
本記事では、データウェアハウス(DWH)、ETLプロセス、BIツールなどのアップデート情報や最新トレンドを毎月わかりやすくお届けします。
主要なニュースをピックアップしているので、サクッと最新情報をキャッチアップしたい方は、ぜひご覧ください。
Data Engineering Newsの公開時にメール通知をご希望の方は、こちらのフォームよりご登録ください。
| 今月のData Engineering Newsの共同著者は以下のメンバーです。 小宮山誉人、河野浩明、海藤公紀、若松拓夢、鈴木大介、片貝桃子、西山徹、鳩洋子、廣瀬智史 |
|---|
Google BigQueryのニュースまとめ
BigQuery パイプラインでタスクとしてテーブルとビューの追加が可能になりました
BigQuery パイプラインで、SQLクエリ等の処理タスクに加え、テーブルやビューそのものを依存関係のタスクとして定義できるようになりました。この機能はプレビューとして提供開始されています。
これにより、テーブルやビューの定義の更新を検知してから後続タスクを実行できるようになり、より柔軟なデータパイプラインの構築が可能になります。
BigQuery で Gemini によるSQLコード補完がプレビューになりました
BigQuery のクエリエディタに、Gemini によるコード補完機能が搭載されました。
クエリの文脈を理解してコードブロック全体を提案します。
これにより、SQLコーディングの生産性が向上し、タイプミスなどのエラーを削減できます。
BigQuery ML でモデルモニタリングの結果を VertexAI で確認できる機能が一般提供開始されました
ML.VALIDATA_DATA_SKEW や ML.VALIDATA_DATA_DRIFT といったモデルモニタリングの実行結果を、VertexAI 上のグラフやチャートで確認できるようになりました。
これにより、学習時と予測時でのデータ分布のズレ(スキュー)や、時間経過によるデータの変化(ドリフト)を、SQLの結果から直接分析できます。
GoogleSQL の配列関数 ARRAY_FIRST, ARRAY_LAST, ARRAY_SLICE が一般提供開始されました
配列の要素を取得する操作が、専用関数で実行できるようになりました。
- ARRAY_FIRST:配列の最初の要素を返します
- ARRAY_LAST:配列の最後の要素を返します
- ARRAY_SLICE:連続するゼロ個以上の要素を含む配列を返します
これにより、従来の OFFSET を使った構文や UNNEST を伴う複雑なクエリが不要になり、SQL の可読性と生産性が向上します。
BigQuery advanced runtime が一般提供開始されました
この機能を有効にすることで、クエリの実行時間の短縮やコンピューティングリソース(スロット)の利用効率向上が期待できます。
本章の執筆者:小宮山誉人(Data Analyst)
Snowflakeのニュースまとめ
Snowpipe Streaming High-Performance Architectureが一般提供開始されました
高スループット・高効率を実現する新しいストリーミングアーキテクチャがGeneral Availabilityとなりました。新しいPIPEオブジェクトを使用し、データ取り込み中のクラスタリング、軽量な変換、サーバーサイドスキーマ検証をサポートします。
価格モデルも非圧縮データ量ベースの従量課金制へと変更され、より予測可能なコストモデルになりました。 データ基盤運営において、リアルタイムデータ取り込みの性能が大幅に改善され、ストリーミングデータの処理コストが予測しやすくなります。これにより、IoTデータやクリックストリームなど大量のストリーミングデータを扱うユースケースでのROIが改善し、リアルタイム分析基盤の構築が容易になるでしょう。また、取り込み時の変換機能により、ETLパイプラインの簡素化も期待できます。
Cortex AISQL AI Translateが一般提供開始されました
