
近年、気象データを活用した意思決定の重要性が高まっています。
小売業では「天候に応じた需要予測」、物流業では「配送遅延のリスク検知」、製造業では「気温や湿度を加味した稼働効率の最適化」など、さまざまな業種で気象情報の利活用が進んでいます。
一方で、気象庁が提供するオープンデータは更新頻度が高く、手動での取得や加工には手間がかかります。
本記事では、クラウドETLサービス「TROCCO」の転送元HTTPコネクタを利用し、気象庁の気象データを自動取得し、BigQueryなどのデータ基盤に連携する方法を具体的に解説します。
気象庁オープンデータの活用が求められる理由
気象庁は、防災・観測・予報に関する多様なデータをオープンデータとして公開しており、商用利用を含めて自由に活用できます。
気象データ高度利用ポータルサイト:https://www.data.jma.go.jp/developer/index.html
企業でも再利用や統合分析の素材として注目されており、特に以下のデータがよく利用されています。
- 最新の気象データ(CSV形式):アメダス観測値(降水量・気温・風速・積雪など)を10分〜1時間ごとに更新
- 過去の気象データ(CSV形式):観測値を日単位でダウンロード可能
これらのデータを自動で取得・格納・可視化する仕組みを整えることで、以下のような効果が期待できます。
- 気象条件を踏まえた需要・来店予測の精度向上
- 異常気象リスクの早期検知と業務調整
- エネルギーや設備稼働の最適化
- マーケティング施策・在庫管理の自動化
TROCCOの転送元HTTP・HTTPSコネクタとは?
TROCCOの転送元HTTP・HTTPSコネクタは、公式コネクタが用意されていない外部サービスでも、HTTP(S)で公開されているCSVファイルなどのデータを取得できる機能です。
気象庁が提供している気象データもCSV形式でURLが公開されているため、このコネクタを利用すれば、URLを指定するだけでデータの定期取得からデータ基盤への転送までを自動化できます。
主な特徴は以下の通りです。
- セキュアな認証設定: APIキー、Bearer Token、OAuth等の認証方式に対応
- 柔軟なパラメータ設定: クエリパラメータ、ヘッダー、リクエストボディの自由な設定
- ページング設定: 大量データの自動分割取得に対応可
- スケジュール実行: 定期的な自動データ取得
- データ変換機能: JSONレスポンスの自動パース・フラット化
これにより、気象庁のオープンデータをETLパイプラインの一部として組み込むことができます。
※ 転送元HTTP・HTTPSコネクタは TROCCO の Advanced プラン以上のプランでご利用いただける機能です。
利用するデータ
