
データウェアハウスの導入を検討する際、必ず確認するポイントは、いかにデータを安全に連携できるかということでしょう。
クラウドを活用することで、「本当に使えるデータ分析基盤」を低コスト・低工数で構築し、セキュアに運用することができます。
この記事は、2022年6月に「Amzon Redshift×TROCCO®でセキュアなデータ分析基盤構築」と題し行われたセミナーを元に、「クラウドによる分析基盤の構築」について詳しく解説します。
この記事を読んでいただくことで、以下のようなことがお分かりいただけると思います。
- データを有効活用するために最適なデータ分析基盤構成
- Amazon Redshiftを活用するメリット
- クラウドベースのセキュアなデータ分析基盤の構築手法
なお、当日のセミナーはこちらからもご覧いただけます。
※本イベントレポートの内容は2023年12月当時のものです。
TROCCO®の利用や接続オプション等の利用の詳細について知りたい方は
primeNumberまでお問い合わせください。
▶TROCCO®について問い合わせをする
登壇者紹介
甲谷 優 氏
AWSでRedshiftの日本市場における事業開発マネージャーを担当。
日系通信キャリアでデータマイニング、機械学習の研究者を経験。また、日系通信キャリアでシステム開発・アルゴリズムエンジニアを経験。それ以外にも、日系コンサルティングファームでデータ分析コンサルタントを経験。
薬丸 信也
株式会社primeNumberカスタマーサクセス部にてパートナー営業とエンタープライズ営業を担当。
株式会社キーエンスでコンサルティングエンジニアとして従事した後、現職株式会社primeNumberに参画し、パートナー営業・エンタープライズ営業を務める。現在は、現在は、広告・IT関連から製造・小売りまで業界を問わず、データ活用基盤の構築を支援している。
Amazon Redshiftの概要
最初に、甲谷氏にAmazon Redshiftとは何かの概要について説明していただきました。
甲谷氏:「アマゾンウェブサービス(AWS)の強みとしては、製品の品揃えが豊富という点があります。当社の分析サービスも同様に、非常に多数のデータサービスがあります。
その中でも、RedshiftのData warehousingについてご説明します。
Data warehousingは、2020年にIDCから発表されました。
このサービスには、20年前の1年間で生成されるデータ量と比較すると現在の1時間あたりに生成されるデータ量の方が多いという特徴があります。
これを踏まえ、従来型のデータ分析アーキテクチャについて説明します。」
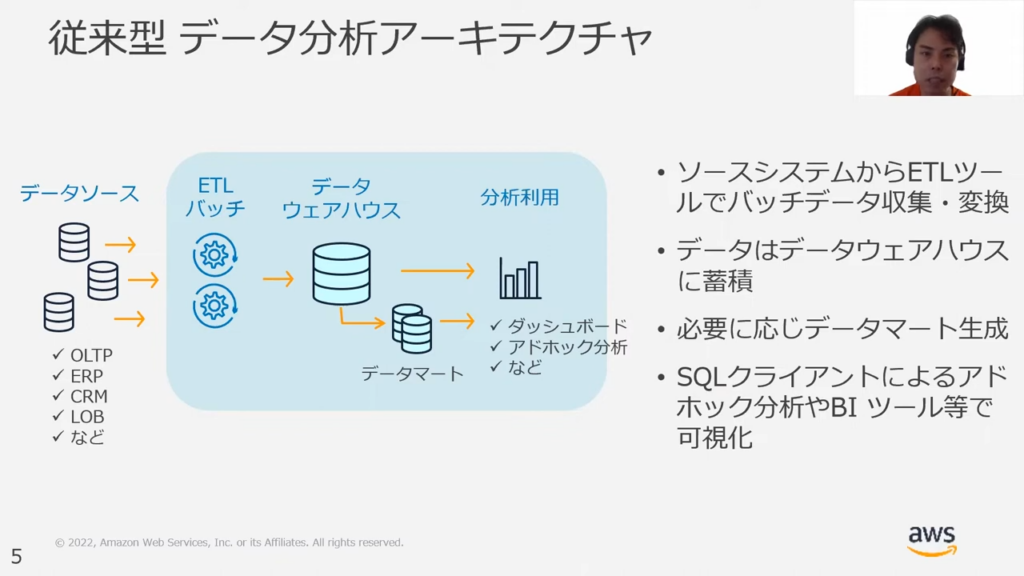
