楽天RMS APIを活用したデータ連携は、多くのEC事業者が直面する課題です。手作業でのデータ取得は非効率であり、スクラッチ開発には多大なリソースを要します。本記事では、クラウドETLツール「TROCCO」の転送元HTTP・HTTPSとワークフロー機能を活用し、楽天RMS APIを利用したデータ取得を行い、Snowflakeへのデータ転送の自動化を行うステップバイステップの実装方法を解説します。
楽天RMS APIの仕様と実装の課題
楽天RMS APIを利用した注文データ取得は、以下の2段階で行う必要があります。
- searchOrder:検索条件に合う注文番号一覧を取得
- ※ページングLIMITに注意。1,000件上限のためAM/PMなどで日内分割します)
- getOrder:受け取った注文番号リストをもとに注文詳細を取得
- ※1リクエスト100件の上限制約を前提にバッチ分割
この「2段階データ取得」という手順をスクラッチ開発した場合、APIリクエストの管理、取得データの加工、API制限への対応など、複雑な処理の実装を伴い、開発工数と保守コストが増加します。TROCCOを利用することで、これらの処理をGUIで手軽に設定し、自動化することが可能です。
実装イメージ図(アーキテクチャ図)
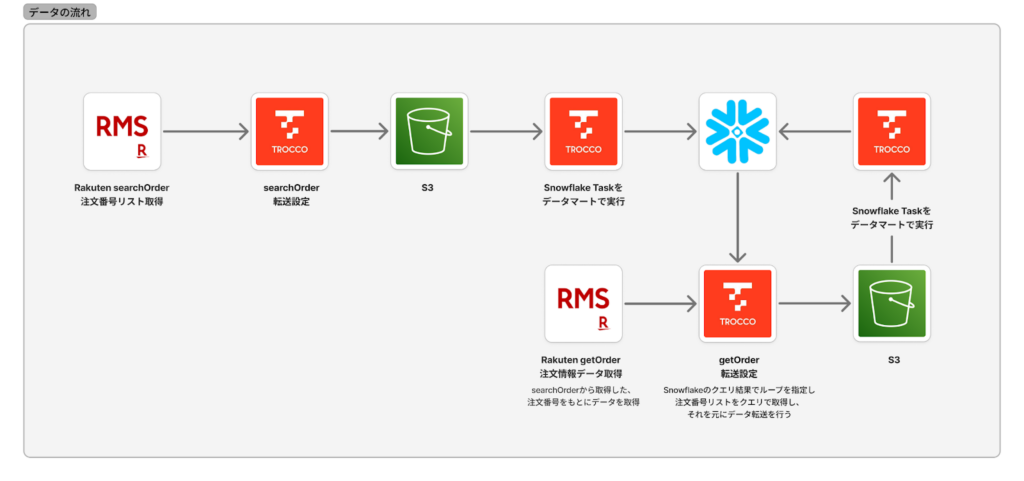
- searchOrderで注文番号リストを取得 → S3へ転送
- Snowflake Taskを実行 → S3からSnowflakeへ転送
- Snowflake上の注文番号リストを変数として getOrder に渡し → S3へ詳細を転送
- Snowflake Taskを実行 → S3からSnowflakeへ転送
本構成では、TROCCOで取得した楽天RMSデータをまずS3に集約し、その後Snowflakeのテーブルへロードしています。このようにデータを一度S3に落とす「レイク&ウェアハウス分離」構成を採用する背景には、次のような理由があります。
- データの信頼性確保:S3上にすべての生データを保持することで、再処理・追跡・監査に対応しやすい
- 運用の再現性:Snowflake側のテーブル定義やジョブをTerraformでコード化し、環境間で同一構成を維持
- 変更や拡張への柔軟性:新しいソース追加や変換処理の再設計が容易
特にSnowflakeとTerraformを組み合わせる運用は、近年のデータエンジニアリング領域で推奨されるベストプラクティスの一つとなっています。
さらに、Snowflake側の権限設計では、ソーステーブルの参照や Snowflake Task の実行など、各権限を分離し最小限の権限のみを付与したTROCCO専用のユーザーおよびロールを構築することで、より安全かつ安定した運用を実現できます。
こうした発展的なデータパイプラインも、TROCCOのデータマート機能を使えば、手軽に構築・管理ができます。
TROCCOの転送元HTTP・HTTPSコネクタとは?