一般的に気象データの分析には、アメダスの観測データがよく利用されます。
しかし、アメダスの公開形式は手動検索や条件指定を前提としており、定期的なデータ取得には向いていません。
これに対し、「最新の気象データ(CSV)」はURL構造が固定化されており、観測から約30〜50分後に自動更新されるため、TROCCOのようなETLツールで安定的にスケジュール取得を行うのに適しています。
DWHに連携し、ダッシュボード数値更新や日次・時間単位の分析に活用するケースに最適です。
そのため、今回は「最新の気象データ(CSV)」の利用を前提とした気象情報のデータ取得について解説を行います。
ドキュメントURL
気象データ高度利用ポータルサイト:
https://www.data.jma.go.jp/developer/index.html
「最新の気象データ」CSVダウンロードについて:https://www.data.jma.go.jp/stats/data/mdrr/docs/csv_dl_readme.html
取得できる気象現象
CSVでダウンロード可能な気象現象は以下の表のとおりです。
| 気象現象 | 要素 |
| 降水 | 1,3,6,12,24,48,72時間降水量、日降水量、降水量全要素 |
| 気温 | 最高気温、最低気温 |
| 風速 | 最大風速、最大瞬間風速 |
| 降雪 | 現在の積雪、最深積雪、3,6,12,24,48,72時間降雪、累積降雪量、降雪量全要素 |
なお、降雪に関しては11月から5月の冬季間のみデータ取得が可能になります。
気象庁「最新の気象データ」CSVディレクトリ構造概要
ベースURLhttps://www.data.jma.go.jp/stats/data/mdrr/
1|ディレクトリ階層構造(第1階層:要素カテゴリ)気象庁オープンデータ
| ディレクトリ | 気象現象 | 主な内容 |
| pre_rct/ | 降水量(Precipitation) | 1h, 3h, 6h, 12h, 24h, 48h, 72h, 日降水量、降水量全要素 |
| wind_rct/ | 風(Wind) | 最大風速、最大瞬間風速 |
| tem_rct/ | 気温(Temperature) | 最高気温、最低気温 |
| snc_rct/ | 積雪・降雪(Snow Condition) | 最深積雪、降雪量など |
2|ディレクトリ階層(第2階層:データ種別)
各ディレクトリの下には、基本的に全国全観測所をまとめた CSV ファイルが格納されている alltable/ サブディレクトリがあります。
以下が例になります。
- /pre_rct/alltable/
- /wind_rct/alltable/