甲谷氏:「このアーキテクチャは、OLTPやERP、CRM、LOBなどの多様なソースが存在する際にETL(Extract / Transform / Load)のパッチでデータウェアハウス(DWH)にデータを一度すべて集積します。また、ケース次第ではデータマートを作成し、BIツール等のエンドの分析ツールで可視化するという仕組みになっています。」
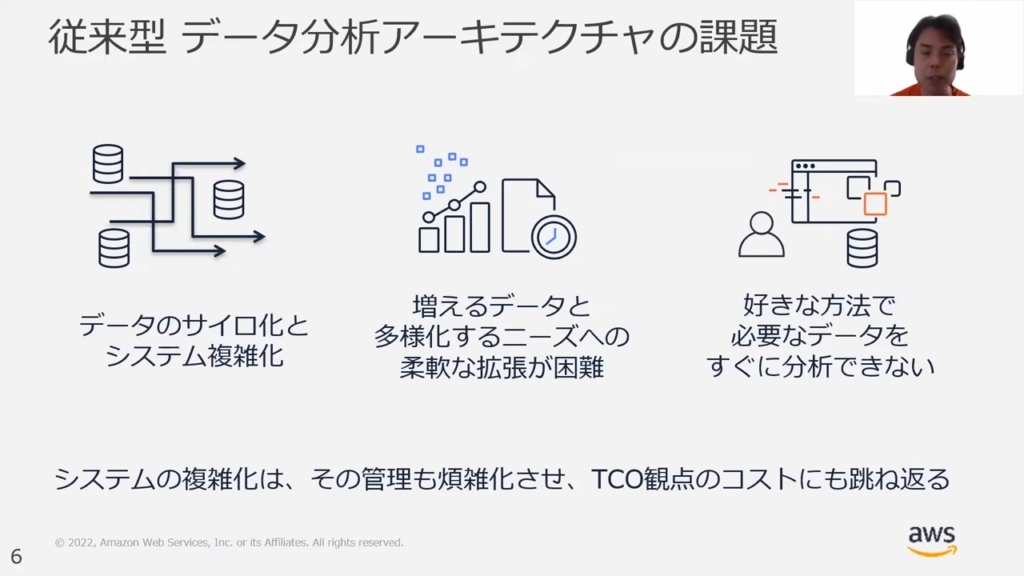
甲谷氏:「このような従来型のアーキテクチャには3点、課題が浮かび上がります。
1つ目は、従来型のアーキテクチャを採用すると、データのサイロ化およびシステムの複雑化が進んでしまうという点です。
従来型の構成を取ると、分析に必要なデータがデータウェアハウス(DWH)の中に閉じ込められてしまいます。
この場合にデータにアクセスする際は、必ずデータウェアハウス(DWH)を経由しなくてはならないため、他の分析ワークロードを導入しづらかったり、別の場所にデータを移しづらかったりといったデータのサイロ化が引き起こされます。
その結果、ロードが複雑化することにより、クラウドの数だけデータウェアハウス(DWH)ができてデータが分散するというシステムの複雑化につながります。
2つ目に、データウェアハウス(DWH)はメモリーやCPUなどの有限のリソースで構築されているため、急速に増えていくデータと多様化するニーズへの対応が困難になる点が挙げられます。
データウェアハウス(DWH)は、Excelのテーブルで表現できるような構造化されたデータを対象とした基盤のため、画像やテキストなどの構造化されていないデータやJSONのような半構造データなどの多様なデータへの対応が困難です。
それに準ずる3点目として、気軽に好きなワークロードを用いたデータ分析を行うことができない、という課題も浮かび上がります。
これら3点の課題により、管理が煩雑化する、システム拡張の際に不必要な開発を伴うなど、TCO観点でコスト高となります。」
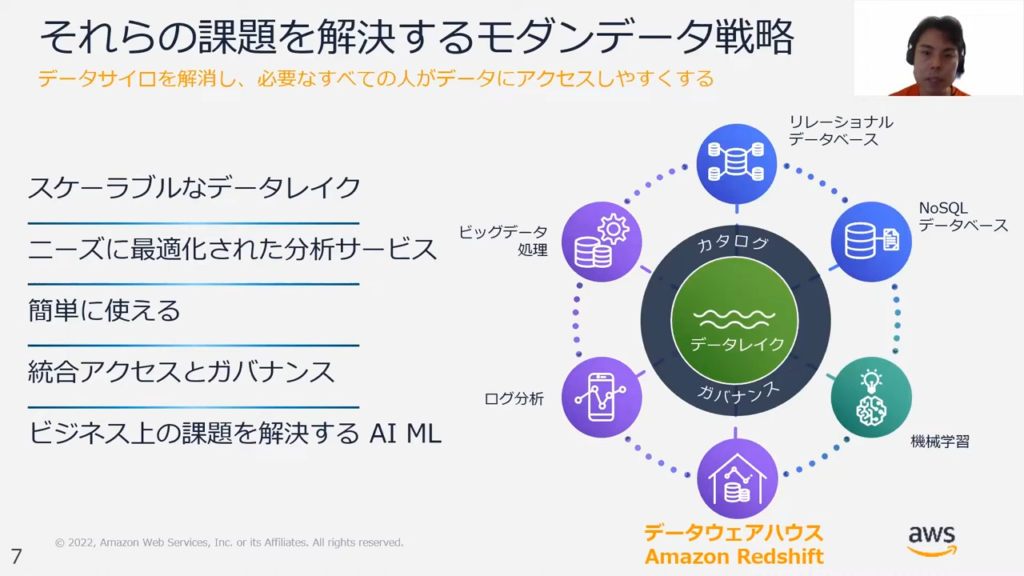
甲谷氏:「上記の課題を解決する手法として、スケーラブルなデータレイクを中心とした分析アーキテクチャである、モダンデータ戦略があります。
モダンデータ戦略は、データレイクを中心としている以外にも下記の特徴があります。
1点目に、ニーズごとに最適化された複数の分析サービスを使い分けられることです。
たとえば、
- OLTPのワークロードが必要であれば、リレーショナルデータベースを入れる
- ログ分析が必要であれば、オープンサーチなどのサービスを入れる
- 機械学習を用いる場合にも適切な基板を入れる
というような使い分けをされるお客様が増えつつあります。
また、それらのデータサービスが簡単に使えるというメリットもあります。
2点目に、データカタログやアクセスコントローラー、データガバナンスなどの複数の機能が一点に集約されて統一されていることが挙げられます。
