
2018年11月にクラウドETL「TROCCO」をリリースしてから6年が経ち、2024年12月現在でおよそ2,000の企業・団体にご活用いただきました。
リリース以来一貫して、お客さま一人ひとりの声を大切にしながらプロダクトを進化させてきました。この姿勢は、私たちprimeNumberが大切にしている価値観「8 Elements」のうちの一つ、「価値を返す」という言葉に込められています。これからデータ活用を進められる皆さま、そして今後も引き続き「TROCCO」をご活用いただく皆さまに価値を返し続けていきたいと考えています。
弊社が掲げるビジョン「あらゆるデータを、ビジネスの力に変える。」のもと、データ活用を志す方々が自身のデータエンジニアリングの知識量に関係なく、データの収集から分析、ビジネスへ活用し、よりスムーズにデータ活用のメリットを享受できる世界を実現していきたいと考えています。そのため、「TROCCO」や「COMETA」といったプロダクト・サービスを開発、提供し、皆さまのデータ活用をサポートさせていただいております。
本セッションでは、あらゆるデータをビジネスの力に変えるため、これまで私たちが取り組んできたこと、そして今後のアップデートを鈴木よりご紹介させていただきました。
※本記事は2024年12月10日に開催されたprimeNumber社主催イベント「01(zeroONE) 2024 」の登壇セッションをもとに編集しております。
登壇者紹介
鈴木 健太
株式会社primeNumber 取締役執行役員CTO
東京大学工学部卒業後、株式会社リブセンスにてエンジニアとして同社WEBサイトの開発・企画・分析などに従事。primeNumberへは2017年に参画し、汎用型データエンジニアリングPaaS 「systemN ™」の開発を担う。データ統合自動化SaaS「TROCCO®」リリース後は同プロダクトの開発をリードする。
データ活用でぶつかる課題を解決するクラウドETL「TROCCO」

「そもそも、なぜデータ基盤が必要なのでしょうか。それは企業が抱えるデータを活用するためには、さまざまな課題があるからです。たとえば、広告運用のデータを利用するには管理画面からCSVをエクスポートする必要がありますし、見込み顧客のステータスはSFAツール上のダッシュボードで確認しなければなりません。それらのデータを合わせて活用しようとしても、集計する作業が必要です。さらにデータ分析をするためには、そもそもデータを蓄積しておかねばなりません。このような背景から、データを集め、整形し、分析する環境を整えるためには、データ基盤が必要なのです」(鈴木)
クラウドETL「TROCCO」は、データを分析・活用するために点在するデータを集約し、データ統合をおこなうETL機能に加え、データ処理をサポートするデータマート機能、それらを包括的に“オーケストレーション”するワークフロー機能などを備えています。また、データウェアハウス内のデータ分析だけに留まらず、SFAツールなどの外部アプリケーションに対してデータを返すリバースETL機能も提供しています。
