立してデータを書き込む)
詳細については、以下の公式ドキュメントをご覧ください。
また、Pub/Subを利用してロードする方法もあります。とくに、大規模なデータをリアルタイムに扱いたい場合は、Dataflowとの併用が効果的です。この方法では、一旦データをPub/Subへ送信し、その後Dataflowでデータを変形・加工してBigQueryへ書き込みます。
詳細については、以下の公式ドキュメントをご覧ください。
Pub/SubとDataflowを利用したストリーミングの取り込み
外部データソースとの連携
バッチを利用したデータの取り込みと同様、「テーブルの作成」をクリックします。
次に、データソースとして「Google Cloud Storage」「ドライブ」「Google Bigtable」のいずれかを選択します。
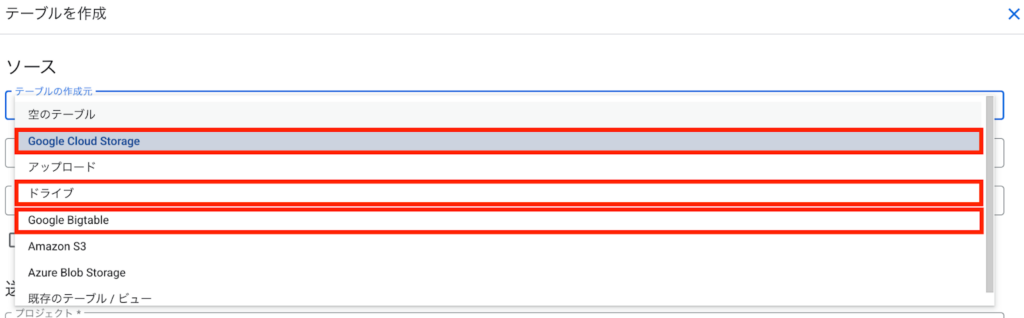
これにより、データをBigQueryに取り込まずに、外部のストレージやデータベースと直接連携してクエリを実行できます。以降の操作は、バッチを利用したデータの取り込みと同様です。
BigQueryを用いたデータ基盤の構築
迅速かつ正確な意思決定を行うためには、堅牢で拡張性のあるデータ基盤が欠かせません。ここでは、BigQueryを中心に据えたデータ基盤の概要と、構築の加速させる実践的なポイントを解説します。
データ基盤構築におけるBigQueryの活用イメージ
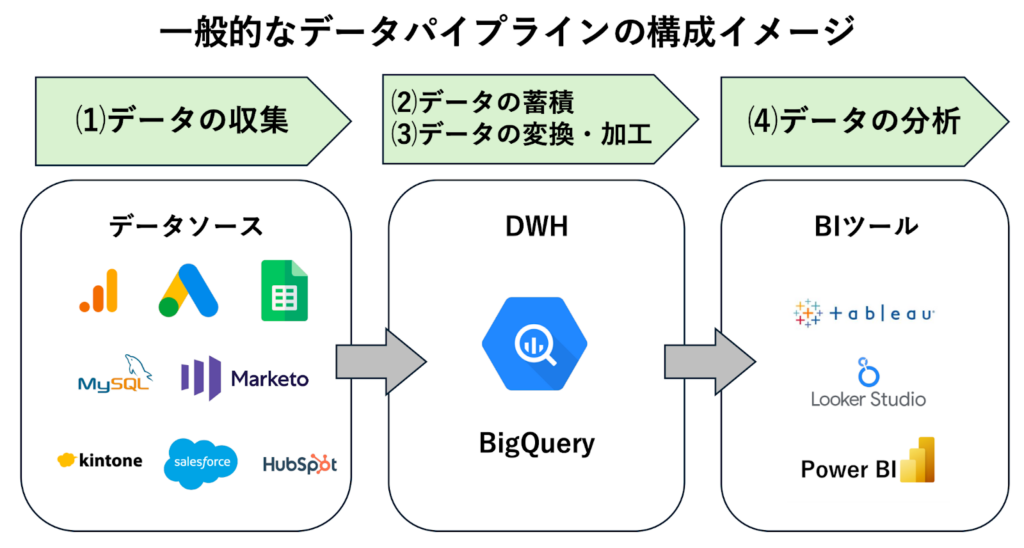
一般的にデータ基盤は、「収集」「蓄積」「加工」「分析」の要素で構成されます。
まず、社内外に点在するさまざまなシステムやサービスからデータを収集し、DWHへ集約します。BigQueryでは、BigQuery Data Transfer Serviceを使い、GA4やGoogle広告などのGoogleサービスからデータを自動で取り込むことが可能です。また、Cloud Storageを経由し、基幹システムのデータやローカルデータもロードできます。
収集したデータはBigQueryのテーブルに保存されます。BigQueryは完全マネージド型であり、ペタバイト級のデータもスケーラブルに蓄積できる点が特徴です。また、ストレージとコンピューティング処理が分離しているため、保存コストとクエリコストを最適にコントロールできます。
蓄積した生データは、そのままでは分析に活用しづらいため、BigQuery上でSQLを用いて変換・加工します。たとえば、不要な列の削除やデータ型の変換、マスタデータとの結合などです。BigQueryは大規模データでも高速にクエリを実行できるため、バッチ処理やスケジュールクエリを活用しながら、日次や週次でデータを自動変換する運用も可能です。