- /tem_rct/alltable/
3|ファイル命名規則(共通ルール)
| 種別 | 命名パターン | 説明 |
| 最新データ | XXXX00_rct.csv | 最新データ(例:pre1h00_rct.csv = 1時間降水量 最新) |
| 時刻指定(年月日時分) | XXXX00_YYYYMMDDhhmm.csv | 特定時刻のデータ(例:pre1h00_202310310940.csv = 2023年10月31日09:40観測分) |
| 日付指定(n日前24時) | XXXXDDMM.csv | 日付を指定して取得(例:pre1h1028.csv = 10月28日24時分) |
4|各カテゴリ別一覧
降水量(pre_rct)
| 指標 | 最新 | 時刻指定例 | 3日前24時例 |
| 1時間降水量 | pre1h00_rct.csv | pre1h00_202310310940.csv | pre1h1028.csv |
| 3時間降水量 | pre3h00_rct.csv | pre3h00_202310310940.csv | pre3h1028.csv |
| 6時間降水量 | pre6h00_rct.csv | pre6h00_202310310940.csv | pre6h1028.csv |
| 12時間降水量 | pre12h00_rct.csv | pre12h00_202310310940.csv | pre12h1028.csv |
| 24時間降水量 | pre24h00_rct.csv | pre24h00_202310310940.csv | pre24h1028.csv |
| 48時間降水量 | pre48h00_rct.csv | pre48h00_202310310940.csv | pre48h1028.csv |
| 72時間降水量 | pre72h00_rct.csv | pre72h00_202310310940.csv | pre72h1028.csv |
| 日降水量 | predaily00_rct.csv | predaily00_202310310940.csv | predaily1028.csv |
| 降水量全要素 | preall00_rct.csv | preall00_202310310940.csv | preall1028.csv |
ファイル保持期間:
- 各時刻指定ファイルは 24 時間保持
- 各日 24 時のファイルは 7 日前まで取得可能
風(wind_rct)

| 指標 | 最新 | 時刻指定例 | 3日前24時例 |
| 最大風速 | mxwsp00_rct.csv | mxwsp00_202310310900.csv | mxwsp1028.csv |