2,000社以上の企業・団体に「TROCCO」を導入いただいた3つの決め手

「TROCCO」はデータ活用を進める、さまざまな企業にご導入いただいています。

株式会社ベイシア様は販売データを活用することで店舗の売上向上に取り組まれており、以前よりスクラッチ開発されたデータ基盤を活用されていました。今回、保守の属人化をきっかけにTROCCOを導入いただきました。
これまでは新しいパイプラインの作成に時間がかかっており、分析がしたくてもデータがすぐに揃いませんでしたが、パイプラインの作成時間が短縮されました。それにより、データが早く届くことでデータ活用に対してよりプロアクティブに動けるようになりました。
さらにシステム担当者へもTROCCOを活用いただくことで、データエンジニアの方以外も自らがデータを取りにいけるようになりました。
<株式会社ベイシア様の導入事例>
自社で設定が完了することで外部パートナーとのコミュニケーションコストが減少。大手小売グループがデータ基盤の脱属人化を実現するまで

株式会社サミーネットワークス様ではTROCCO、COMETAをご利用いただいております。これまで分析者のデータ取得の要望に叶えるまで3ヶ月かかっていたところ、最長1週間に短縮されました。さらにその取り組みがきっかけで社内から表彰されています。サミーネットワークス様でもデータエンジニアだけでなく、多くのユーザーの方にTROCCOを活用いただいております。
<株式会社サミーネットワークス様の導入事例>
「データの民主化」を推し進め、社内からの表彰やグループ会社への貢献も。データ基盤の再構築に「TROCCO」を活用
データ活用を進めるにあたり「TROCCO」を導入いただく決め手として、大きく3つのポイントが挙げられます。
1. 国内製品を始めとしたコネクタの充実度
日本国内で多く利用されている、日本発のツール・サービスを中心にさまざまなコネクタを展開しています。さらに1年で100個の新しい接続先を拡充する「CONNECT100+」を宣言しています。
primeNumber社、「あらゆるデータ」の対応に向けてクラウドETL「TROCCO」の機能を大幅拡充 ~100超のサービスやオンプレミスに対応、連携を大幅に拡張~
2. シンプルなUIによる学習コストの低さやドキュメントの分かりやすさ
データエンジニア以外のビジネスユーザーでもデータパイプラインを実装できます。ツールのシンプルさからツールの学習コストが低く、社内の属人化を排除できるツールとして評価いただいています。また、専任のテクニカルライティングチームによる、マニュアルやFAQといったドキュメント拡充に力を入れています。
3. 手厚いサポート