3点目に、AIのMLOpsにおいてデータ活用をしてビジネス上の課題解決につながるという箇所が挙げられます。」

甲谷氏:「この際にRedshiftは3つの特徴を持っているデータウェアハウス(DWH)になります。
1つ目は、Easy analytics for everyoneという、誰でも簡単に分析ができるという点です。
これはインフラストラクチャーを気にすることなく、データからインサイトを提供できるということです。
2つ目は、Analyze all your dataという、データウェアハウス(DWH)内のデータに限らず、RDSやAuroraなどの運用データベースデータや、データレイクのデータについてもシームレスにデータ分析ができ、リアルタイムの予測分析を実行するインサイトを取得できるという点です。
3つ目は、Best price performance at any scalrという、コストパフォーマンスの高さを提供しているという点です。
これは、データウェアハウス(DWH)としてのパフォーマンスを最大化し、コストは低くなるべくサービスを提供しています。」
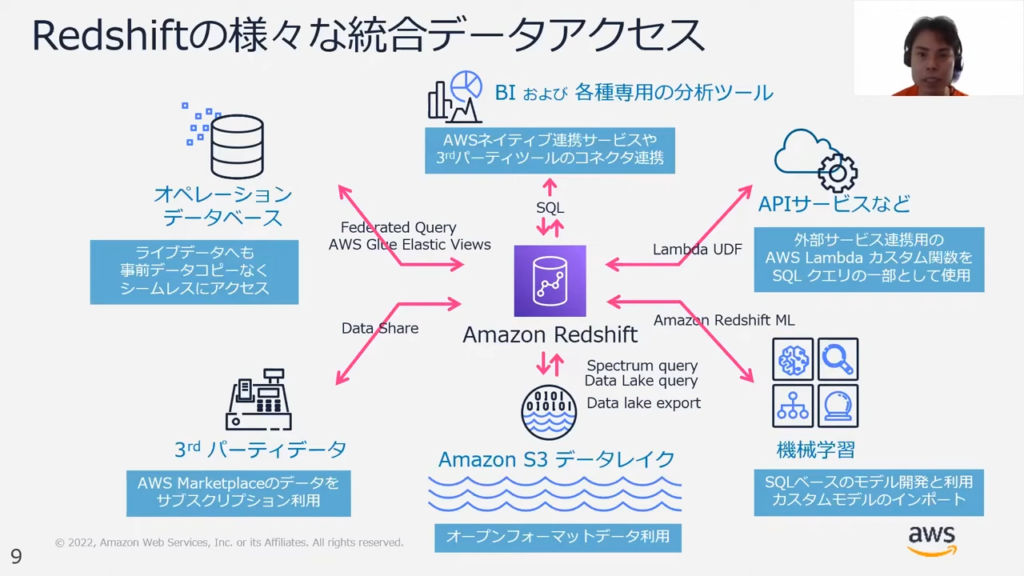
甲谷氏:「RedshiftではAnalyze all your dataで前述した通り、非常に多様な統合データアクセスが可能になっています。
これは、APIサービスと連携が可能であったり、BIツールとの連携が可能であることや、機械学習でもSQLだけで機械学習モデルのトレーニングや推論を行えるようになっているということです。もちろん、3rdパーティのデータも活用できます。」
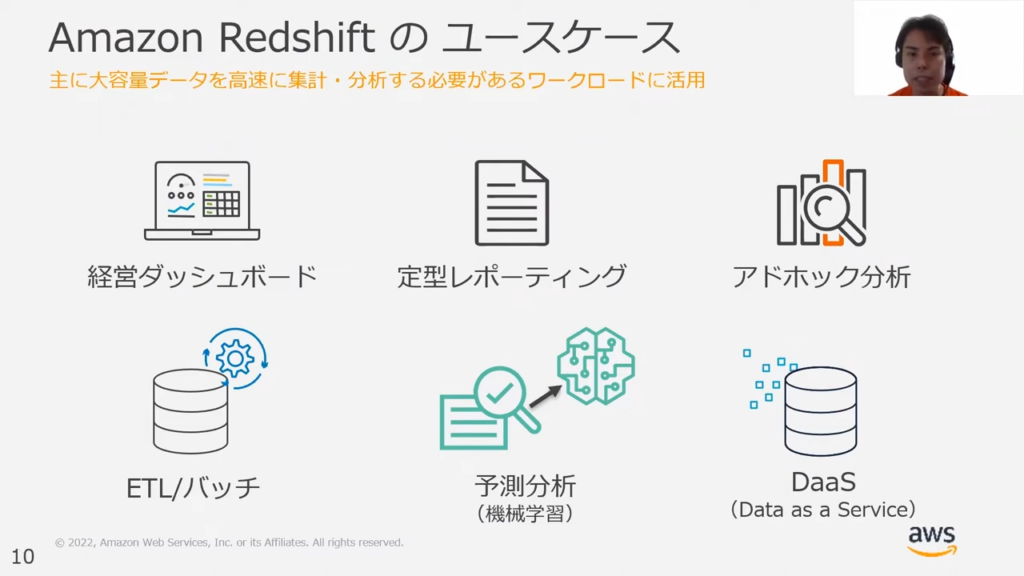
甲谷氏:「Redshiftの典型的なユースケースとしては、BIツールでダッシュボードを作る際に活用していただけます。また、定型レポーティングをする際に、データをサマリーしテーブル形にまとめることもできます。
アドホック分析では、たとえば、経営会議に必要なデータをクエリを打って分析するという使い方もできます。ETLやバッチ処理にも利用可能です。
昨今ではRedshift MLが機械学習に対応しているため、予測分析も可能ですし、アプリケーションのバックエンドとしてDaaSを用いることもできます。」
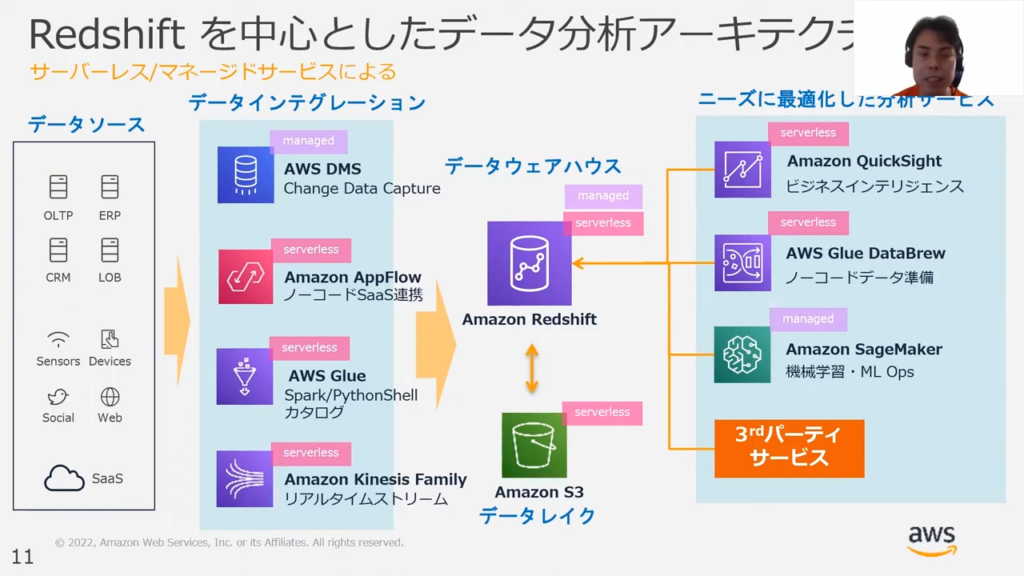
甲谷氏:「先ほどのモダンデータ戦略を踏まえ、Redshiftを中心としたデータ分析のアーキテクチャ例について説明します。
データソースとデータインテグレーションに関しては非常に多くの選択肢があり、幅広い外部サービスに対応しています。
primeNumberのTROCCO®は、このデータインテグレーションを実現してくれるツールです。
大きなポイントとしては、データレイクとデータウェアハウス(DWH)が連携している点が挙げられます。