SQLクエリで直接多言語翻訳を実行できるAI_TRANSLATE関数がGeneral Availabilityとなりました。最新のAIモデルを使用し、市場で最も強力なモデルと同等の翻訳品質を提供します。
混在言語テキストの翻訳もサポートし、構造化・非構造化データの両方で利用可能です。 グローバル企業のデータ基盤では、多言語データの処理が大きな課題でしたが、SQL内で直接翻訳処理が可能になることで、データパイプラインが大幅に簡素化されます。リアルタイムで多言語カスタマーレビューの分析や、グローバルなセンチメント分析が容易になり、ビジネスインサイトの獲得速度が向上するでしょう。
Cortex Agents for Microsoft Teams and Copilotが一般提供開始されました
SnowflakeのCortex AgentsがMicrosoft TeamsとMicrosoft 365 Copilotと統合され、自然言語でSnowflakeデータにアクセスできるようになりました。Teams内でチャットボットとして、またはCopilot内で直接データ分析や可視化が可能になり、SnowflakeのRBAC権限もそのまま適用されます。
ビジネスユーザーのセルフサービス分析が大幅に促進され、データ民主化が加速します。技術的なスキルを持たないユーザーでも、普段使っているTeamsやCopilotから直接データ分析ができるため、データ活用のハードルが大きく下がります。IT部門の負担も軽減され、ガバナンスを保ちながら組織全体のデータ活用度を向上させることができるでしょう。
FILE Data Typeが一般提供開始されました
非構造化データを直接Snowflakeテーブル内に保存・管理できるFILEデータ型がGeneral Availabilityとなりました。画像、PDF、ドキュメントなどのファイルをテーブルの列として保存でき、構造化データと非構造化データを統一的に管理できます。
データ基盤において、構造化データと非構造化データの分離管理は長年の課題でしたが、FILEデータ型により統一的な管理が可能になります。これにより、ドキュメント管理システムと分析基盤の統合が容易になり、AI/MLワークロードでの画像・文書データの活用が促進されます。データガバナンスも一元化され、管理コストの削減が期待できます。
詳細は公式ドキュメントをご確認ください。
本章の執筆者:河野浩明(Data Engineer)
AWSのニュースまとめ
Amazon OpenSearch Service が Star-Tree Index を発表しました
Amazon OpenSearch ServiceでStar-Tree Indexという新機能が利用開始となりました。この機能により、大量データの集計処理が大幅に高速化され、従来時間がかかっていた複雑な分析クエリもサブ秒で応答できるようになります。
データを事前に集計して保存するため、リアルタイムダッシュボードや監視システム、パーソナライゼーション機能などで威力を発揮します。例えば、数億件のログデータから複数のディメンションで集計を行う処理が、従来は数分かかっていたものが1秒未満で完了するようになります。
Amazon S3 が汎用バケットで条件付き削除をサポート開始しました
Amazon S3の汎用バケットで条件付き削除機能が追加されました。HTTP if-matchヘッダーとETagを使用し、オブジェクトが変更されていない場合のみ削除を実行できます。
複数のユーザーが同時にファイルを操作する環境で、誤ってファイルを削除してしまうリスクを大幅に軽減できます。従来は削除前にオブジェクトの状態を確認する仕組みがなく、競合状態での誤削除が課題でした。全リージョンで追加コストなしで利用可能です。
データパイプラインで複数のプロセスが同じファイルを処理する場合、あるプロセスがファイルを読み込んだ後、別のプロセスが削除してしまう問題を防ぐことができます。これにより、並行処理の安全性が向上します。