弊社のカスタマーサクセスは、お客さまに「価値を返す」ことを常に意識しており、リリース以来高い評価を受けています。導入して終わりにせず、お客さまとゴールをすり合わせながらデータ活用をサクセスへ導いていく点は、多くのお客さまに選ばれている理由です。
「TROCCO」の信頼性・品質向上の取り組み

コネクタの開発やサポートの充実だけでなく、安心して「TROCCO」をご利用いただくための「信頼性」への取り組みも重視しています。
1. Kubernetesの導入と状況に適した運用
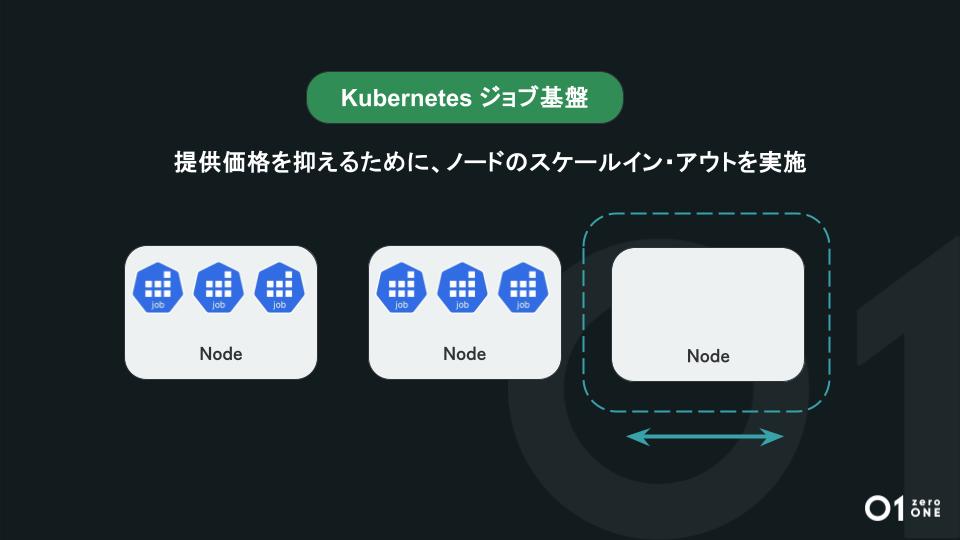
「TROCCO」のジョブ基盤には、コンテナの運用管理と自動化を行うKubernetesをリリース間もない時期より採用しています。2024年12月現在は、ジョブ基盤として1日数十万のジョブを安定的に実行する基盤として運用されています。
また、ジョブ基盤の品質を守るための取り組みにも力を入れています。お客さまのジョブが安定的に実行できるために十分なリソースを確保しています。しかし、常に最大数のジョブ実行時のリソースを起動し続けると莫大なコストがかかってしまいます。最終的にはお客さまへの提供コストに跳ね返ってしまうため、お客さまの利用状況に応じたスケールイン・アウトを実施しています。
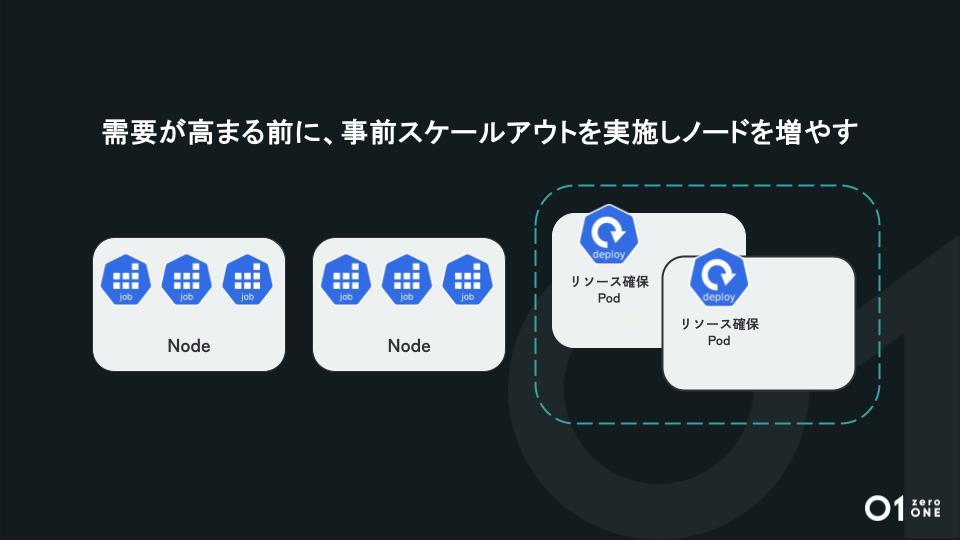
ただ、需要が高まったタイミングで新しくマシンの起動するには時間がかかり、ジョブ遅延が発生してしまう可能性がありました。そこで需要が高まる前にスケールアウトを実行し、より安定して稼動できるように変更しました。
<詳細は「アーキテクチャConference2024」の講演レポートをご覧ください>
信頼性を担保しながらユーザー体験を向上するTROCCO開発の裏側(アーキテクチャConference 2024講演レポート)
2. 各コネクタの変更を検知するためのスナップショットテスト
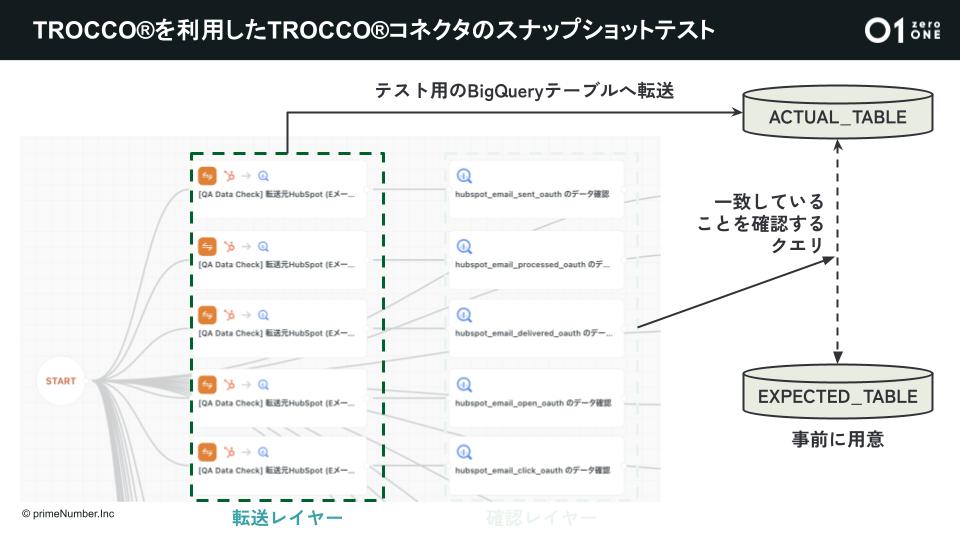
コネクタが日々安定的に動き続けているか監視するため、「TROCCO」を用いて「TROCCO」自体の転送データをスナップショットテストする仕組みを構築しています。
「TROCCO」では多くのコネクタを安定してご提供しています。ただ、コネクタ側の予期せぬアップデートにより、取得するデータの形が変更されてしまうこともあります。それによって、お客さまのデータ分析基盤への信頼性が下がってしまいます。
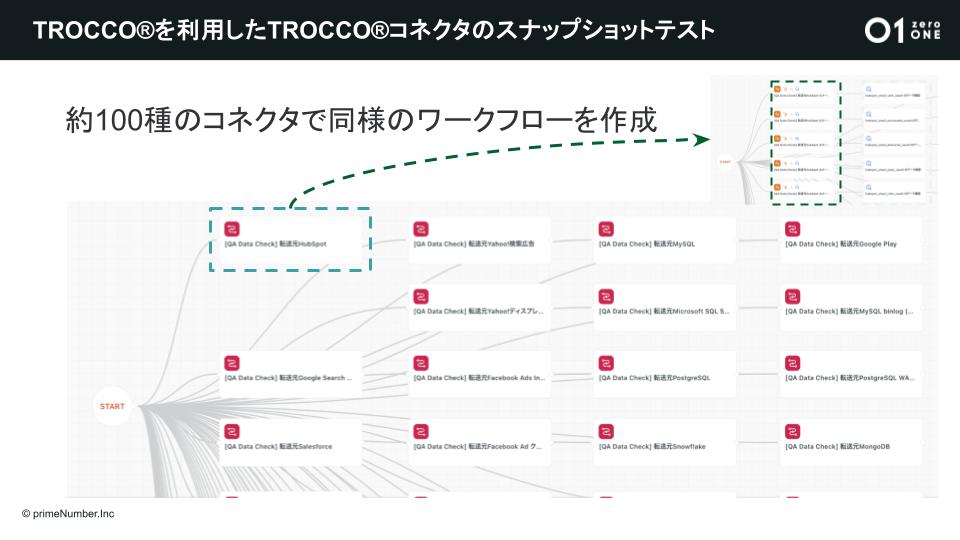
そこで活用しているのが、「TROCCO」のワークフロー機能とデータチェック機能です。「TROCCO」のワークフロー内で「TROCCO」の転送ジョブを実行し、同じデータが転送されているかどうかデータチェック機能を用いて確認しています。これは「TROCCO」のプロダクトリリースの度に必ず行われており、予期せぬ変更になるべく早く気がつけるように約100種類のコネクタすべてを対象に実施しています。