| 最大瞬間風速 | gust00_rct.csv | gust00_202310310900.csv | gust1028.csv |
気温(tem_rct)
| 指標 | 最新 | 時刻指定例 | 3日前24時例 |
| 最高気温 | mxtemsadext00_rct.csv | mxtemsadext00_202310310900.csv | mxtemsadext1028.csv |
| 最低気温 | mntemsadext00_rct.csv | mntemsadext00_202310310900.csv | mntemsadext1028.csv |
5|ファイル共通仕様
| 項目 | 内容 |
| 形式 | CSV(Shift_JIS) |
| 区切り | カンマ区切り(,) |
代表的な取得可能データの項目例
| データカテゴリ | 主要な項目 |
| 降水量系(pre_rct) | 観測所番号、都道府県、地点、現在時刻(観測時刻)現在値、最大値、記録更新フラグ、統計開始年 |
| 気温系(tem_rct) | 観測所番号、都道府県、地点、現在時刻(観測時刻)最高気温・最低気温、統計開始年 |
| 風速系(wind_rct) | 観測所番号、都道府県、地点、現在時刻(観測時刻)最大風速・最大瞬間風速、風向、統計開始年 |
データの更新頻度
更新頻度は下記の表の通りです。
| 気象現象 | 更新頻度 |
| 今日の降水量 | 10分毎の更新(観測から約30分後に更新) |
| 今日の降水量以外(累積降雪量は除く) | 1時間毎の更新(毎時00分の観測データを50分過ぎに更新) |
| 1-7日前の全要素(累積降雪量を含む) | 毎日5時00分ごろ、13時00分ごろ、19時00分ごろ、翌日1時00分ごろに更新。 |
詳細は気象庁の「最新の気象データ」CSVダウンロードについてを参照してください。
【事前準備】気象庁オープンデータを利用するための確認事項
気象庁のオープンデータは、APIキーや認証なしで誰でも利用できます。
ただし、安定した運用と適切な利用のために、以下の点を確認しておきましょう。
1. 利用規約と出典表記の遵守
- データ利用時は「出典:気象庁ホームページ」などと明記する必要があります。
- 加工・再配布を行う場合は、「編集・加工を行った旨」と「編集責任が利用者にある」ことを併記します。
- 詳細は、気象庁「利用上の留意事項(PDF)」を参照してください。
2. アクセス頻度とダウンロード量の制御
- 気象庁のサーバーは一般公開用であり、高頻度アクセスや大量ダウンロードは推奨されていません。
- データ更新タイミング(例:毎時50分頃、10分ごと更新など)を確認し、それに合わせて定期取得を設定します。