転送元HTTP・HTTPSコネクタは、TROCCOの公式コネクタがないサービスでも、公開API(REST/JSONやCSVのAPIなど)があればデータの取得ができる機能です。
- セキュアな認証設定: APIキー、Bearer Token、OAuth等の認証方式に対応
- 柔軟なパラメータ設定: クエリパラメータ、ヘッダー、リクエストボディの自由な設定
- ページング設定: 大量データの自動分割取得に対応可
- スケジュール実行: 定期的な自動データ取得
- データ変換機能: JSONレスポンスの自動パース・フラット化
転送元HTTP・HTTPSコネクタを利用し、楽天RMS API連携により、注文詳細などのデータ取得が可能です。
※ 転送元HTTP・HTTPSコネクタは TROCCO の Advanced プラン以上のプランでご利用いただける機能です。
【実践編】楽天RMS APIと転送元HTTP・HTTPSコネクタでデータ連携を実現
実際に楽天RMS APIをTROCCOの転送元HTTP・HTTPSコネクタを利用した実装する方法を解説します。
STEP1|作成前に環境の準備をする
楽天RMS APIの利用にはWebAPIの利用申請が必要です。API認証に必要な情報の取得は楽天RMSのマニュアルを参照してください。
楽天RMSのWebサービスAPIでは、一般的なOAuthやBearerトークンとは異なり、独自形式での認証を採用しています。
認証情報は「サービスシークレット」と「ライセンスキー」の2つを組み合わせて生成します。具体的には、これらを :(コロン)で連結した文字列をBase64エンコードし、その結果をHTTPのAuthorizationヘッダーに指定します。そのため、APIを利用する前にあらかじめエンコード処理を行い、認証用のAPIキーを生成しておく必要があります。
また、APIドキュメントは楽天にて出店されている方のみへ提供されており、公開ドキュメントはありませんので、APIドキュメントを入手しておく必要があります。
- 楽天RMS管理画面で、APIの利用申請を行う
- 認証情報を控えます
- サービスシークレット
- ライセンスキー
- 店舗ID
- Authorizationヘッダー用のAPIキーの生成
- Authorization: ESA <Base64(サービスシークレット:ライセンスキー)>
- APIドキュメントを準備する
STEP2|転送設定の作成:注文番号を取得してS3に保存(searchOrder)
まず、searchOrder エンドポイントを利用し、注文番号リストを抽出する設定を行います。
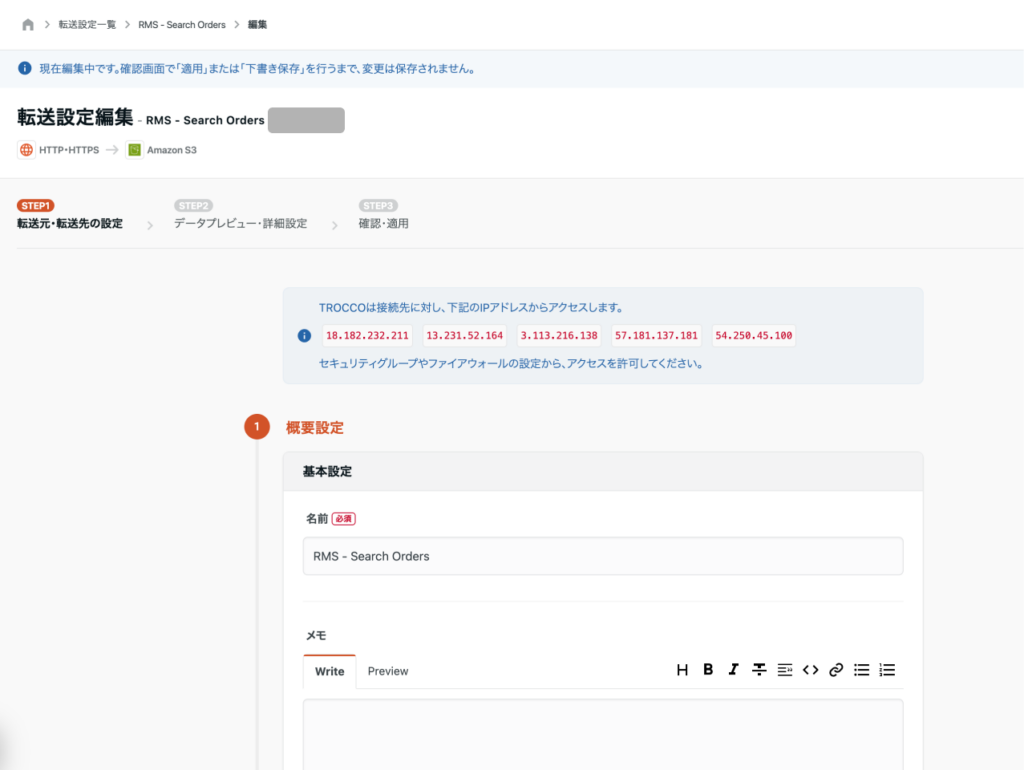