3. 大小問わず障害発生時に実施するポストモーテム文化

万が一、障害が発生した場合でも迅速に対応できる体制を構築しているのはもちろんのこと、大小問わず発生した障害に対して再発防止の検討を実施しています。継続的にプロセス・アーキテクチャ・コードベースを改善しています。
システムの安定性向上のためのアーキテクチャの見直し
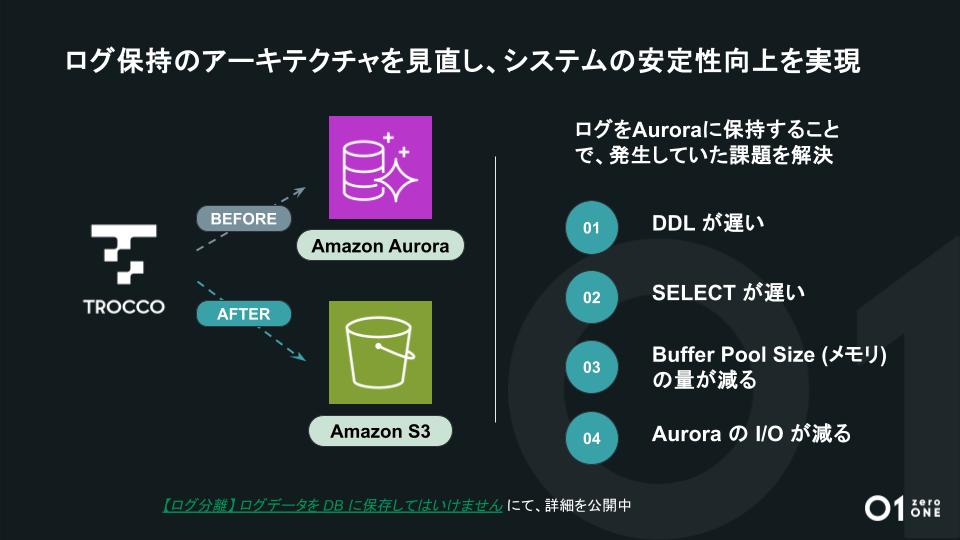
最後に品質向上のため、ログ保持のアーキテクチャを見直し、システムの安定性向上を実現しました。TROCCOではジョブ実行後にログを確認することができます。そのログは元々Amazon Auroraに保持していましたが、Amazon S3に出力先を変更しました。
本来、Amazon Auroraはロゴを保持するのに適したデータベースではありません。
そのため、以下の事象が発生する可能性が高い状況でした。
- データベース変更操作が遅い
- ログを出力した際、SELECTが遅い
- データベースのメモリが減る
- データベースのI/Oが減る
リリース以来使ってきたアーキテクチャを見直し、より良い顧客体験が届けられるようになりました。
詳細はこちらからご覧ください。
【ログ分離】 ログデータを DB に保存してはいけません
クラウドデータカタログ「COMETA」が解決する課題と4つの特徴
「TROCCO」に続き、2024年5月に提供を開始しましたクラウドデータカタログ「COMETA」についてもご紹介させていただきました。
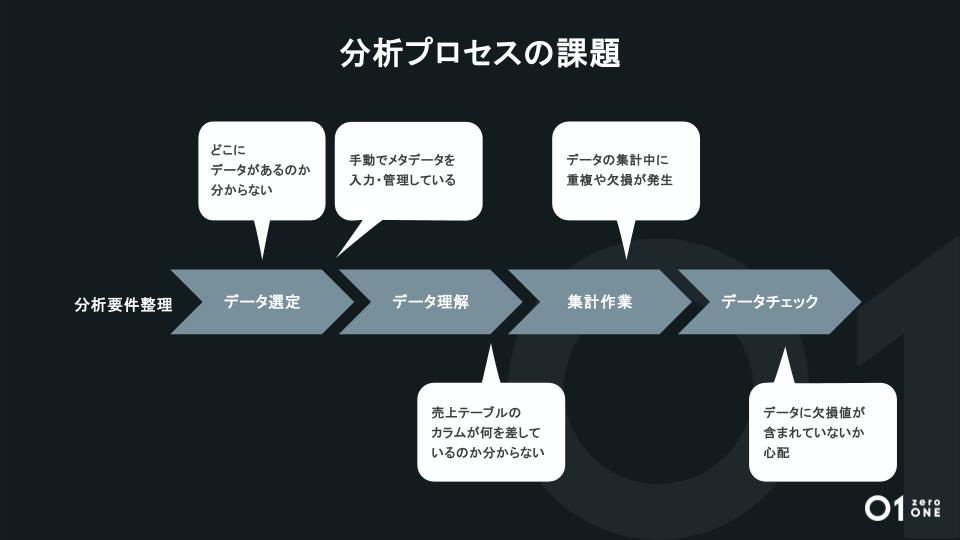
データの分析プロセスには、円滑な分析を妨げるさまざまな課題があります。
- どこにどのデータがあるのか分からない
- 手動でメタデータを入力・管理しており、手間がかかる
- 売上テーブルのカラムが何を指しているのか分からない
- データの集計中に重複や欠損が発生した
- データに欠損値が含まれたままになっていないか心配
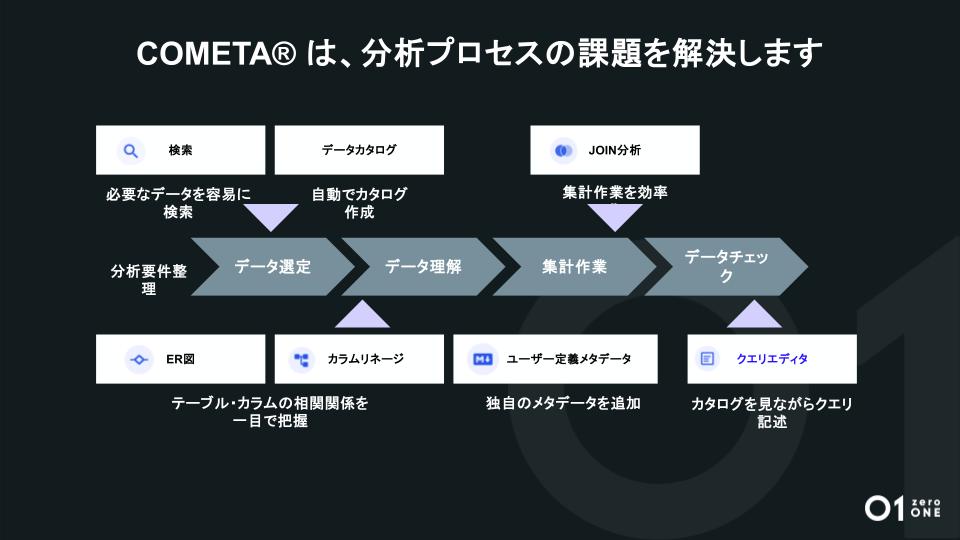
こうした分析プロセスの課題を解決する、さまざまな機能を持つサービスが「COMETA」です。たとえば必要なデータを容易に検索できる機能や、自動でメタデータを生成して登録するデータカタログ機能、カラム間の依存を表すカラムリネージ機能などを提供しています。
また、「COMETA」では以下のようなサービスの特徴を打ち出しています。
- 管理の手間を減らすため、メタデータは自動で更新
- データ理解と活用に関わる時間を短縮
- テーブル詳細画面では、一目でデータが理解できる
- テーブルのメタデータを確認しながらクエリを書いてそのまま実行できる
COMETAの詳細はこちらからご覧ください。
https://primenumber.com/cometa