S3 コンソールで Amazon S3 Tables のプレビューが可能になりました
Amazon S3 TablesをS3コンソールから直接確認できるようになりました。これまでSQLクエリを書く必要がありましたが、今回のアップデートでテーブルのスキーマやサンプルデータをコンソール上で手軽に確認できます。
データの構造や内容を素早く把握したい場面で特に便利で、セットアップも不要です。
データエンジニアやアナリストが、SQLクライアントを立ち上げることなく、ブラウザ上でテーブルの内容を確認できるため、データ探索の効率が大幅に向上します。特にデータカタログとしてS3 Tablesを活用している組織において、データ発見とアクセスのハードルが下がります。
Amazon ECS Managed Instances を発表しました
Amazon ECS Managed Instancesが発表されました。このサービスはECSにおいてEC2を利用時に、EC2のインフラストラクチャ管理をAWSに任せつつ、全機能へのアクセスを提供するよう設計された、新しいフルマネージドのオプションです。
今回の機能によりvCPU数やメモリサイズを指定するだけで最適なEC2インスタンスが自動でプロビジョニングされ、動的スケーリングや、14日ごとのセキュリティパッチもAWSに任せることが可能になります。
これまでECSでは、Fargate(完全マネージドだが機能制限あり)とEC2(全機能利用可能だが管理が必要)の2択でしたが、Managed Instancesにより、EC2の柔軟性とFargateの運用容易性を両立できるようになりました。データパイプラインでGPUやカスタムインスタンスタイプが必要な場合でも、インフラ管理の負担を軽減できます。
本章の執筆者:海藤公紀(Data Engineer)
Looker Studioのニュースまとめ
Looker Studio Explorer(ベータ版)機能の提供が終了しました
Looker Studio の Explorer(ベータ版)機能は廃止され、今後利用できなくなります。
対応は不要です。 Explorer で作成された既存の探索は、自動的にレポートへ変換されます。
提供終了のタイムラインや詳細については、こちらをご確認ください。
閲覧者の認証情報を使用するデータソースでのハイパーリンクと画像の無効化されました
データソースに対して閲覧者の認証情報を有効にすると、そのデータソース内のディメンションに含まれる ハイパーリンクや画像は Looker Studio 上で表示されなくなります。
なお、この制限は レポート作成者とビューアが同じチーム ワークスペースに所属している場合には適用されません。
詳細は公式ドキュメントをご確認ください。
Google 広告から利用できるデータ項目が追加されました
Google 広告コネクタを使用して、以下のフィールドを Looker Studio で可視化できるようになりました。これにより、コンバージョン指標や収益性の分析をより詳細に行うことができます。
- コンバージョン(コンバージョン日別)
- コンバージョン値(コンバージョン日別)
- すべてのコンバージョン(コンバージョン日別)
- すべてのコンバージョン値(コンバージョン日別)
- 新規 vs. リピーター顧客
- 粗利益
- 粗利益率
その他のアップデート
レスポンシブ レポートでの縦方向の積み重ねがサポート開始されました
レスポンシブ レポートで縦方向の積み重ねがサポートされるようになりました。これにより、セクション内の列に複数のコンポーネントを追加できます。
ツリーマップ チャートの改善が加えられました
ツリーマップ チャートに以下の改善が加えられました。
- 新しい「フィールド」セクション: レポート編集者がチャートの配色の基準として使用するディメンションまたは指標を指定できるようになりました。
- 新しい配色オプション: 「フィールド」セクションでの選択内容に基づいた色の指定が可能になりました。
- 新しい「角丸」: 設定レポート編集者がツリーブランチの枠線の角丸をコントロールできるようになりました。