- TROCCOなどのETLツールでは、1時間〜数時間間隔のスケジュール設定を推奨します。
3. データ保持期間と取得パスの確認
- 各時刻指定ファイルは24時間のみ保持されます。
- 各日24時のファイルは7日前まで取得可能です。
- 最新のデータ構造は「最新の気象データ(CSV)」で確認できます。
【実践編】気象庁オープンデータと転送元HTTP・HTTPSコネクタでデータ連携を実現
ここからは、TROCCOの転送元HTTP・HTTPSコネクタを利用して、気象庁が公開するオープンデータを自動取得・転送する設定手順を解説します。
サンプルとして「1時間降水量(全国)」データをBigQueryに連携する構成を例に進めます。
このデータは全国約1300地点の降水量を1時間ごとにまとめたもので、気象庁オープンデータの中でも多くの分析で利用される代表的なデータです。
需要予測・配送計画・天候連動施策など、幅広い分析のベースデータとして利用できます。
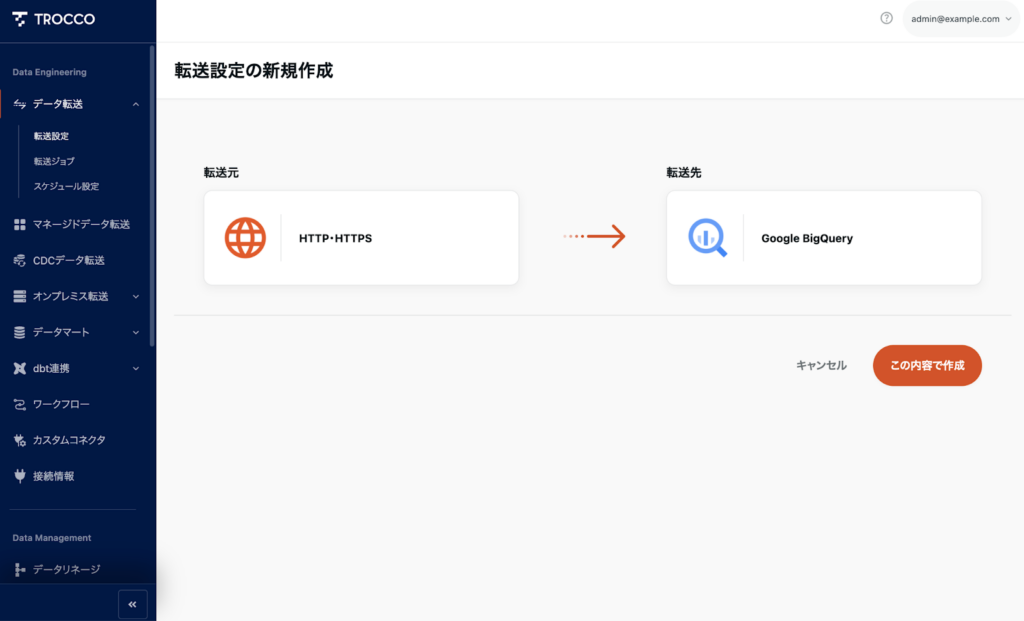
STEP1|転送元・転送先の設定
- TROCCOのメニューから [データ転送] → [転送設定] を開きます。
- [新規転送設定作成] ボタンをクリック。
- 「転送元」で HTTP・HTTPS を選択します。
- 「転送先」では今回は Google BigQuery を選択します。
転送元の設定
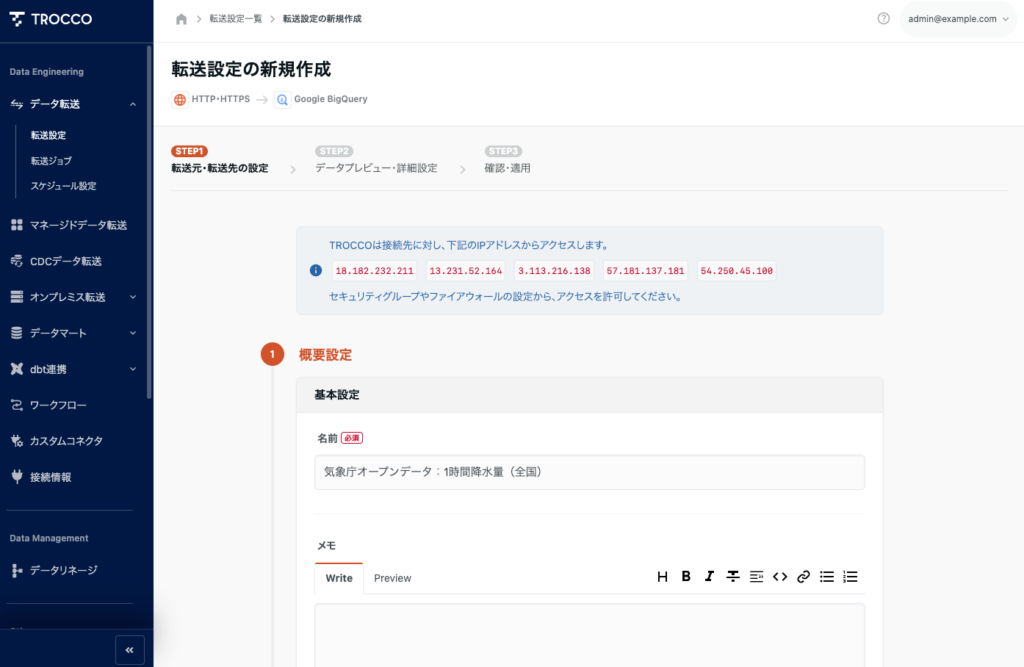
気象庁の最新気象データは、CSV形式で以下のようなURL構造を持っています。https://www.data.jma.go.jp/stats/data/mdrr/pre_rct/alltable/pre1h00_rct.csv
これは「直近1時間の降水量(全国)」データです。
このURLをHTTPコネクタのリクエスト設定として登録します。
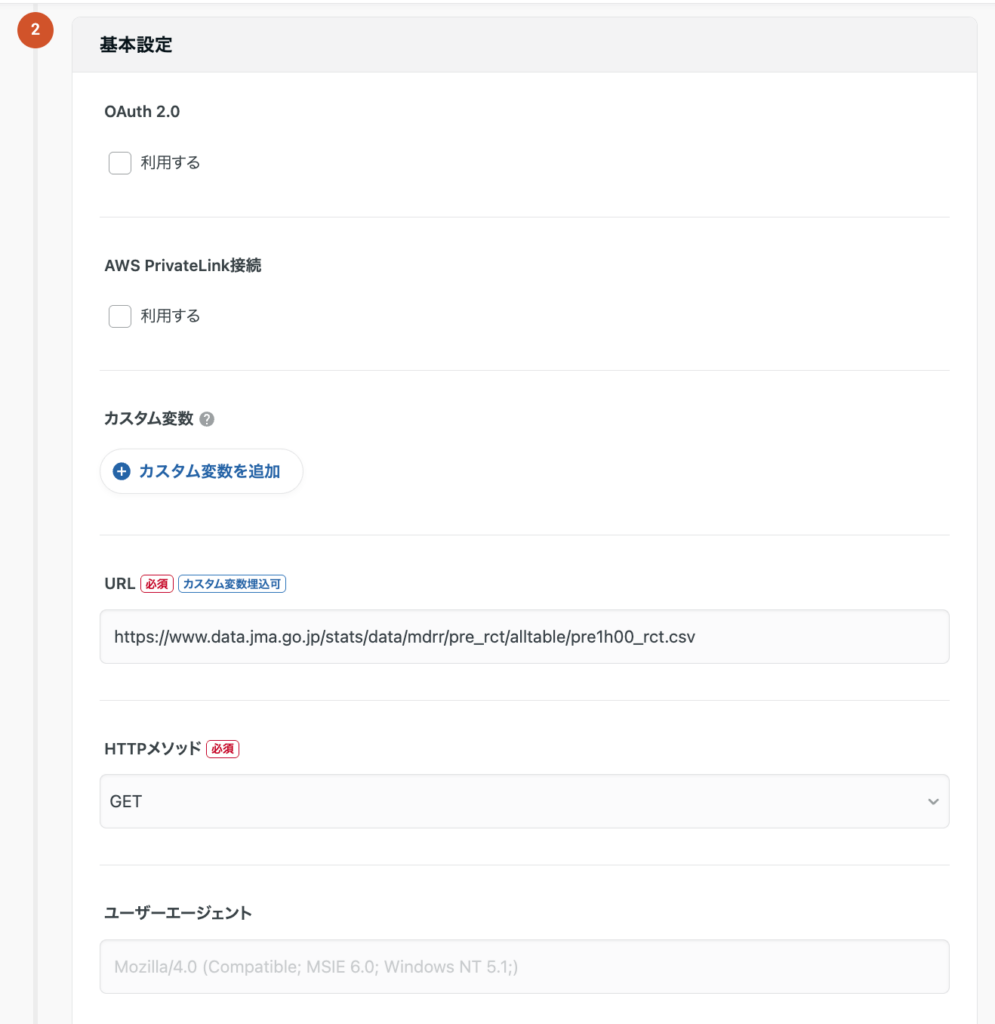
設定例:
| 項目 | 値 |
| URL | https://www.data.jma.go.jp/stats/data/mdrr/pre_rct/alltable/pre1h00_rct.csv |
| HTTPメソッド | GET |
| 文字エンコーディング | Shift_JIS |
| 入力ファイル形式 | CSV/TSV |
| パラメータ / HTTPヘッダ | 不要(気象庁オープンデータは認証不要) |
URLの末尾にタイムスタンプがつく時刻指定や日時指定ファイル(例:pre1h00_YYYYMMDDhhmm.csv)もあります。
日次や時間別に分割して取得したい場合は、TROCCOの「カスタム変数」機能を使って日付パラメータを自動展開できます。