ユーザーコミュニティ primeNumber User Groupをはじめ、お客さまとともに進化してきた「TROCCO」の歴史
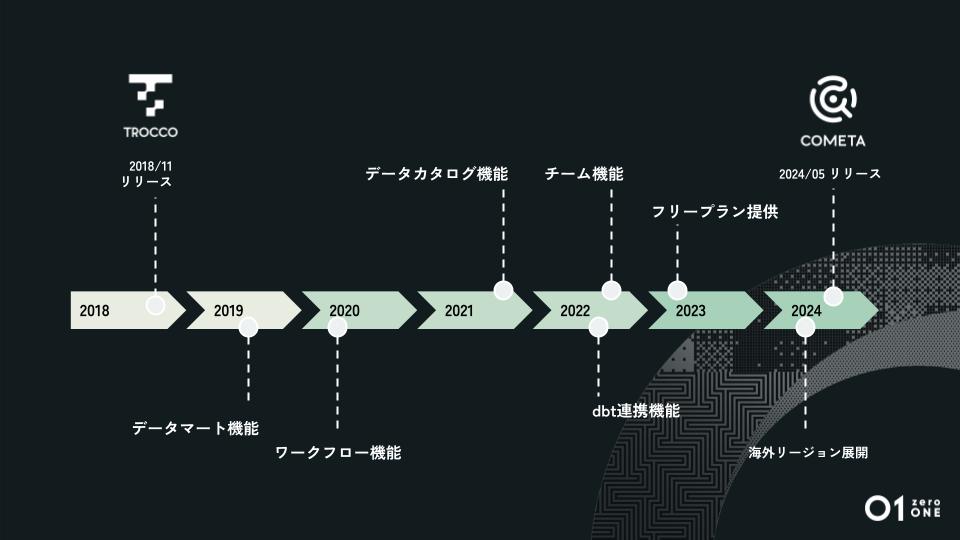
「改めて『TROCCO』をリリース当時から振り返ると、お客さまとデータに向き合ってきた歴史だったと実感します。リリースされた6年前はGoogle Cloudのデータウェアハウスである
BigQueryが主流となり、データエンジニアを抱える企業の多くが自社データをデータウェアハウスに統合することがトレンドでした。当時はまだクラウドETLは一般的ではなく、自前でパイプラインを構築し、各社のデータエンジニアの方々が障害対応やコネクタのAPIアップデートに日々向き合っていました。『社内にデータエンジニアがいる企業だけが自由にデータを分析できる時代』だったと考えています。
そうした時代にベータ版をリリースした『TROCCO』は、初期からお付き合いがあった企業におけるデータ活用の課題を一つひとつ解決することから歩き出しました。お客さまに寄り添い、機能に対する要望を深くお聞きし、プロダクトに生かす。そしてお客さまに対して価値を返していく姿勢は今でも変わらない文化の一つです。
そこから数コネクタの対応に始まり、お客さまの要望に応えて機能を追加していきました。当時は機能が少なかったにも関わらず複数のお客さまにご利用いただいていたことから、データ統合が世の中の企業の大きな課題であることを感じていました。まずは目の前のお客さまに向き合い、課題を解決し、安心してご利用いただくための機能を強化する。そのようにユーザー様と一緒に作り上げてきたのがTROCCOでした。
また、『日本のデータマネジメント領域のリーダーを増やす』ことをビジョンに掲げて活動しているのが、primeNumber User Groupです。ユーザーコミュニティを通じ、『TROCCO』や『COMETA』を用いたデータ活用のノウハウや情報・意見を交換する場を提供しています。
その後、ETL機能の強化に留まらず、データマート機能やワークフロー機能といった現在の『TROCCO』の中核となる機能をリリースしてきました。さらに大企業のお客さまにも導入いただけるように権限管理ができるチーム機能も強化させていただきました。そして、2024年12月現在ではおよそ2,000社に導入いただいております」(鈴木)
基幹業務領域を含めた、100以上の新規コネクタを提供開始。CONNECT 100+(コネクト・ワンハンドレッドプラス)

今後もさらに「価値を返す」ため、機能のアップデートを続けてまいります。直近の「TROCCO」のアップデートのテーマは「つながる」です。