- 新しい「ラベル」セクション:
詳細は公式ドキュメントを確認してください。
テーブルチャートで最大10項目までのソートが可能になりました
レポートエディタで、テーブルチャートに最大10個のソート項目を設定できるようになりました。これにより、複雑なデータテーブルでも、より柔軟で詳細な並べ替えが可能になります。
詳しくは公式ドキュメントをご覧ください。
Looker コネクタの機能強化がありました
Looker データソースでは、フィールド名が先頭のビュー名を含まずに表示されるようになりました。また、フィールドは対応するビューの下に階層的に整理されるようになり、より見やすく直感的な構造になっています。
詳細は公式ドキュメントをご覧ください。
ユーザーインターフェースで「クイックフィルタを追加」が「フィルタを追加」に変更されました
レポートエディタ内のフィルタバーの文言を変更しました。これまで 「クイックフィルタを追加」 と表示されていたボタンは、「フィルタを追加」 に変更されています。なお、クイックフィルタの機能自体に変更はありません。
詳しくは公式ドキュメントをご覧ください。
ダブルクリックでチャートのマージンをリセット可能になりました
タイムチャート、棒グラフ、折れ線グラフ、エリアチャート、散布図のチャート境界(マージン)をダブルクリックすることで、デフォルト設定にリセットできるようになりました。
これにより、手動で変更したマージンを簡単に初期状態へ戻すことができ、チャートレイアウトの調整がよりスムーズになります。
パートナーコネクションのアップデートがされました
Looker Studio コネクタギャラリーに以下のパートナーコネクタが新たに追加されました。
- HubSpot (Adzviser 提供)
- Amazon Seller Central ( Adzviser 提供)
- Amazon Ads(Adzviser 提供)
- Odoo Appointment AppiWorks(Jivrus Technologies 提供)
- Snowflake(Supermetrics 提供)
- GA4 Annotations(ReallyGoodData 提供)
- 800.com Call Analytics(800.com 提供)
- TikTok Shop(Supermetrics 提供)
- seoClarity Keyword Details(seoClarity 提供)
- seoClarity Domain Summary(seoClarity 提供)
- Odoo Subscription AppiWorks(Jivrus Technologies 提供)
- Amazon DSP(Dataslayer 提供)
- Etsy(Power My Analytics 提供)
- SeoSamba CRM(SeoSamba 提供)
- Google BigQuery(Supermetrics 提供)
- Microsoft Ads(Porter Metrics 提供)
- Outbrain DSP(Catchr 提供)
- The Trade Desk(Catchr 提供)
- Close.com(Windsor.ai 提供)
- Odoo Invoice AppiWorks(Jivrus Technologies 提供)
本章の執筆者:若松拓夢(Data Analyst)
Looker Studio Proのニュースまとめ
スケジュール可能なレポート数が200に拡大しました
Looker Studio Pro では、スケジュール可能なレポートについてこれまで1つのレポートにつき20件だったのが、最大200件作成できるようになりました。
本章の執筆者:若松拓夢(DataAnalyst)
dbtのニュースまとめ
MetricFlowの派生メトリクスにおけるオフセット処理が改善されました