詳しくはヘルプドキュメントのカスタム変数についてを参照してください。
転送先の設定(Google BigQuery)
転送先の設定は次のドキュメントを参照して設定してください。
転送モード:
- 追加(APPEND):毎時取得で新しい観測データを追記
- 全件洗い替え(REPLACE):最新データを上書き(推奨はAPPEND)
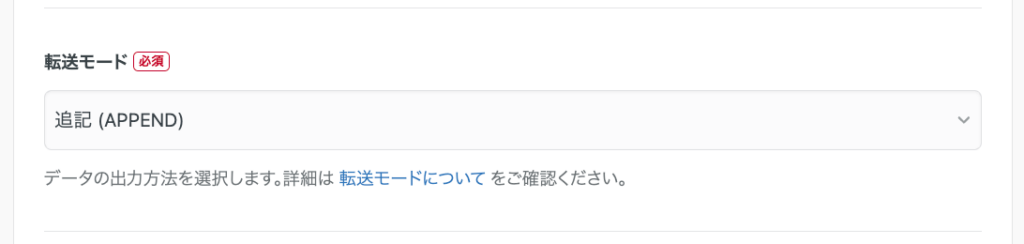
設定後、 [次のSTEPへ] ボタンをクリックします。
[自動データ設定の選択] で [自動データ設定を実行] を選択し [決定して次へ進む] をクリックします。
STEP2|スキーママッピング
気象庁CSVデータのサンプルが自動的に取得され、テーブルのプレビューが表示されます。
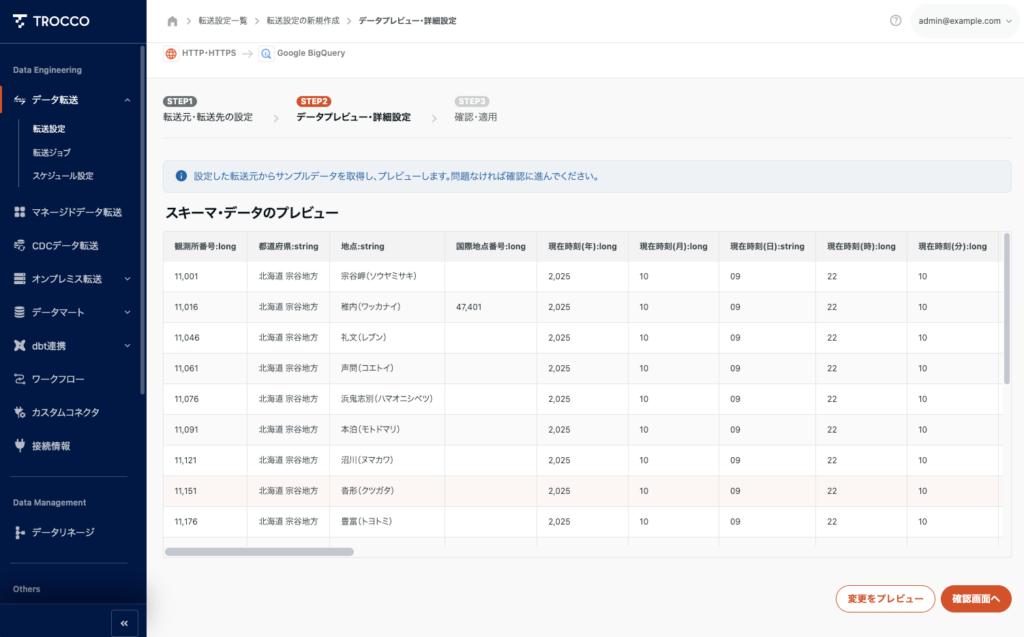
TROCCOが自動的にカラム名・データ型を推論します。
※必要に応じてカラム名を英字に変換したり、日付フォーマットを統一してください。以下が例です。
観測所番号→station_id時刻→observation_time降水量(mm)→precipitation_mm
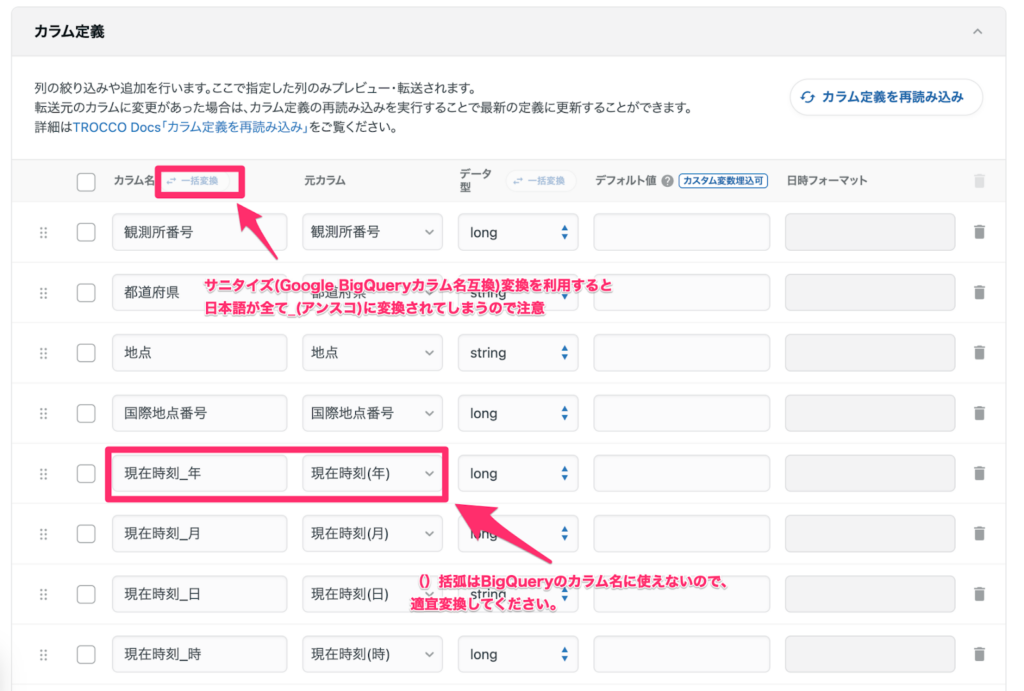
▽注意事項
一部の列名には()や℃といったBigQueryのカラム名として利用できない文字列が含まれているため、そのまま転送してしまうとエラーとなってしまいます。BigQueryのスキーマ整合性を保つため、_C, _mm などにリネームしておきましょう。
また、カラムが多い場合にGUI上でカラムを変更するのは手間なので、STEP1の「自動データ設定・カラム定義の再読み込みで使用するファイル」に「別のファイルを指定」を選択し、英字に変換済のCSVファイルをアップロードして読み込ませることもできます。
一度該当ファイルをダウンロードし、ChatGPTなどのAIツールでカラム名のみ英字に変換したファイルを、アップロードしてご利用ください。
この際に文字コードがデータソースと同じSHIFT_JISではないと転送時に文字化けしてしまうため、SHIFT_JISになるようご注意ください。
自動データ設定後、STEP2の「入力オプション」の「文字エンコーディング」がSHIFT_JISに設定されていることも確認してください。

以下は、カラム定義用のファイルを読み込んでデータ自動設定を行った例です。
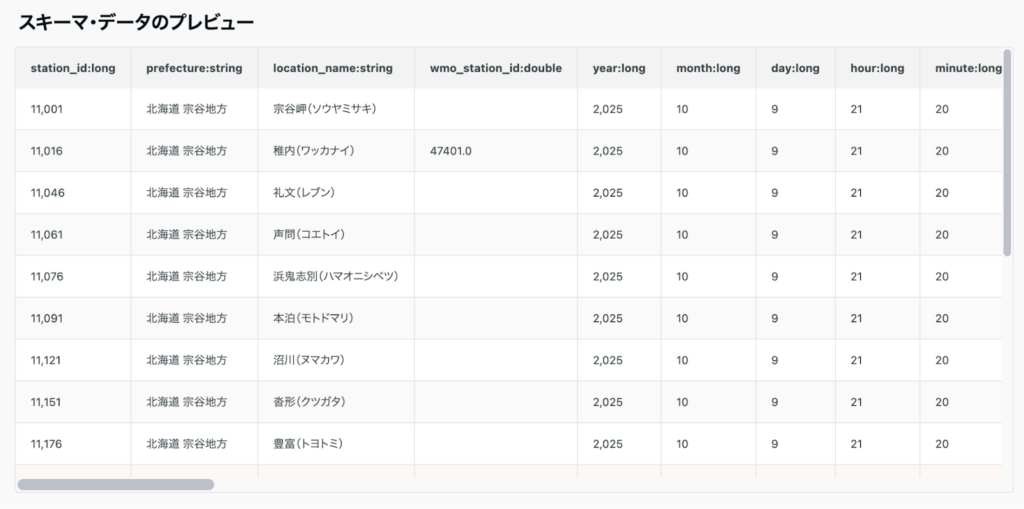
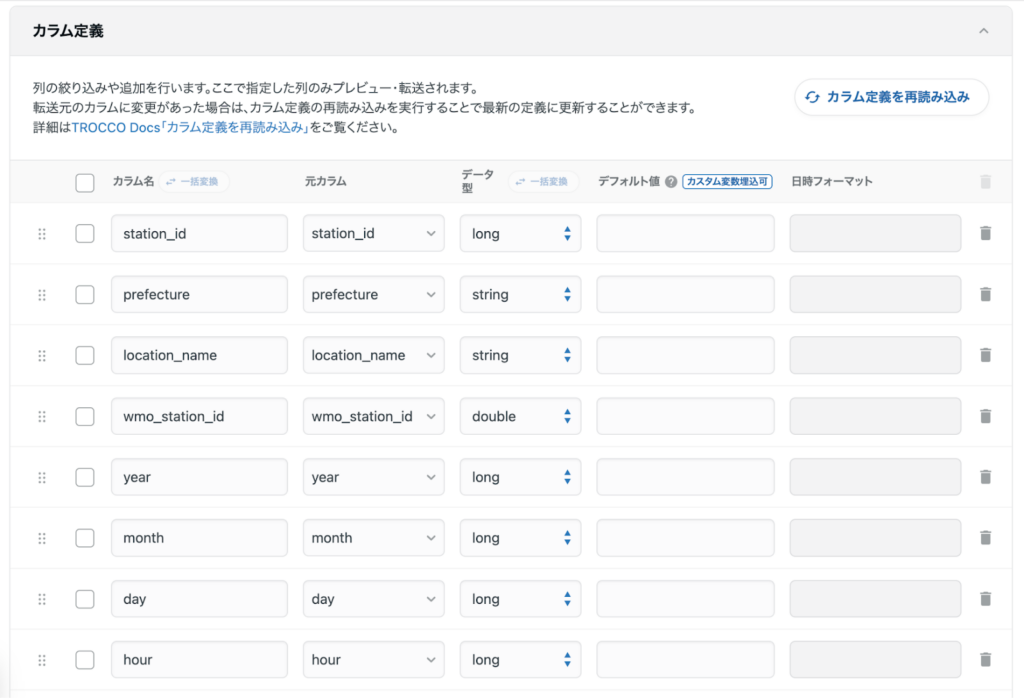
STEP3|設定の確認・保存