「TROCCO」が提供する接続先の外部サービス・システムは100を超えています。「100」という数字は多く聞こえますが、あらゆるデータを扱うことを目指すプロダクトとしてはまだまだ満足のいく数ではありません。そこでこの1年、さらに100サービスのコネクタを追加していきます。まず第一弾として、主に基幹業務領域のサービス・システムとのサービス連携を2025年2月までに実現します。
- 会計領域:マネーフォワード会計、マネーフォワード会計Plus、freee会計、Zoho Books、Zoho Inventory
- 人事領域:SmartHR
- RevOps領域:SanSan
- 決済領域:Stripe、Square
- その他:Spotify
「これまでは1個のコネクタを提供するまで約2ヶ月もかかっていました。そこで直近の半年間、この『CONNECT 100+』に向けて『コネクタ超拡充』という技術改善プロジェクトを実施しました。新しいコネクタの提供開始までのスピードを大きく改善すること、そして『TROCCO』について詳しくないエンジニアでも開発できるようにすることの2つを掲げ、分業してコネクタを開発できる体制を整えました。合わせて日々プロセスを改善することでより早くお客さまに価値を届けられるようにしています」(鈴木)
コネクタをお客さま自身で開発・利用できる環境を提供する「Connector Builder」

「『エンドユーザーが接続したいデータソースのコネクタがない』『自社のSaaSのコネクタを作成して広めたい』『開発環境があれば自社で作りたい』『自社サービスにデータを取り込みたい』といったご要望を実現する機能が『Connector Builder』です。大きく3つの機能をご紹介します。
- 従来の発送元HTTPに比べ、学習コストが低く、素早くコネクタ作成が可能に
- 作成したコネクタは、他のユーザーと共有が可能
- 転送元だけでなく、転送先も開発が可能
2025年春より段階的なリリースを予定しています。自社サービスのコネクタを開発された企業の方は、『TROCCO』のコネクタ一覧にぜひ自社サービスを掲載していただければと思います」(鈴木)
お客さまのインフラ環境内でデータ転送処理が完了する機能「Self-Hosted Runner」
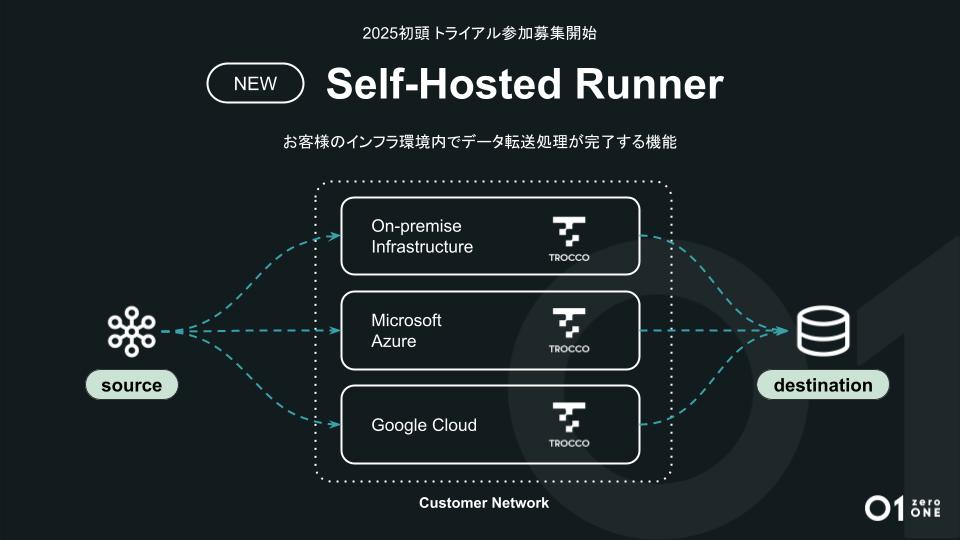
「クラウドETLである『TROCCO』ですが、オンプレミス環境やプライベートクラウド環境との連携を強化します。オンプレミス環境にある基幹系のデータや、お客さま自身が管理するクラウドなど、セキュアな環境でのデータ転送ニーズにお応えするため、お客さまのインフラ環境内でデータ転送処理が完了する『Self-Hosted Runner』をリリースします。
『Self-Hosted Runner』はハイレベルなセキュリティ要件を満たすことが特徴です。これまで『TROCCO』はクラウド上のみに存在していたため、データを転送する際には一時的にデータをクラウド上にあるTROCCOへ渡し、さらにアウトバウンド通信とインバウンド通信を許可いただく必要がありました。」(鈴木)