加工が完了したデータは、一般にBIツールを用いて分析・可視化します。たとえばBigQueryでは、Looker StudioやTableau、Power BIなどのBIツールがネイティブ接続に対応しています。BIツールと連携させることで、リアルタイムに近いデータをもとにダッシュボードを作成でき、迅速かつ正確な意思決定に寄与します。
データ基盤の構築にはETLツールがおすすめ
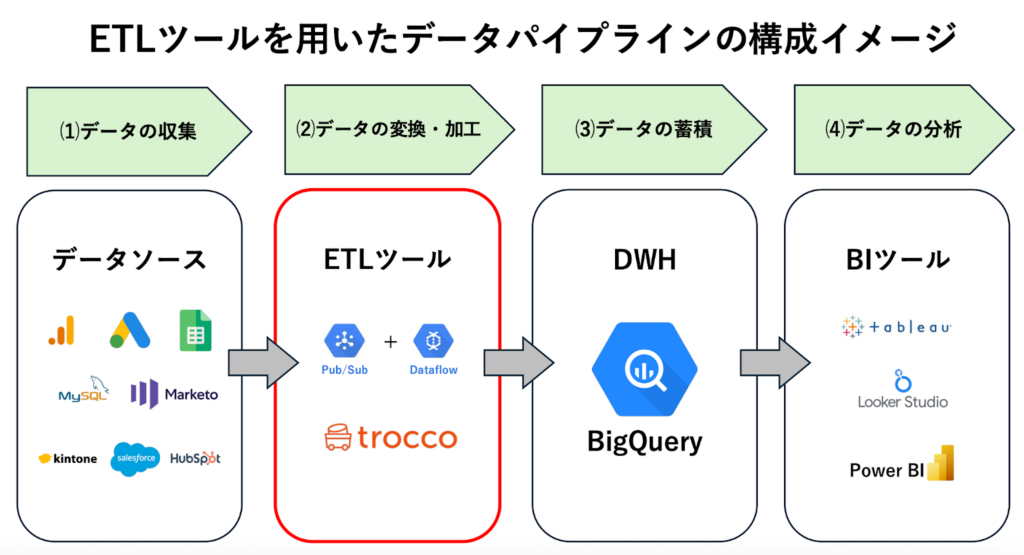
BigQueryを中心とするデータ基盤では、データの収集や加工プロセスをスムーズに運用するため、ETLツールの導入が非常に効果的です。ETLツールを活用することで、データ基盤の構築・運用にかかる負荷を大幅に軽減できます。
一般にETLツールには、SaaSやデータベース、クラウドストレージなど、さまざまなコネクタが用意されており、複数データソースとの接続設定を容易に行えます。エンジニアが個別にデータ取得処理をコーディングする必要がなく、GUIベースで操作できるため、開発スピードの大幅な向上が可能です。
また、ETLプロセス(データの抽出・変換・書き込み)を自動化できるため、BigQuery上でデータ変換のためにSQLを記述する必要がなくなります。さらに、ETLツールにはスケジューリング機能や監視・アラート機能が標準搭載されているものも多く、運用保守の安定性を容易に維持できます。
まとめ
本記事では、BigQueryの概要や基本的な操作、BigQueryを用いたデータ基盤について解説しました。
BigQueryは、高速かつスケーラブルなクラウド型DWHとして、多くの企業で活用されています。基本的な概念や主要機能を正しく理解し、組織のデータ活用をさらに推進させましょう。
なお、BigQueryと外部システムをデータ連携させたい場合は、ETLツールの活用が非常に有効です。ETLツールを使えば、データの抽出・加工・書き込み処理をGUI上で直感的に設計でき、SQLやプログラミングの知識がなくても柔軟なデータパイプラインを構築できます。
分析基盤向けデータ統合自動化サービス「TROCCO」は、primeNumber社が提供する日本発のETLツールです。ETL・データ転送に加え、データマートの自動生成やジョブスケジューリング、データガバナンスまで幅広く対応しており、BigQueryとの連携にも強みを持ちます。
自社のデータ活用に課題感を抱いている方は、ぜひ一度primeNumberにご相談ください。