- 入力内容を確認したら、画面右下の [確認画面へ] をクリックします。
- 設定内容が表示されるので、問題がなければ画面右下の [保存して適用] をクリックして設定を保存します。
- 設定完了後、転送設定の詳細画面に戻ります。
- 右上の [実行] ボタンを押し、手動実行でデータ転送のテストを行います。
ジョブのログ画面でステータスが「SUCCESS」になれば、データ取得とBigQuery転送が正常に完了しています。
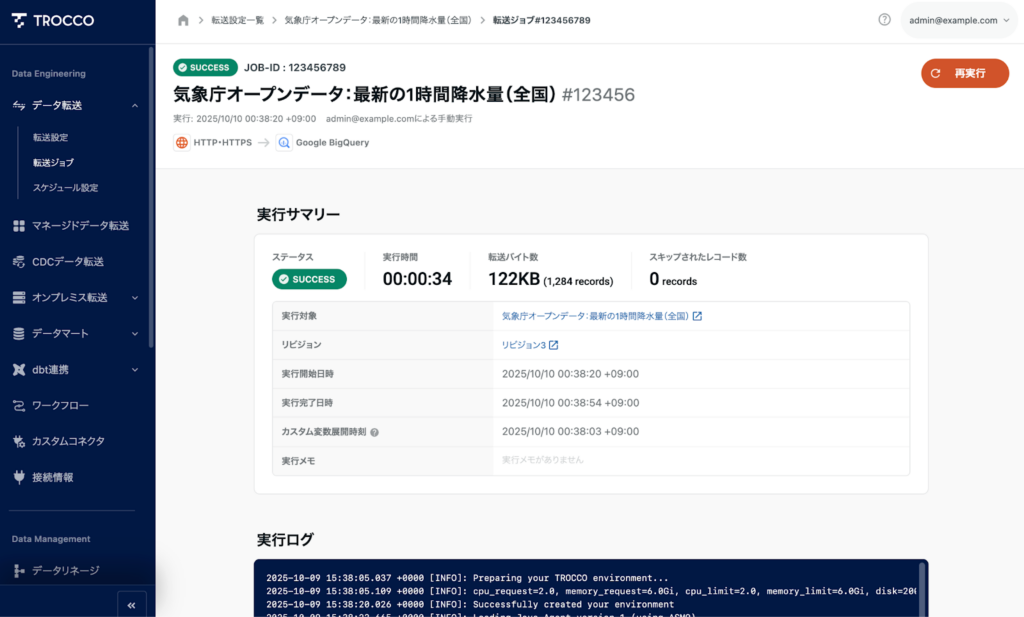
BigQuery上で次のようなデータが確認できます。
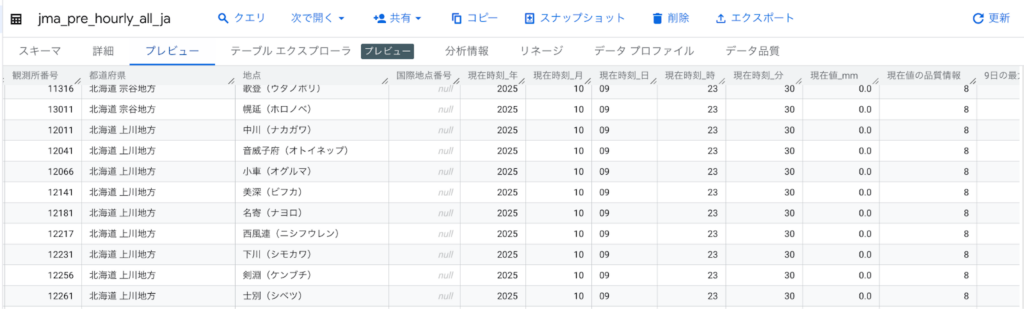
定期実行の設定
気象データは高頻度で更新されるため、定期ジョブ化することで分析データを常に最新状態に保てます。
- 転送設定画面の [スケジュール設定] タブを開きます。
- [スケジュールを追加] をクリックしスケジュール登録を行います。
- 毎時55分(気象庁更新の約5分後)を推奨
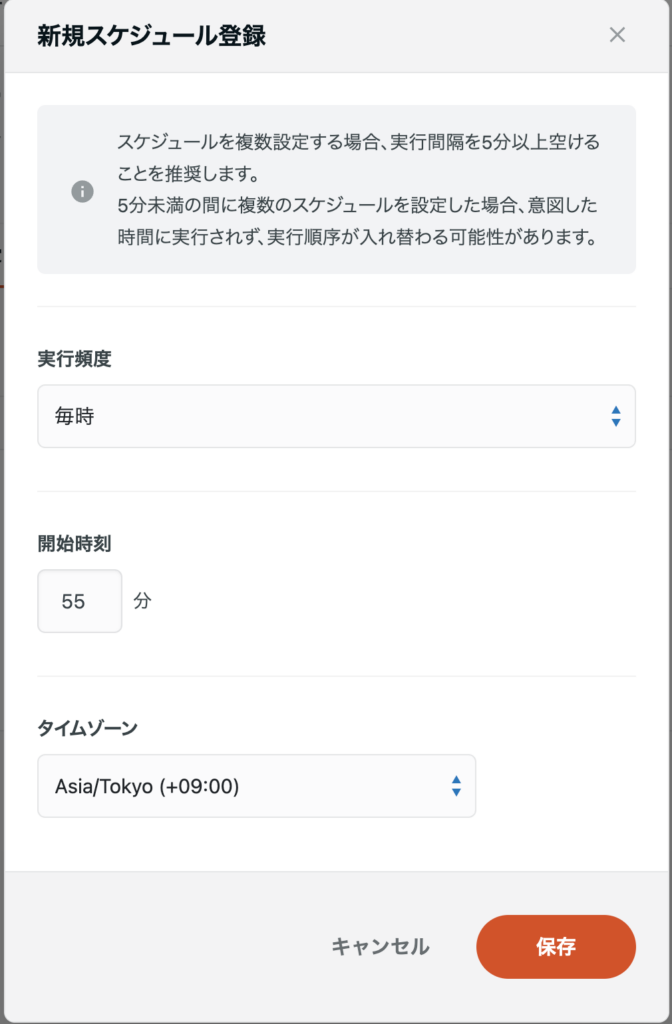
また、実行完了の通知をSlack/メールへしておくと運用がスムーズです。
※ 気象庁データの更新には最大30分の遅延があるため、余裕を持ったスケジュール設定を行ってください。
気象データの実践的な活用ユースケース
TROCCOを用いて気象庁オープンデータをBigQueryなどのDWHに蓄積すると、
社内のさまざまなデータと掛け合わせた分析・自動化が実現します。
ここでは代表的なユースケースを紹介します。
1. 物流・製造業:降雨・強風による運行最適化
- 利用データ例:1時間降水量、最大風速、最大瞬間風速
- 活用内容:
- 最新の降雨・風速データを利用して、配送ルートや稼働エリアの天候リスクを自動判定。
- 輸送遅延・安全性リスクのスコアリングを行う。
- リスクに応じて配送責任者や人員配置責任者へアラートを通知
- 予報データと組み合わせて運行や人員配置を判断
- 導入効果:
- 突発的な降雨・台風時の対応時間の短縮
- 運行停止・人員配置判断の支援
2. マーケティング・広告領域:天候連動キャンペーン
- 利用データ例:降水量(最新10分・1時間単位)
- 活用内容:
- 降水量をトリガーにSlackやZapierなどの通知・自動化ツールと組み合わせて広告配信を自動制御(例:雨の日限定クーポン配信)。
- TROCCOで気象データを広告プラットフォームのデータと同期。
- 導入効果:
- 天候別のCTR(クリック率)改善
- タイミング精度の高いキャンペーン運用
- 運行停止・人員配置判断の支援自動化
3. 設備・エネルギー管理:短期的な気象変化に応じた稼働制御