データレイクを設けることにより、データレイク側で新規のワークロードを簡単に追加することが可能です。もちろん、SQLを実行するための基盤としてデータウェアハウス(DWH)を用いることも可能です。
分析サービスについては、ニーズごとに最適化したサービスを用いることが可能です。
たとえば、Amazon QuickSightというサーバーレス型のBIツールや、AWS Glue DataBrewというノーコードでデータの準備をできるツールもあります。
また、MLOpsを実現するた目のAmazon SageMakerがあり、Redshiftのデータからサードパーティサービスからトークをつないで他のデータサービスと連携することも可能です。」
Redshiftの活用事例
甲谷氏:「毎日、何万ものお客様がRedshiftでエクサバイトの膨大なデータを処理しています。その中の代表的な事例について説明します。」
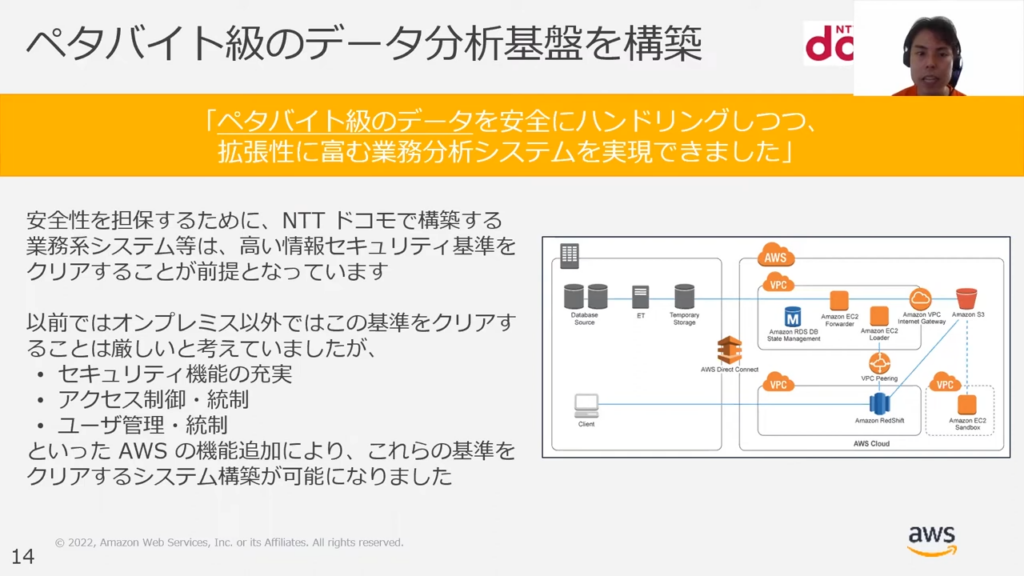
甲谷氏:「NTTドコモ様では、ペタバイト級のデータをRedshiftを用いて分析しています。
Redshiftを採用した一番の決め手としては、NTTドコモさんの厳しいセキュリティ基準をRedshiftが適合できたことです。
セキュリティ機能やアクセスコントロール機能、ユーザー管理に関するデータの抽出機能においてもRedshiftは定評があります。」

甲谷氏:「ANA様の事例としては、もともとオンプレミスでデータウェアハウス(DWH)を運用されていましたが、新しい分析技術を試したいというご要望からクラウドに移行しています。
Redshiftに移行した結果、新しい分析技術を試せるようになったほか、パフォーマンスの向上や運用負荷が軽減しました。
Amazon.comのECサイトでは、100ペタバイト超の大容量のデータを扱っており、1日の分析ジョブも60万となっています。
もともとはOracleで構築されたデータウェアハウス(DWH)を使われていましたが、S3データレイクとRedshift、Redshift Spectrumというモダンなデータサービスに移行したことにより、コスト削減が可能となりました。」
Redshiftを構築する際にパートナーが必要であれば、サービスデリバリープログラム認定パートナーもご検討ください。」
Redshiftのアーキテクチャの特徴
甲谷氏:「次に、Redshiftのアーキテクチャの特徴について説明します。」
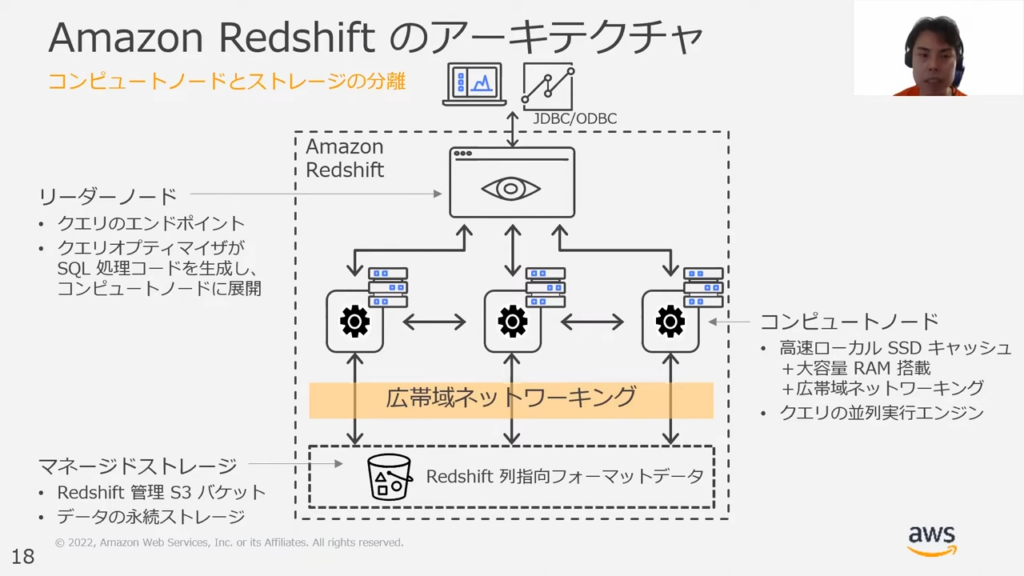
甲谷氏:「大きなポイントとして1つ目に、コンピュートとストレージが分離しています。
これは、Redshiftの中にデータベースやエンドポイントに、複数のコンピュートノードか並列に配置されているということです。
このコンピュートノードが並列で処理を実行することによって、多量のデータを高速に分析できます。