MetricFlowにおける派生メトリクスのオフセット機能の処理方法が改善され、時系列データをクエリする際により正確な結果が得られるようになりました。派生メトリクスのオフセット機能は、月次売上の前月比や前年同月比など、異なる時期のメトリクスを比較する際に使用される機能です。
従来は、例えば9月の売上と8月の売上を比較する際に、オフセット結合が集約の前に適用されていたため、全期間から一部の値が除外され、不完全な比較結果になる可能性がありました。
今回の改善により、クエリの粒度がオフセットの粒度と一致する場合、MetricFlowは集約の後にデータを結合するように変更されました。これにより、全期間のデータが正確に反映された時系列比較が可能になり、より信頼性の高いメトリクス計算が実現されます。
詳細は公式ドキュメントを参照ください。
本章の執筆者:鈴木大介(Product Marketing Manager)
Tableauのニュースまとめ
Tableau Pulse – 動的な日付オフセットが設定可能になりました
時系列型のメトリクスでは、表示される値は当日の日付の値です。データソースに当日のデータがない場合、その値はnullになります。
メトリクス定義で日付オフセットを設定すると、nullではなく過去の日付の値を表示できるようになります。
これまでは「過去〇日前」といった静的なオフセットのみ設定できましたが、新たに動的オフセットがサポートされ、データが存在する最新の日付に自動で調整できるようになりました。
詳細は公式ドキュメントを参照ください。
Tableau Cloud – 新しい地域(リージョン)のサポート
Tableau Cloudでは、サイトおよびそのデータを保存するリージョンを選択できるように設計されています。
今回、新たにインドと韓国が選択可能なリージョンとして追加されました。
詳細は公式ドキュメントを参照ください。
本章の執筆者:片貝桃子(Data Analyst)
Databricksのニュースまとめ
Databricks Oneがパブリックプレビューとして提供開始されました
ビジネスユーザー向けに設計されたシンプルなユーザーインターフェースであるDatabricks Oneがパブリックプレビューとして提供開始されました。Databricks Oneは、コンピュートリソース、クエリ、モデル、ノートブックに関する技術的知識を必要とせずに、DatabricksのデータとAIを操作するための単一の直感的なエントリポイントを提供します。
Databricks Oneでは、ビジネスユーザーが以下を実行できます:
- KPIの追跡とメトリクスの分析のためにAI/BIダッシュボードを表示・操作
- AI/BI Genieを使用して自然言語でデータに関する質問
- 分析、AI、ワークフローを組み合わせたカスタム構築Databricks Appsの使用
ワークスペース管理者は、管理コンソールのPreviewsページからDatabricks Oneを有効化できます。
Pipeline update timeline tableがパブリックプレビューとして提供開始されました
system.lakeflow.pipeline_update_timelineテーブルが提供開始され、パイプライン更新の完全な履歴追跡が可能になりました。このテーブルは、更新アクティビティ、トリガー、結果、コンピュート使用量の詳細な分析をサポートします。
Lakeflow Pipelines Editorがパブリックプレビューとして提供開始されました
Lakeflow Pipelines Editor(以前のマルチファイルエディタ)がパブリックプレビューとして提供開始されました。このエディタは、パイプラインをパイプラインアセットブラウザ内のファイルセットとして表示します。1つの場所でファイルの編集、パイプライン構成の制御、パイプラインに含めるファイルの指定が可能になりました。これにより、パイプラインのデフォルトソースコード形式がノートブックからPythonおよびSQLコードファイルに変更されました。
Google Analytics Raw Dataコネクタが一般提供開始されました