- 利用データ例:気温の最新観測値
- 活用内容:
- 設備の稼働状況や電力消費データと組み合わせ、急な気温変化に応じた制御や予防保全を実施。
- 例:外気温が上昇した際に冷却装置の稼働を調整するアラートを発する。
- 導入効果:
- エネルギー効率の改善
- 異常気象時のリスク軽減
よくある質問(FAQ)
Q1. 気象庁オープンデータの利用に制限はありますか?
A. ありません。商用利用を含め自由に活用できますが、「出典:気象庁ホームページ」など、出典元の明記が必要です。また、大量アクセスや高頻度取得はサーバ負荷を避けるため控えめに設定してください。
Q2. データ取得の更新タイミングはどのくらいですか?
A. 「最新の気象データ(CSV)」のうち、今日の降水量は10分ごとに観測され、観測からおおむね30分後に公開されます。その他のデータ(気温・風速など)は1時間ごとに更新され、毎時00分の観測値が50分過ぎに公開されます。
これらの更新タイミングに合わせて、定期ジョブのスケジュール設定を行ってください。気温や降水など複数の要素を同時に取得したい場合は、毎時55分ごろに設定すると安定してデータを取得できます。
Q3. 文字コード(Shift_JIS)への対応は必要ですか?
A. TROCCOでは、入力オプションで文字コードを指定することで、Shift_JISのファイルを正しく読み取れます。UTF-8として処理されるため、BigQueryなどのUTF-8前提のDWHにもそのまま転送可能です。
Q4. BigQuery以外のDWHにも転送できますか?
A. 可能です。Snowflake、Redshift、Databricksなど主要DWHに対応しています。HTTPコネクタの設定は共通で、出力先を切り替えるだけで転送可能です。
まとめ
気象庁のオープンデータは信頼性が高く、需要予測や配送最適化など幅広い業務で活用できます。
一方で、データの更新頻度や形式が多様なため、継続的に運用・分析に活かすには一定の手間がかかります。
TROCCOのHTTP・HTTPSコネクタを利用すれば、こうした気象庁のデータをノーコードで自動取得し、BigQueryなどのDWHへ転送できます。
さらに、ワークフロー機能を組み合わせることで、SQLによるデータ加工や集計など、一連のデータ整備を自動化することも可能です。
気象情報をリアルタイムに可視化し、データドリブンな意思決定を支える仕組みを、TROCCOで構築してみるのはいかがでしょうか。
気象データの活用をご検討の方は、ぜひ TROCCOの無料トライアル をお試しください。
※転送元HTTP・HTTPSコネクタは、TROCCO の Advanced プラン以上のプランでご利用いただける機能です。