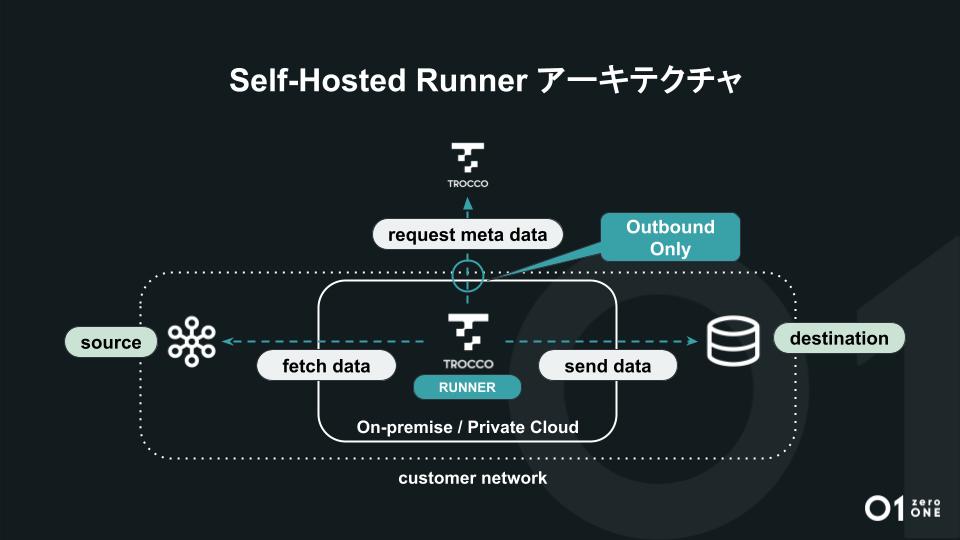
「一方で『Self-Hosted Runner』は、お客さまのオンプレミス環境やプライベートクラウド環境内でジョブが実行されて転送処理が完了するため、データ転送するデータを一時的にクラウドETL『TROCCO』に渡す必要がありません。ジョブ実行に必要なメタデータの取得はクラウド上のTROCCOから行うため、アウトバウンド通信のみ許可いただくと実行が可能です。
今回のリリースに伴い、ウェブ開発とは異なるさまざまな技術的チャレンジに取り組みました。Ruby on Railsをベースとしたプロダクト開発を行っていますが、技術的課題を乗り越えるべく転送処理部分のGo言語への刷新を進めています。さらにお客さまにどのように提供し、どのようにアップデートを仕組み化するのかも検討しました。
2025年1月よりトライアルへの参加を随時募集しています。ご関心がある企業の担当者の方はぜひお問い合わせください」(鈴木)
トライアルをご希望の方はこちらからお申し込みください。
https://primenumber.com/trocco/features/self-hosted-runner
転送形式を見直し、大容量DBのデータ転送をより楽にする「CDC」

CDC機能の大幅なアップデートによって、ユーザー体験がより良くなり、データベースからデータウェアハウスへの大容量のデータ転送が実現できます。また、今までのアーキテクチャを一から見直し、より楽にデータ統合が行えるようにもなりました。
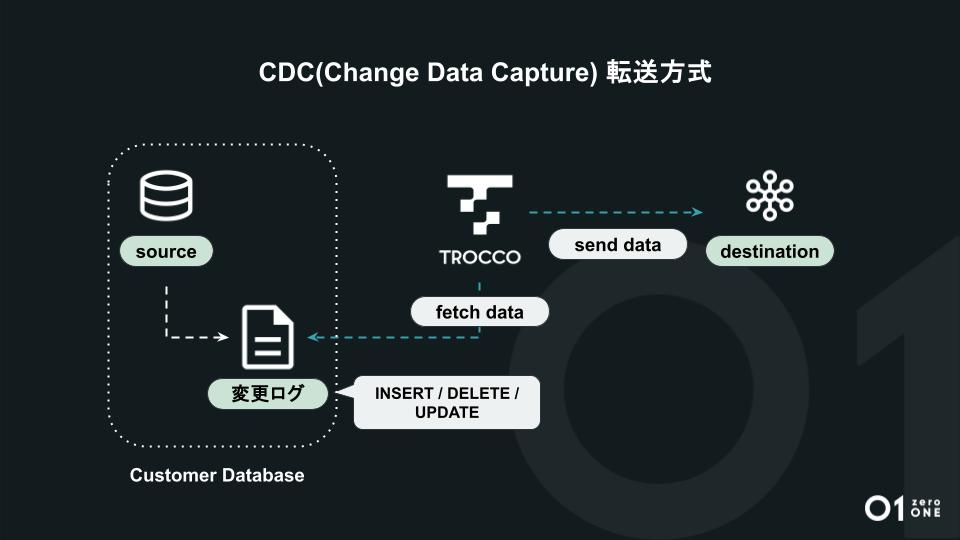
「これまでの一般的な『TROCCO』の転送方式は、データソースに対してSQLを実行し、データ転送を行うものでした。それに対してCDC方式はデータソースがはき出す実行変更ログを読み取るものです。INSERT・DELETE・UPDATEなどの情報を読み取り、それらを随時データウェアハウスに対して転送します。そのためデータベースへの負荷が下がったり、リアルタイムに反映できたり、物理削除にも対応できたりするなど、さまざまなメリットがあります。
また、リアルタイム性が向上し、これまでサポートしていなかったGoogle BigQuery以外のコネクタも対応、UXも刷新予定です。2025年4月にβ版の提供を開始いたします」(鈴木)
コード管理によるガバナンス強化・堅牢な運用の実現「API / Terraform Provider」
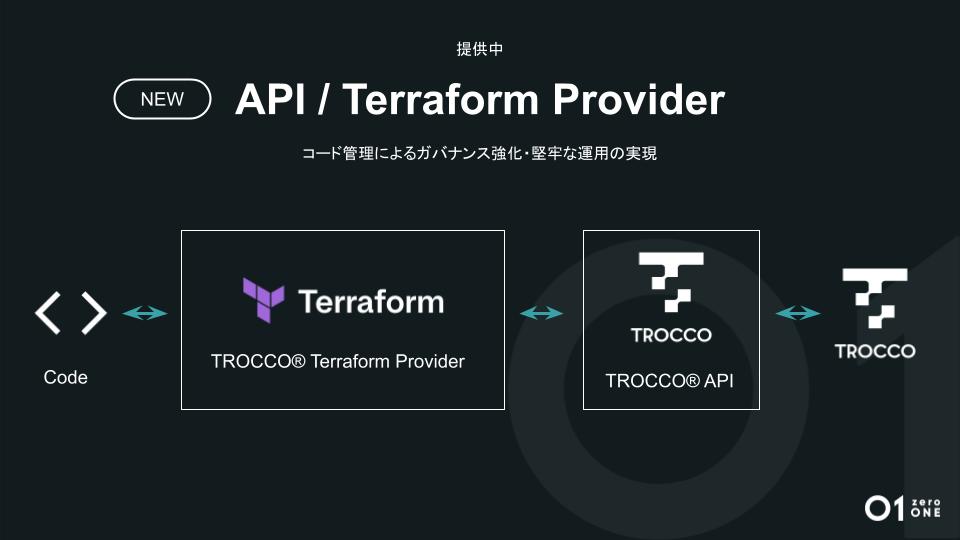
「現場から始まったデータ活用が組織に広まると、必ずガバナンスについての検討が必要になります。データ活用が順調に進むにつれ、『TROCCO』上には多くの設定ができているはずです。それをGUIでいちいち管理するのは大変ですし、ガバナンスも効きません。