Lakeflow ConnectのGoogle Analytics Raw Dataコネクタが一般提供開始されました。
SQL ServerコネクタがSCD type 2をサポートしました
Lakeflow ConnectのMicrosoft SQL Serverコネクタで、SCD type 2がサポートされました。この設定は、履歴追跡または緩やかに変化するディメンション(SCD)とも呼ばれ、データの経時的な変更の処理方法を決定します。履歴追跡をオフ(SCD type 1)にすると、古いレコードは更新・削除時に上書きされます。履歴追跡をオン(SCD type 2)にすると、コネクタはこれらの変更の履歴を保持します。
Delta Sharing on Lakehouse Federationがベータ版として提供開始されました
Delta Sharingを使用して、Databricksでquery federationで作成された外部スキーマとテーブルを、Databricks間共有とオープン共有の両方で共有できるようになりました。
SAP Business Data Cloud (BDC) Connector for Databricksが一般提供開始されました
SAP BDC Connectorにより、SAP BDCとUnity Catalog対応Databricksワークスペース間でセキュアなゼロコピーデータ共有が可能になりました。DatabricksでSAP BDCデータにアクセスして分析し、DatabricksデータアセットをSAP BDCに共有することで、両プラットフォーム間で統合された分析が実現します。
Anthropic Claude Opus 4.1がDatabricksホスト型基盤モデルとして利用可能になりました
Mosaic AI Model ServingでAnthropic Claude Opus 4.1がDatabricksホスト型基盤モデルとしてサポートされました。このモデルには、Foundation Model APIのトークンごとの課金を使用してアクセスできます。
LLMを使用したテーブルデータの探索が可能になりました(パブリックプレビュー)
Catalog Explorerを使用して、サンプルデータについて自然言語で質問できるようになりました。アシスタントは、メタデータコンテキストとテーブルの使用パターンを使用してSQLクエリを生成します。その後、クエリを検証してから基礎となるテーブルに対して実行できます。
Databricks Assistant Agent Mode: Data Science Agentがベータ版として提供開始されました
Databricks AssistantのAgent Modeがベータ版として提供開始されました。Agent Modeでは、Assistantが単一のプロンプトからマルチステップワークフローをオーケストレーションできます。Data Science Agentは、データサイエンスワークフロー向けにカスタム構築されており、EDA、予測、機械学習などのタスク用にノートブック全体を一から構築できます。プロンプトを使用して、ソリューションの計画、関連アセットの取得、コードの実行、セル出力を使用した結果の改善、エラーの自動修正などが可能です。
MLflowメタデータがsystem tablesで利用可能になりました(パブリックプレビュー)
MLflowメタデータがsystem tablesで利用可能になりました。MLflow追跡サービス内で管理されているワークスペース全体のメタデータを1つの中央ロケーションから表示でき、カスタムAI/BIダッシュボード、SQLアラート、大規模データ分析クエリの構築など、Databricksが提供するすべてのレイクハウスツールを活用できます。
Databricks Online Feature Storesがパブリックプレビューとして提供開始されました