[データ転送] → [転送設定] をクリックし、[新規転送設定作成] ボタンを押します。
転送元で「HTTP・HTTPS」を選択し、転送先には「Amazon S3」を選択します。
転送元・転送先の設定
転送元:HTTP・HTTPS
- 転送設定名:
RMS - Search Orders - URL:
https://api.rms.rakuten.co.jp/es/2.0/order/searchOrder/ - HTTPメソッド:
POST - 入力ファイル形式:
JSON Lines
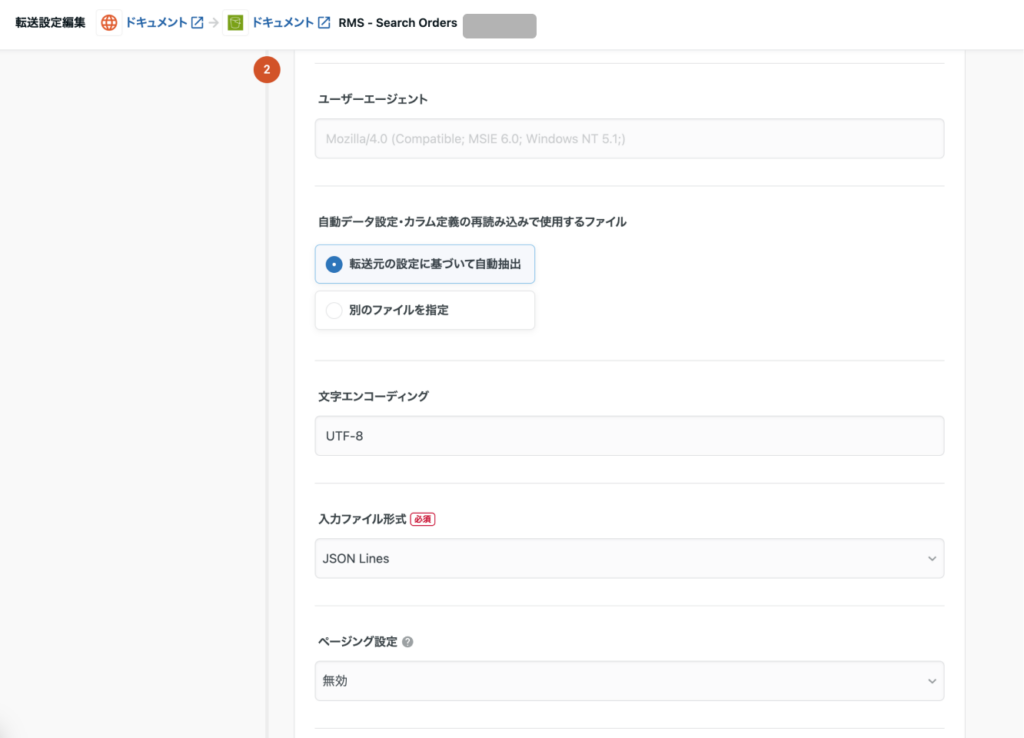
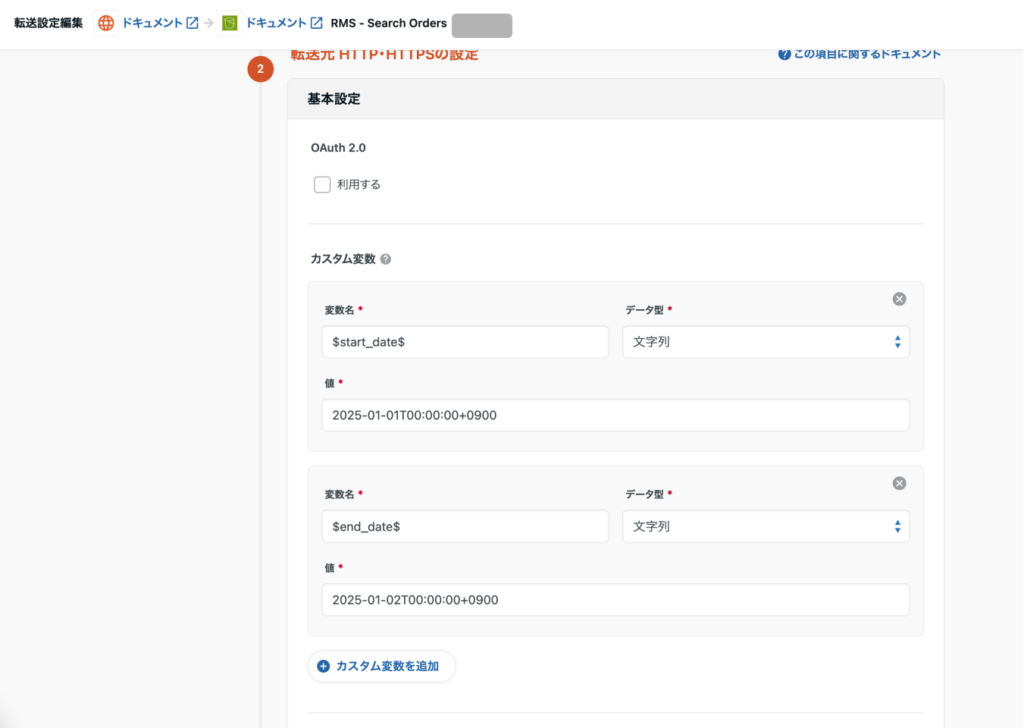
- カスタム変数:
- ジョブ実行時間をもとに自動的にデータを絞り込むため、リクエストボディーで利用する日時の変数定義を行います。長期間の一括取得は負荷・制限で失敗しやすいため、日別/時間別に分割して取り込むようにします。
- 開始日時
- 変数名:
$start_date$ - データ型:
文字列 - 値:
2025-01-01T00:00:00+0900
- 変数名:
- 終了日時
- 変数名:
$end_date$ - データ型:
文字列 - 値:
2025-01-02T00:00:00+0900
- 変数名:
- リクエストのボディー
- 定義したカスタム変数を挿入します
{
"dateType": 1,
"startDatetime": "$start_date$",
"endDatetime": "$end_date$",
"PaginationRequestModel": {
"requestRecordsAmount": 1000,
"requestPage": 1
}
}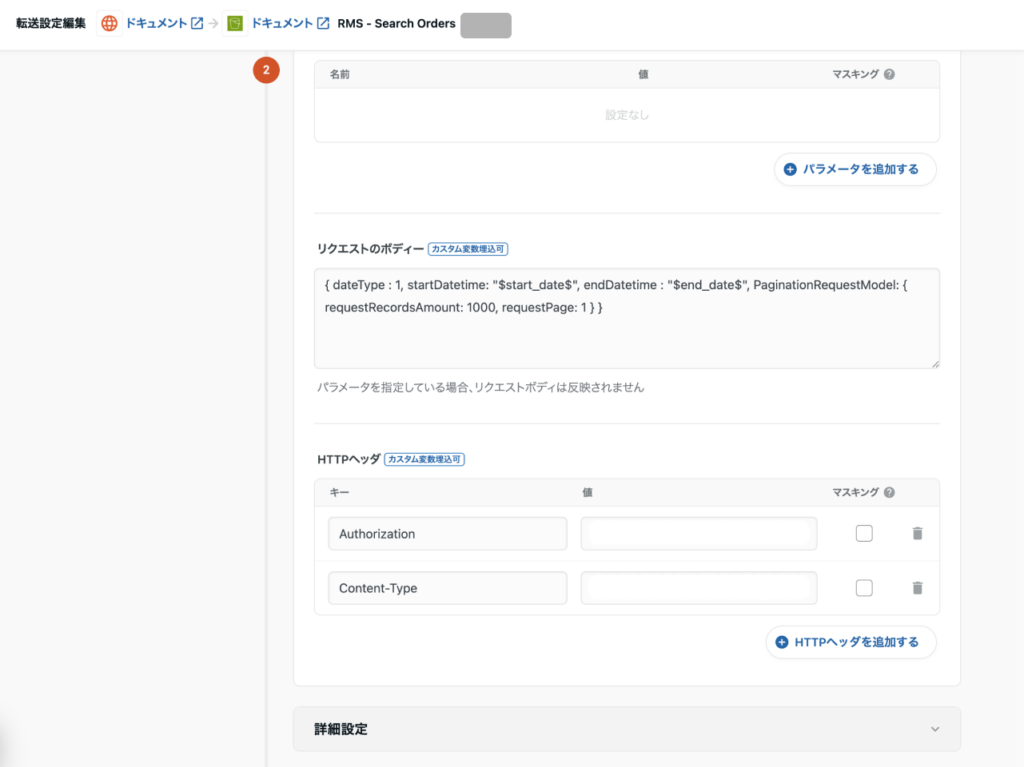
- HTTPヘッダ:
Authorization: ESA <Base64(serviceSecret:licenseKey)>Content-Type: application/json; charset=utf-8- 「マスキング」にチェックを入れることで値の暗号化保存ができます。APIキーなどの認証に使う値を登録する場合はマスキングへチェックを入れてください。
- ライセンスキーには有効期限があるため注意してください。詳細は楽天RMSのマニュアルをご参照ください。
転送先:S3
転送先の設定は次のドキュメントを参照して設定してください。
パスプレフィックスには、出力先となるS3バケット内のディレクトリを指定します。