こうした課題を解決し、ガバナンスを強化するために一般的な手法であるコード管理を『TROCCO』でも実現しました。これによってGUIによる素早い設定作成と、コード管理によるガバナンスを保ったデータ基盤の保守運用を両立できます。
今回のアップデートでは、転送設定やデータマート機能、ワークフロー機能、ユーザーなど、さまざまなリソースのコード管理が可能となりました。データ統合領域におけるガバナンス向上に、ぜひご活用ください。Terraformを利用したガバナンス強化の例の一つとして、TROCCOのユーザー管理もご紹介します。
UI上の変更では、ソフトウェア開発において一般的に行われるようなレビューによる統制を効かせにくいという問題があります。そのため、TROCCOユーザーがいつの間にか作成されていた、作成・変更するロールが誤っていた、退職者のユーザーが残り続けていたなどの課題もあると思います。
TerraformでTROCCOのユーザー管理をコード化し、ユーザーの作成・変更はすべてコード上で行い、レビューを必須にすることで、意図しないユーザーが作成されたり、退職者を忘れずに削除するようなフローを組むことも可能になります。」(鈴木)

今後、Terraform Providerでの管理対象範囲も広がっていく予定です。ぜひご期待ください。
詳細はドキュメントをご覧ください。
https://registry.terraform.io/providers/trocco-io/trocco/latest/docs
生成AIを活用し、メタデータの整備・データの発見を助ける機能をリリース

「『COMETA』では生成AI機能の拡充を予定しています。そのひとつがメタデータ生成機能です。メタデータはどのようなデータを持つのか詳細を表すデータです。
これまではお客さまが手入力する必要がありましたが、今後はカラム情報や依存関係をもとに生成AIで生成できるようになります。」(鈴木)
2025年2月現在、メタデータ生成機能のβ版をリリースいたしました。
詳細はこちらからご覧ください。
クラウド データカタログ「COMETA」、メタデータ自動生成機能のベータ版を提供開始
あらゆるデータをビジネスの力に変えるためのエンジニア組織

「現在、『TROCCO』は30名を超えるメンバーで開発しています。今回お話ししたアップデートは、どれも需要と技術難易度が高いものばかりです。その他にも、今回ご紹介しきれなかったセキュリティ組織なども立ち上がり、日々お客さまに新しい価値を返すように取り組んでいます。今後のアップデートも、ぜひ楽しみにしていただければ嬉しいです。
データエンジニアリングの知識の有無に関わらず、あらゆるデータをビジネスの力に変えることを実現できるよう、プロダクト、サービスを強化していきます。皆さまがデータをビジネスのパートナー、そして自社の成長につなげることを願っています」(鈴木)