またパフォーマンス改善のため、コンピュートノード側に高速でアクセスできるSSDキャッシュを持っております。」
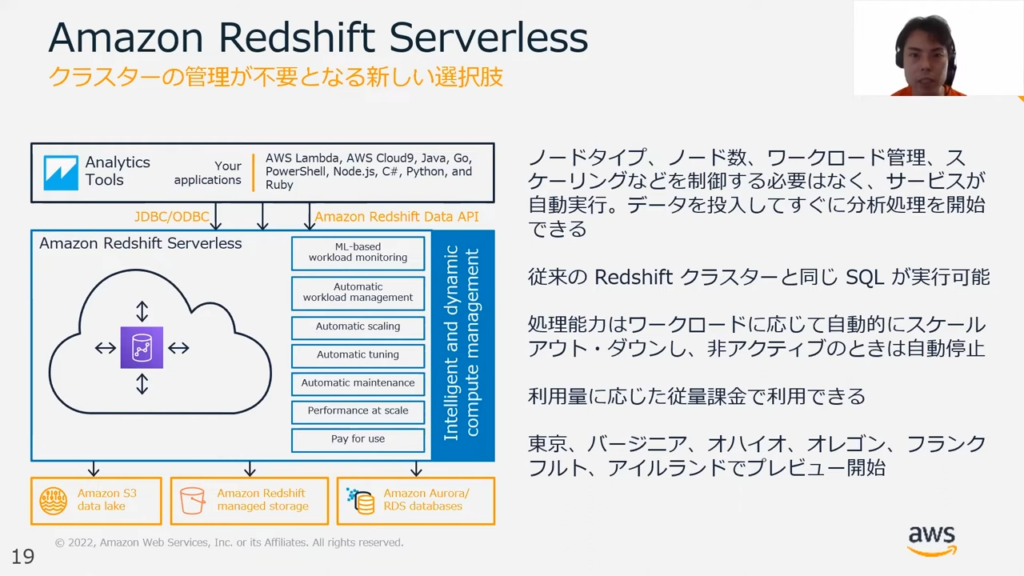
甲谷氏:「最近では、Redshift Serverlessというモデルを提供検討中であり、東京リージョンにてプレビューでお試しいただける状況となっています。
Redshift Serverlessでは従来のRedshiftと異なる箇所として、分析開始の前に性能検証を行ってノードタイプやノード数などを決めるという工程が必要なくなっています。
ノードタイプやノード数は、実行されるクエリによって自動で決定されますが、従来のRedshiftでは運用中のデータ増加に伴いノードを冷却する時間が必要となります。
その際に、ノードの変数を増やす以外にもモニタリングが必要になります。
しかしRedshift Serverlessでは前述のように自動で割り当てられ、モニタリングの必要がないため運用負担が削減できます。
また、Redshiftで実行されるクエリが1日のごく一部の時間しかない場合などに最適ですが、システムがアクティブのときにだけ従量課金がされることも大きなポイントです。」
Redshiftの高いセキュリティ管理機能
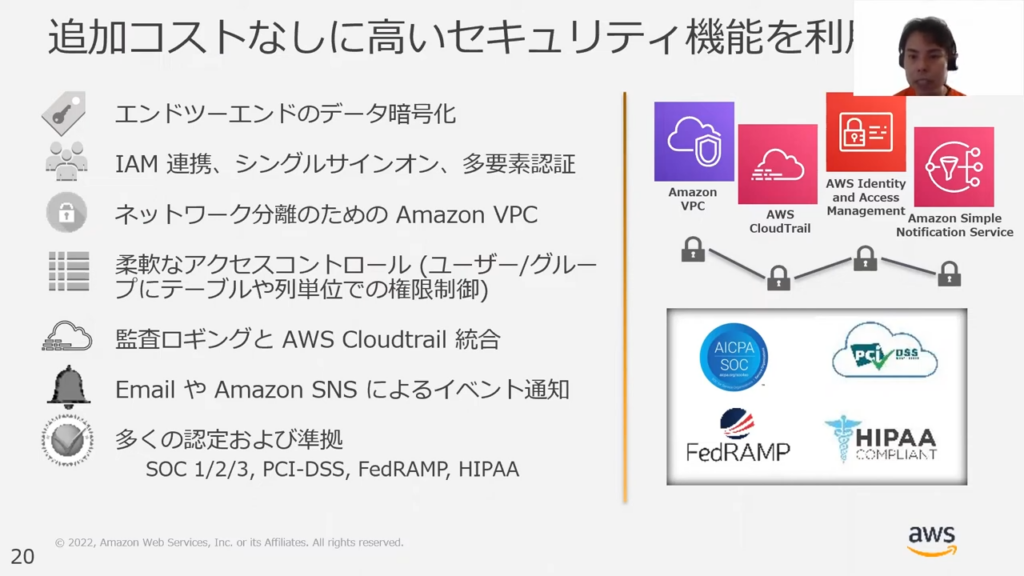
甲谷氏:「セキュリティ周りにおけるRedshiftの売りポイントとしては、HIPAAやFedRAMPなどのコンプライアンスの認証を受けているため、非常に高いセキュリティが担保されているということです。
他にもセキュリティ管理の多数の機能をデフォルトでコンピュートインしており、データの暗号化機能を無料でお使いいただけます。
また、IAM連携機能やシングルサインオン機能をサポートしています。
それ以外にも、Amazon VPCを用いたネットワーク分離も可能ですし、アクセスコントロール機能や監査ロギング機能などがデフォルトで利用可能です。」
PrivateLinkを利用したクロスVPCサポート
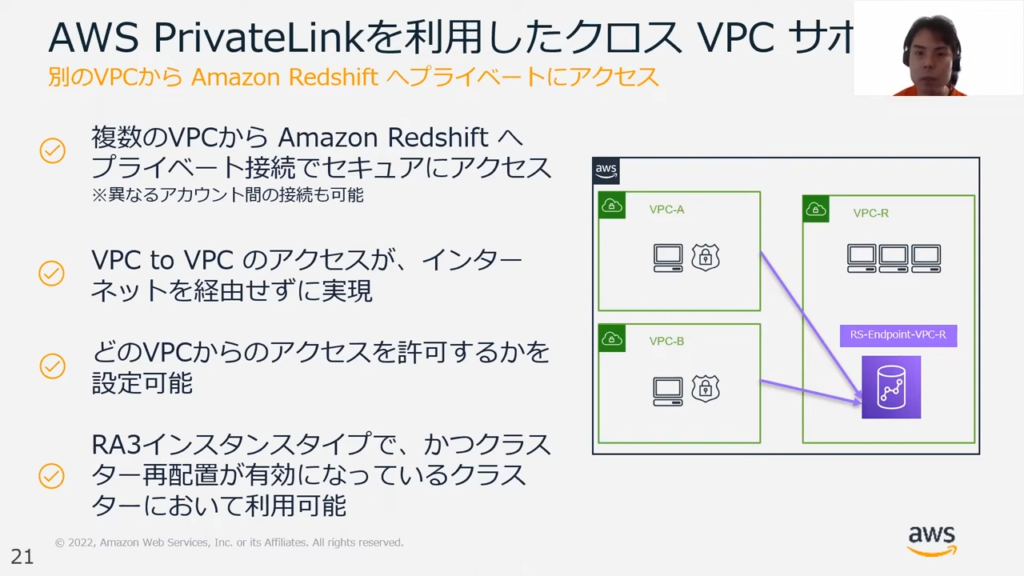
甲谷氏:「Redshiftに最近追加された機能として、PrivateLinkを利用したクロスVPCサポートがあります。
RedshiftをVPC内に構築した際に、通常はVPC内のサーバーからネットワーク接続ができなくなります。しかし、他のVPCに対してこのPrivateLink機能を利用することで、エンドポイントを設けることができ、セキュアなアクセスが可能です。」
query editorについて
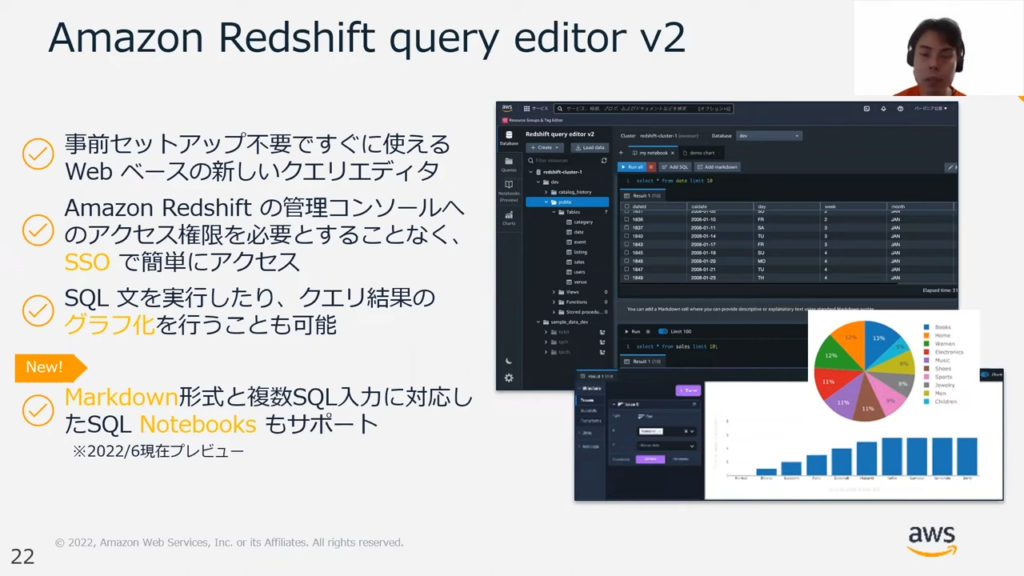
甲谷氏:「Easy analytics for everyoneの観点で言いますと、Redshift query editorが挙げられます。