Lakebaseを活用したDatabricks Online Feature Storesにより、オフライン特徴量テーブルとの一貫性を維持しながら、特徴量データへの高スケーラブルで低レイテンシのアクセスが提供されます。Unity Catalog、MLflow、Mosaic AI Model Servingとのネイティブ統合により、モデルエンドポイント、エージェント、ルールエンジンを本番環境化し、高パフォーマンスを維持しながらOnline Feature Storesから特徴量に自動的かつ安全にアクセスできるようにします。
Data classificationシステムテーブルがベータ版として提供開始されました
新しいシステムテーブルsystem.data_classification.resultsがベータ版として利用可能になりました。このテーブルは、メタストア内の有効化されたすべてのカタログにわたって、列レベルでの機密データの検出結果を記録します。
Databricks AppsがGenieリソースをサポートしました
Databricks Appsで、AI/BI Genieスペースをアプリリソースとして追加し、キュレートされたデータセットに対する自然言語クエリを有効化できるようになりました。
Microsoft Power PlatformのDatabricksコネクタがパブリックプレビューとして提供開始されました
Power PlatformでDatabricks connectionを作成することで、DatabricksデータをPower Appsのcanvas apps、Power Automateのflows、Copilot Studioのagents構築に使用できるようになりました。
本章の執筆者:西山徹(Senior Product Manager)
TROCCOのニュースまとめ
新機能リリース: 環境管理機能がリリースされました
複数環境(開発・検証・本番など)を分けて管理できる環境管理機能が提供開始されました。
これにより、設定変更を段階的にデプロイでき、安全な運用が実現できます。
詳しくは環境管理機能を参照ください。
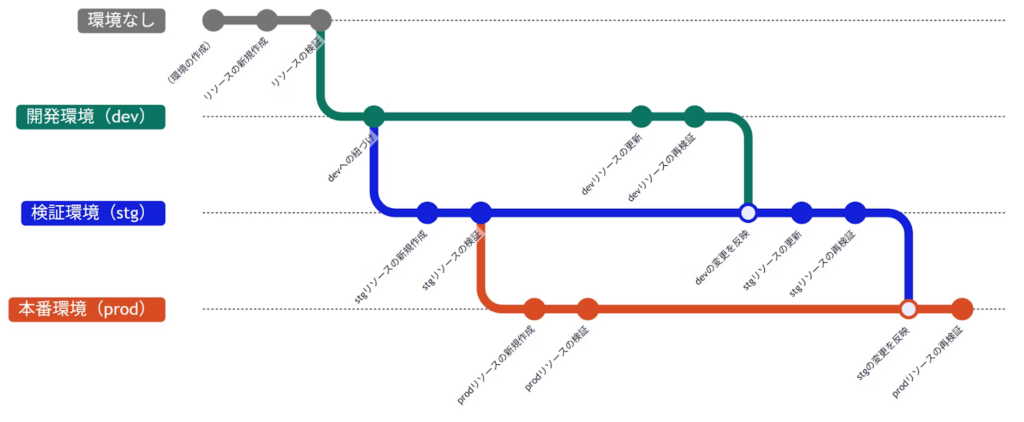
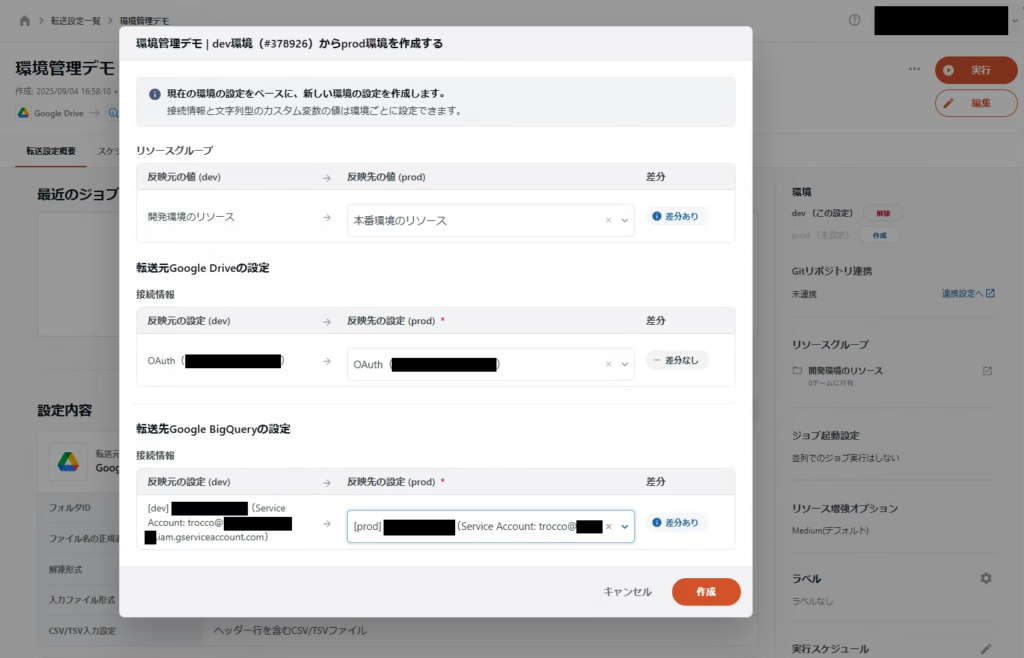
【機能解説記事】もう間違えて本番環境を壊さない!TROCCOの環境管理で、堅牢なデータパイプライン開発を実現する
コネクタ新規リリース: 転送元コネクタが追加されました
以下の転送元コネクタが新たに追加されました。
- Db2 for LUW
- Bill One
- ClickUp
- BIZTEL
これにより、より多様な業務データソースとの連携が可能となりました。
詳しくは各ドキュメント(接続情報 – Db2 for LUW・転送元 – Db2 for LUWなど)を参照ください。
コネクタ改善: Shopify・Salesforce・Oracle Databaseなどが強化されました
複数の既存コネクタにおいて機能改善が行われました。
- 転送元Shopify
- ターゲットmetafieldsで、オーナー作成日時によるデータ絞り込みが可能に
- fulfillment_line_itemsおよびrefund_line_itemsの取得に対応
- fulfillmentsターゲットで更新日時フィルターが利用可能に
- 転送先Salesforce
- OAuth認証に対応し、よりセキュアな接続が可能に
- 転送元Oracle Database
- 接続タイプに「サービス名」を指定してデータベースを選択可能に
- 転送元MongoDB
クエリ内でカスタム変数を埋め込み可能に - 転送元Tiktok Ads
- 削除済み広告データの取得を制御可能に
- 転送元Sansan
- 名刺・人物データで付与されたタグ情報を取得可能に
- 接続情報 Microsoft SQL Server
- JDBCドライバー12.6を選択することで、SQL Server 2022へ対応可能に
- 共通改善
- JSON展開カラムもカラム名・データ型の一括変換が可能に