たとえば、午前と午後などの2回にわけて分割取得を実行する場合は、カスタム変数を利用してパスプレフィックスを動的に設計することで、日付や時間帯ごとにデータを自動的に振り分けることができます。
- パスプレフィックス:
/rms/order_numbers/$date$/$number$/
以降の手順については通常の転送設定と同様のため、ヘルプドキュメントを参照してください。
STEP3|転送設定の作成:注文詳細を取得してS3に保存(getOrder)
次に、searchOrder で得た注文番号リストを変数として受け取り、100件/リクエストで分割し詳細データを取得する設定を行います。
転送元で「HTTP・HTTPS」を選択し、転送先には「Amazon S3」を選択します。
転送元:HTTP・HTTPS
- 転送設定名:
RMS - Orders - URL:
https://api.rms.rakuten.co.jp/es/2.0/order/getOrder/ - HTTPメソッド:
POST - 入力ファイル形式:
JSONPath - ルート:
$.OrderModelList[*] - HTTPヘッダ:searchOrderと同様に設定
- カスタム変数:
- 変数名:
$order_number_list$- データ型:
文字列 - 値:
[“{実在するorder_number1}”, “{実在するorder_number2}”]
- データ型:
- 変数名:
$date$- データ型:
文字列 - 値:
20251010
- データ型:
- 変数名:
$number$- データ型:
文字列 - 値:
1
- データ型:
- 変数名:
- リクエストのボディー:
$order_number_list$は後述のカスタム変数ループでSnowflakeから読み出した100件の注文データの配列を差し込みます。
{
"orderNumberList": $order_number_list$
}転送先:S3
searchOrderと同様に設定します。
STEP4|データマートの作成
次にSnowflake Taskを実行するデータマート定義を作成します。
[データマート] → [データマート定義] をクリックし、[新規データマート定義作成] ボタンを押します。
「Snowflake」を選択します。
- クエリ実行モード:
自由記述モード- 接続先のDWHに対して、任意のクエリ (DDL、DELETE、INSERTなど) を自由に実行することができるモードです。このモードを選択するとSnowflake Taskの実行も可能です。
- クエリ