マネジメントコンソールにログインすると、このクエリエディタを開くことができます。これは、単にクエリ実行が可能なだけではなく、実行したクエリを保存してチーム間で共有することも可能です。
実行結果のテーブルを保存し共有することも可能ですし、無償で簡易的な円グラフや棒グラフを作成しデータの可視化および保存も可能です。」
Redshift Spectrum
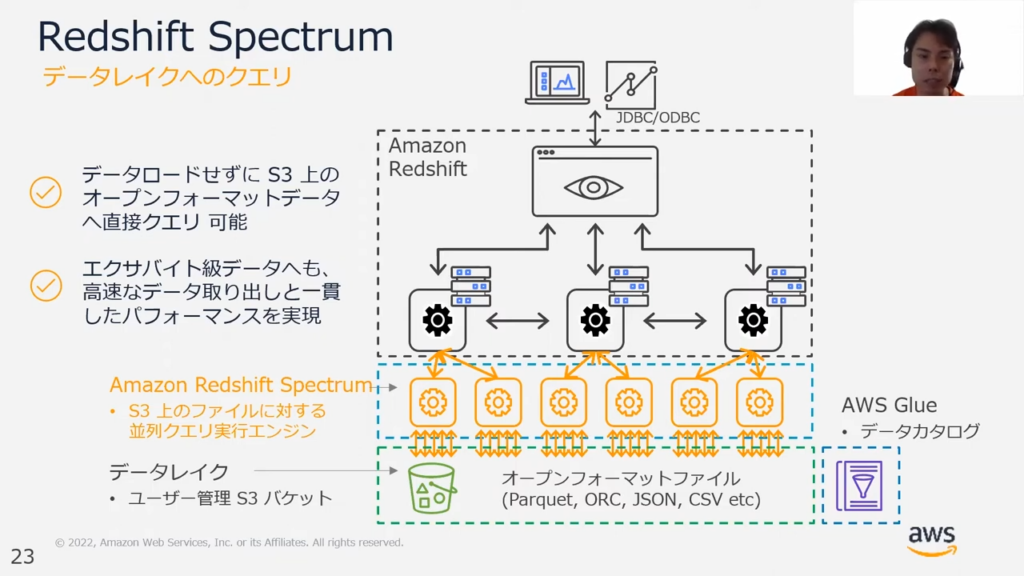
甲谷氏:「Analyze all your dataの観点に基づく機能では、前述したRedshift Spectrumが挙げられます。
こちらは先ほどお見せしたRedshiftのアーキテクチャに類似した仕組みですが、S3のデータレイク内にあるバケットに存在するファイルに直接アクセスするという違いがあります。
こちらのファイルはPurquet、ORC、JSONなどの多くのフォーマットをサポートしています。
これらのファイルがAWS Glueを用いたデータレイク化をしておくことにより、スムーズにアクセスできます。
このサービスにおいては、大きなポイントが2点あります。
1点目としては、Redshift本体ではなくSpectrumという固有のエンジンからアクセスするためより高いパフォーマンスが期待できるという点です。
2点目としては、S3内のデータとRedshift内のデータをシームレスに連携できるという点が挙げられます。」
フェデレーテッドクエリ
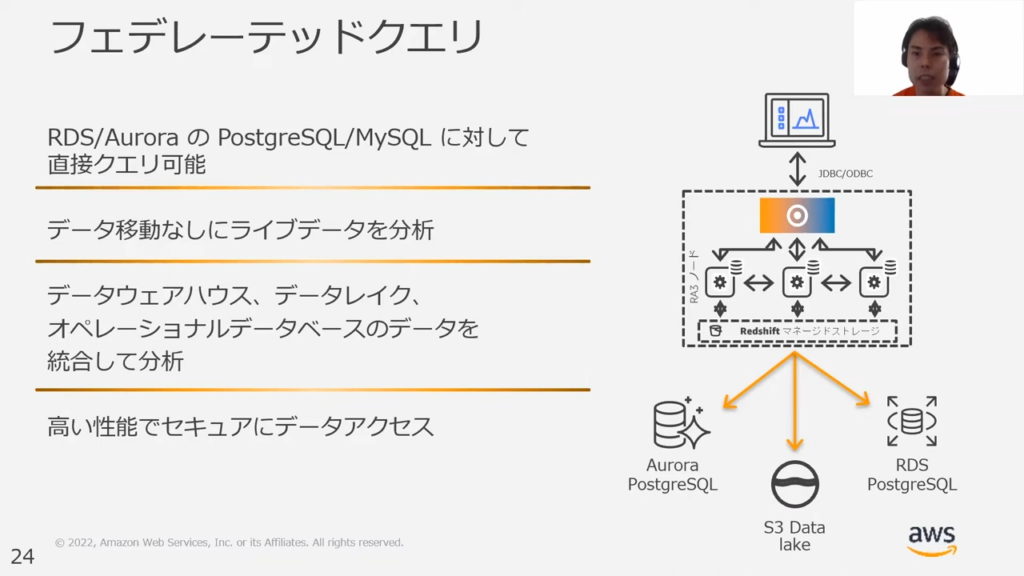
甲谷氏:「現状、RedshiftはRDS/AuroraのPostgreSQL/MySQLに対して直接クエリの実行が可能ですが、フェデレーテッド機能を用いることでSQLのみでデータの移動が可能です。」
Redshift Data Sharing
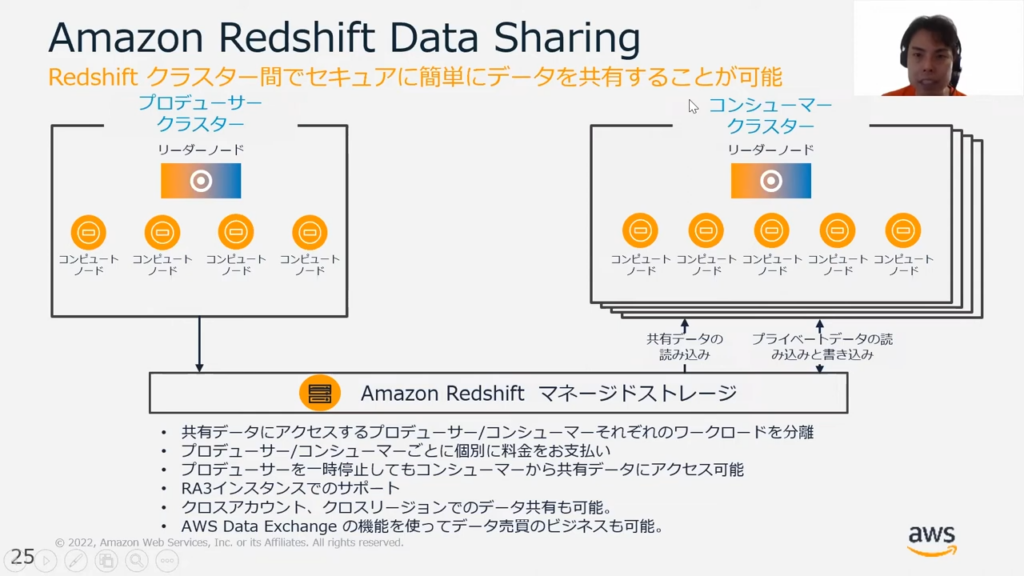
甲谷氏:「Redshift Data Sharing機能についても説明させてください。
この機能は、Redshiftのクラスター間で同一のデータを共有できる点においてはフェデレーテッドクエリと似た機能ですが、相違点があります。
データを共有するガードクラスターはプロデューサークラスターと呼ばれ、データをロードするクラスターをコンシューマークラスターといいます。Redshiftは前述の通りコンピュートとストレージが完全に分離しているため、プロデューサークラスターのコンピュートを使わずに読むことができます。
これにより、複数のクラスター間で同一のデータを参照しつつも、ワークロードの完全な分離が可能です。
たとえば、ETLを実行するクラスターと BI ツールに接続するクラスターがある場合。