CDC: 転送元スキーマ変更への自動追従機能が追加されました
CDCデータ転送で転送元スキーマの変更(カラム・テーブル追加など)を検知し、転送先スキーマへの自動追従が可能になりました。通知のみを行い手動追従することも可能です。また、「自動追従しない」設定でも変更通知が届くようになりました。
詳しくはCDCスキーマ自動追従を参照ください。
データマート: Databricksが追加されました
新たにDatabricksがデータマートとして追加されました。これにより転送設定と組み合わせて、Databricksの活用がより柔軟にできるようになります。
詳細はデータマート – Databricksを参照ください。
データマート: Snowflakeではクエリのタイムアウトが指定可能になりました
クエリのタイムアウトを指定できる「ステートメントタイムアウト」設定が追加されました。
ワークフロー: 環境条件での分岐が可能になりました
条件分岐タスクにおいて、ワークフローの「環境」を条件として利用できるようになりました。開発・検証・本番など環境ごとの制御が容易になります。
UI・UX: 接続情報一覧やリソース管理画面が大幅に改善されました
- 接続情報一覧で、どのリソースに利用されているか確認可能に
- 接続情報一覧で、絞り込み・ソート機能を追加
- データマート・ワークフロー定義画面で、リソースグループの一括操作が可能に
これにより、設定や依存関係の可視化・管理効率が向上しています。
UI・UX: 通知メッセージでカスタム変数が使用可能になりました
アラート通知のメッセージ本文にカスタム変数を埋め込み、IDなどの付与で通知だけで概要を把握しやすくなりました。
コネクタAPIアップデート: HubSpot/Yahoo!広告/Facebook関連をアップデートしました
- HubSpot: 使用ライブラリをv20へ(HubSpot API Ruby v20.0.0)
- Yahoo!ディスプレイ広告(運用型): v17へ
- Yahoo!検索広告: v17へ
- Facebook関連(Ad Insights/クリエイティブ/リード広告/コンバージョンAPI/カスタムオーディエンス(β)/OAuth認証): Graph API v23へ
お知らせ: パスワードポリシーが変更されました
パスワードの最低文字数が8文字から12文字に変更されました。
既存ユーザーには影響ありませんが、新規設定時にはご注意ください。
本章の執筆者:鳩洋子(Product Manager)
COMETAのニュースまとめ
Amazon Redshiftとの連携がサポートされました
これまでデータストアとして作成できるデータウェアハウスとしてはSnowflake、Google BigQueryをサポートしていました。
今回のリリースにより、新たにAmazon Redshiftについてもデータストアを作成できるようになり、COMETAにてアセットを管理・活用できるようになります。
Redshiftとの連携において、リリース時点でサポートしている機能は下記に記載がありますので、ご利用の際にはご参照ください。
また、連携方法の詳細については下記ドキュメントをご参照ください。
AIチャットが自律的に動作しアセットの検索やSQLが生成されるようになりました
これまで、AIチャットの動作は質問に対し1つの回答を返す動作となっていました。
今回、AIチャットをAgent化することで、質問に対してAIが自律的に動作し、アセットの検索やSQL生成が行われるようになりました。また、回答に至る思考プロセスなども逐次表示されるようになりました。
このリリースにより、ユーザーは期待される回答を得られやすくなり、また逐次表示サポートにより回答が完全に作成されるまで待つ必要がなくなることで体験が改善されています。
本章の執筆者:廣瀬智史(Staff Product Manager)
Data Engineering Newsは毎月更新でお届けいたします。記事公開の新着メール通知をご希望の方はこちらのフォームよりご登録ください。