EXECUTE TASK <タスク名>;- ※ タスクを実行するには、タスクの OWNERSHIP または OPERATE 権限が必要です。詳細は Snowflake のドキュメントを参照してください。https://docs.snowflake.com/ja/sql-reference/sql/execute-task
その他のデータマートの設定についてはヘルプドキュメントを参照してください。
データを加工する
データマート – Snowflake
STEP5|ワークフローの構築:転送設定とデータマート定義を連携する
最後に、2つの転送設定とデータマート定義を組み合わせ、一連の自動処理を組んでいきます。
本構成では、searchOrder →(Snowflake Task)→ getOrder →(Snowflake Task) の順に処理を連携します。TROCCOのワークフローは次の 4ジョブ構成 です。
ワークフロー設定
以下を直列につなげます。
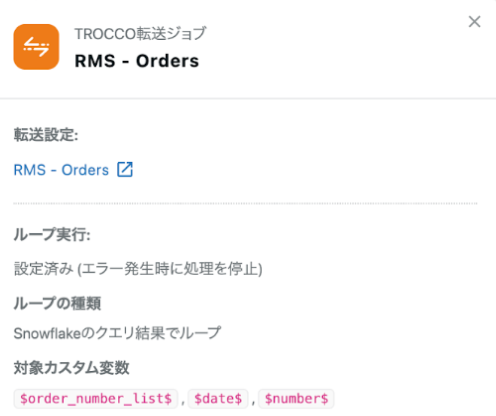
- ジョブ1:
RMS - Search Orders - ジョブ2:
Snowflake Task データマート - ジョブ3:
RMS - Orders(依存:ジョブ1)- カスタム変数ループを設定
- ループの種類:
Snowflakeのクエリ結果でループ - 変数:
$order_number_list$, $date$, $number$
- ループの種類:
- カスタム変数ループを設定
- ジョブ4:
Snowflake Task データマート

ジョブ3の設定について
注文が多い日も安定的にデータ取得ができるように100件ずつのバッチに分割して、データ取得を行えるように設定します。
getOrderは、1リクエストあたり取得できる最大件数が100件に制限されているためです。
- ワークフローのカスタム変数ループで100件ずつの
order_number_listを取得するクエリを記述し、getOrderを分割バッチでデータ取得 - 失敗時はそのバッチだけ再実行(部分リカバリ)
Snowflakeのクエリ結果でループの設定例
-- chunk_size: 100 件ずつに分割
WITH exploded AS (
SELECT
SPLIT_PART(f.value::string, '-', 2) AS yyyymmdd,
f.value::string AS ordernumber,
SPLIT_PART(f.value::string, '-', 3) AS seq
FROM raw.rakuten_rms.search_order AS t,
LATERAL FLATTEN(input => TRY_PARSE_JSON(t.ORDERNUMBERLIST)) AS f