その2つのクラスター間でデータ共有をする際に、従来であれば同一クラスターで BIツールとETLを同時に動かすとETLの実行中BIツールのパフォーマンスが低下します。しかし、Redshift Data Sharingであれば互いのパフォーマンスを落とさずに作業が可能です。
このクラスターはクロスアカウント、クロスリージョンでも適用可能です。」
TROCCO®の概要
ここからは、株式会社primeNumberの薬丸より、TROCCO®の概要、TROCCO®の機能、TROCCO®とRedshiftの親和性について説明しました。
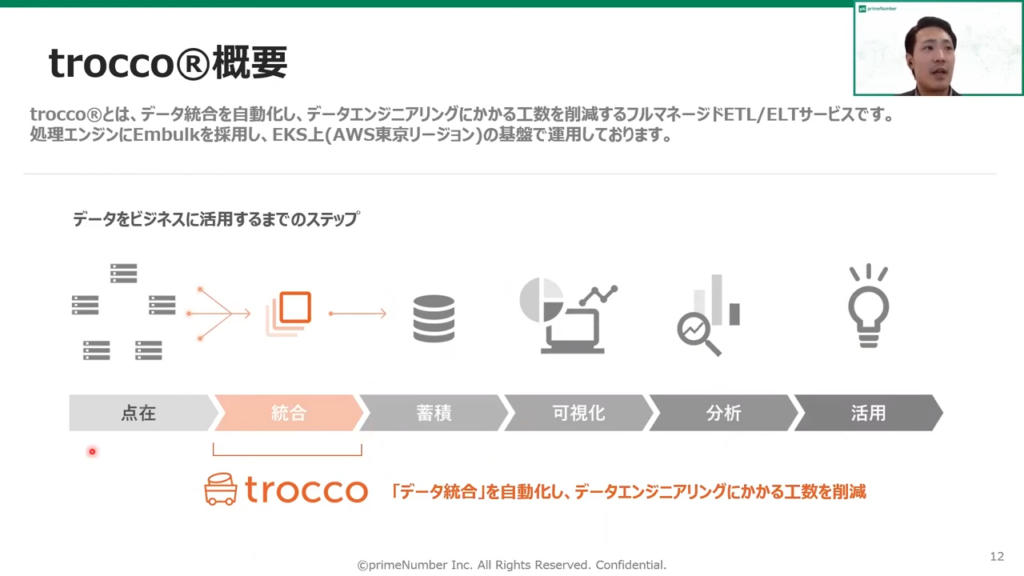
薬丸:「TROCCO®は、データ統合の自動化によりデータエンジニアリングにかかる工数を削減するフルマネージドETL/ELTサービスです。
処理エンジンにはEmbulkを採用しており、EKS上の基盤で運用しています。
先ほどご説明のあったRedshiftで、点在しているあらゆるデータを統合することが役割です。そしてデータが蓄積された上で、可視化および分析されることでデータの活用につながります。」
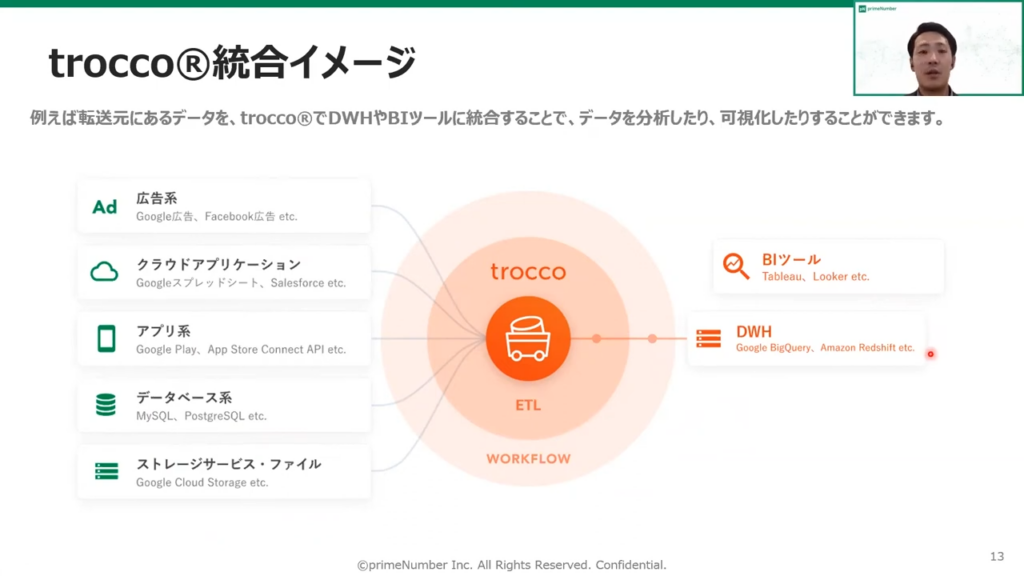
薬丸:「TROCCO®の統合イメージについてもお話しします。
たとえば広告系クラウドアプリケーション系、アプリ系やデータベース系などからデータを抽出、加工の過程を経てデータウェアハウス(DWH)に統合していくことによりデータの分析・可視化が可能になります。」
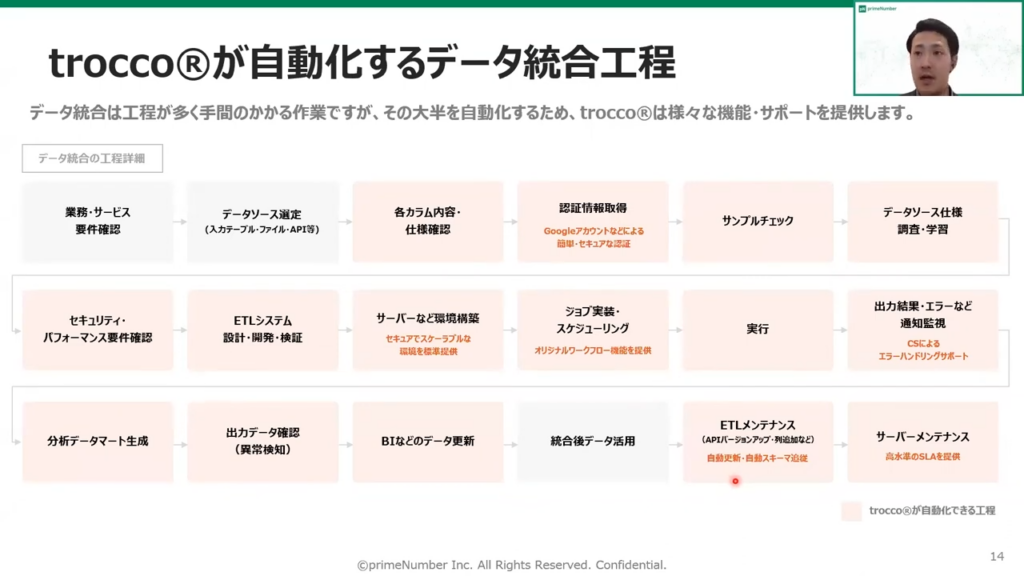
薬丸:「データ統合には大別して構築と運用、保守があります。たとえば構築の部分ではTROCCO®を使っていただくことで、個別のETLプラインを作る必要がない、個別のサーバーを構築する手間が省ける、といったメリットがあります。
そのほかにも、運用においては弊社のCSチームによってエラーハンドリングのサポート等を提供しています。
また、保守においても、たとえばコネクタのAPIのバージョンアップの対応は弊社で行っております。
それ以外にも、自動追従機能により、テーブルへの追加なども弊社で対応可能です。
このように、多くの工程を自動化することでデータ統合にかかる工数の9割を削減することが、TROCCO®の大きなコンセプトとなっています。
TROCCO®は現在、業種・業界問わずにPOCを含めて200社以上のお客様へご採用いただいております。
その中では情報システム部門の方はもちろんですが、人材採用の方にもご利用いただいております。」
TROCCO®の豊富な機能について
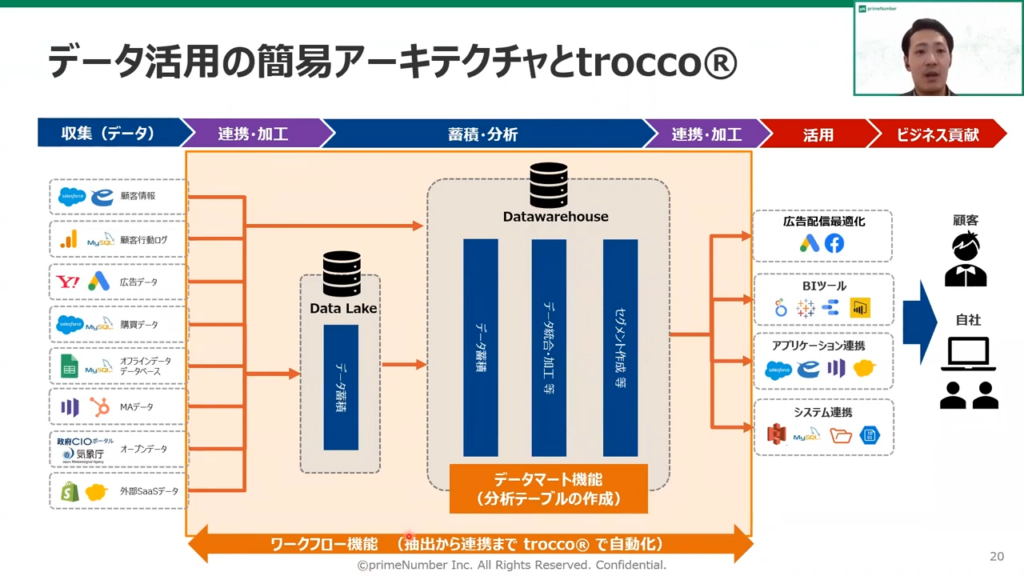
薬丸:「データパイプラインの中では、TROCCO®がお役にたてる機能として大きく3つあります。」
1つ目に、各データソースから、データをデータレイクもしくはデータウェアハウス(DWH)に転送する機能です。