WHERE f.value IS NOT NULL
),
numbered AS (
SELECT
yyyymmdd,
ordernumber,
seq,
ROW_NUMBER() OVER (
PARTITION BY yyyymmdd
ORDER BY seq, ordernumber
) AS rn
FROM exploded
),
bucketed AS (
SELECT
yyyymmdd,
CAST(CEIL(rn / 100.0) AS NUMBER) AS split_no, -- 1, 2, 3, ...
rn,
ordernumber
FROM numbered
)
SELECT
ARRAY_AGG(ordernumber) WITHIN GROUP (ORDER BY rn) AS ordernumberlist,
yyyymmdd,
split_no
FROM bucketed
GROUP BY ALL
ORDER BY yyyymmdd, split_no;クエリ結果の列数とカスタム変数の数が一致するようなクエリを設定してください。それ以外の場合にはエラーとなりますのでご注意ください。
スケジュール & 通知(運用)
自動実行を行うためスケジュールと通知を設定します。
- スケジュール設定:毎日 09:00(JST)
- 通知設定:失敗時にSlack通知
- メッセージ例:
[TROCCO] 楽天データ取得失敗(本番)
- メッセージ例:
楽天RMS API連携を活用したユースケース
実装方法を解説してきましたが、他にも以下のようなユースケースの利用が可能になります。興味があるものは一度実装をお試しください。
- 日次売上レポートの自動化:日次売上レポートの自動化 ― 毎朝“最新”で意思決定を早く
- 在庫連携:欠品/過剰在庫の抑制(需給の平準化)
- 注文データの流入をトリガーに在庫引当・自動発注までのリードタイムを短縮し、欠品と過剰の両方を抑えます。
- 顧客・地域分析:LTV/リピート率、エリア別プロモ最適化
まとめ
楽天RMS APIのように2段階で取得する必要があるAPIでも、TROCCOの転送元HTTP・HTTPSとワークフロー機能を組み合わせることで、データ連携を簡単に自動化できます。手作業によるデータ取得や、開発コスト・運用負荷に悩まされているEC事業者にとって、TROCCOは強力な解決策となるでしょう。
ぜひ無料トライアルでその設定の手軽さをお試しください。
※転送元HTTP・HTTPSコネクタは、TROCCO の Advanced プラン以上のプランでご利用いただける機能です。