2つ目は、データウェアハウス(DWH)の中で分析用のテーブルを作成する、TROCCO®の中ではデータマートと呼ばれる機能です。
3つ目に、データを抽出して分析用のテーブルを作成し、別のプラットフォームと連携していく一連の流れを1つのワークフローとして管理する ワークフロー機能です。
この一連のパイプラインを、TROCCO®に集約して管理することも可能です。
TROCCO®はエンジニアの工数を削減することを目的としており、非常に分かりやすいUIを実装することで学習コストの削減を図っています。」
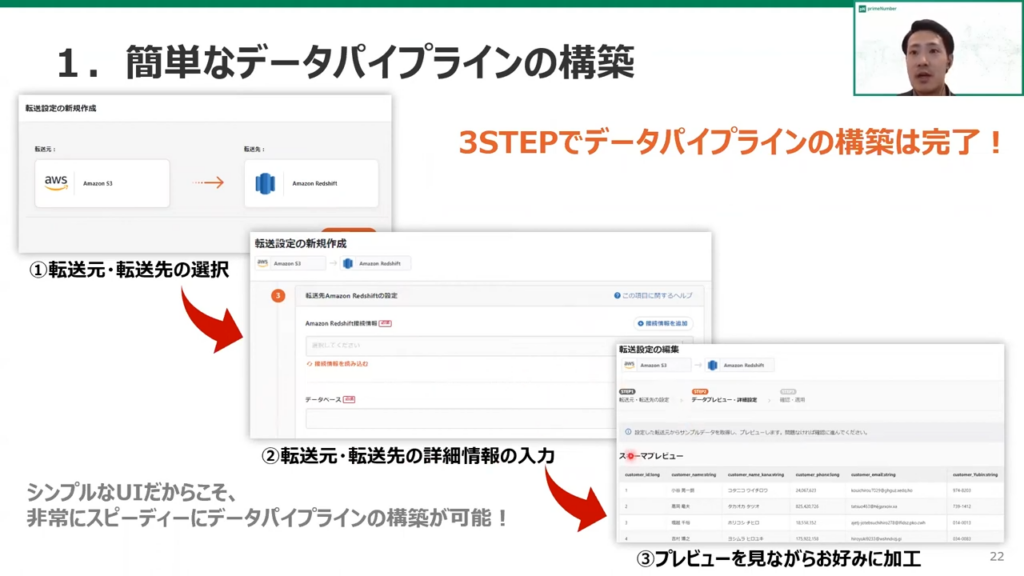
薬丸:「実際に、データパイプラインの設定をする場合、3ステップですべてのパイプラインが構築できます。
具体的には、まず転送元と喧騒先のサービスを選びます。続いて、それぞれの接続の情報やテーブルの情報を入力し、最後にプレビュー画面を見ながら加工の結果を確認、保存するのみです。」
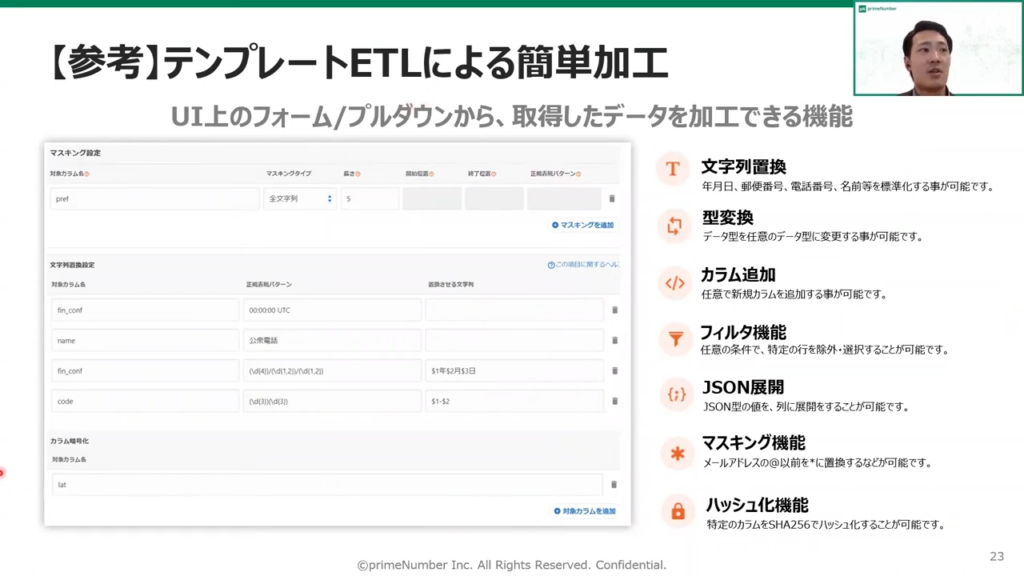
薬丸:「また、テンプレートETLという、UI上のフォーム/プルダウンから取得したデータを加工できる機能もあります。
具体的な例で申し上げますと、文字列から郵便番号のハイフンを削除して郵便番号を7桁の数字として扱う、カラムの追加によりデータ送信の際にタイムスタンプを付与するというような使い方をします。」
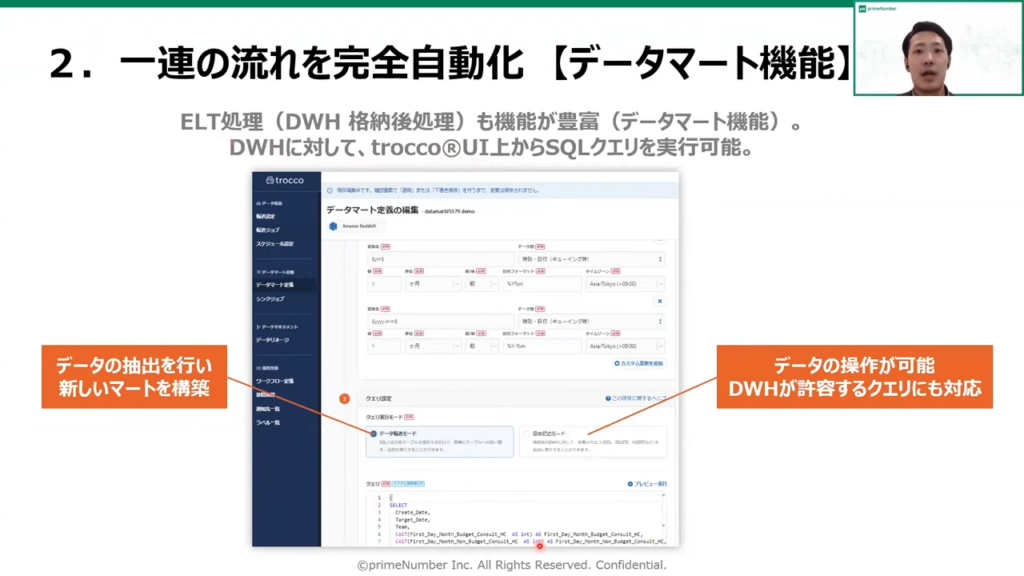
薬丸:「データマート機能は、ELT処理すなわちデータウェアハウス(DWH)格納庫の処理についても、機能が豊富に実装されています。
データウェアハウス(DWH)に対して、TROCCO®のUI上からもSQLのクエリを実行できます。
TROCCO®には大別して2つのモードがあります。
1つ目はデータ転送モードという、データの抽出をすることにより新しいデータマートを構築するモードです。
2つ目は自由記述モードという、DDL文のようなデータの操作が可能です。また、データウェアハウス(DWH)で利用ができるクエリの実行が可能です。」
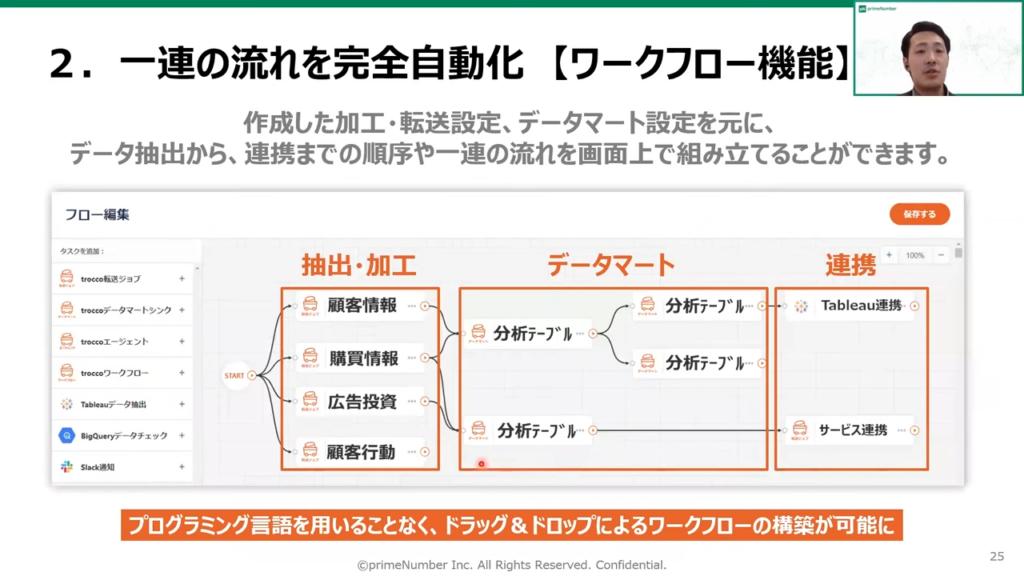
薬丸:「そして、先ほど作った転送の設定およびデータマートをGUIで並べることにより、一連のワークフロー作成が可能です。
このワークフロー機能は、ジョブの並列実行というアプリに対応しており、TROCCO®の画面上から設定が可能です。」
また、TROCCO®は現在約100種類のコネクタをご用意しています。
たとえば、
- 広告系サービス
- アプリケーション系サービス
- データウェアハウス(DWH)
- ファイルストレージ
- データベース型
以上のように広く対応しています。」
Amazon RedshiftとTROCCO®の親和性
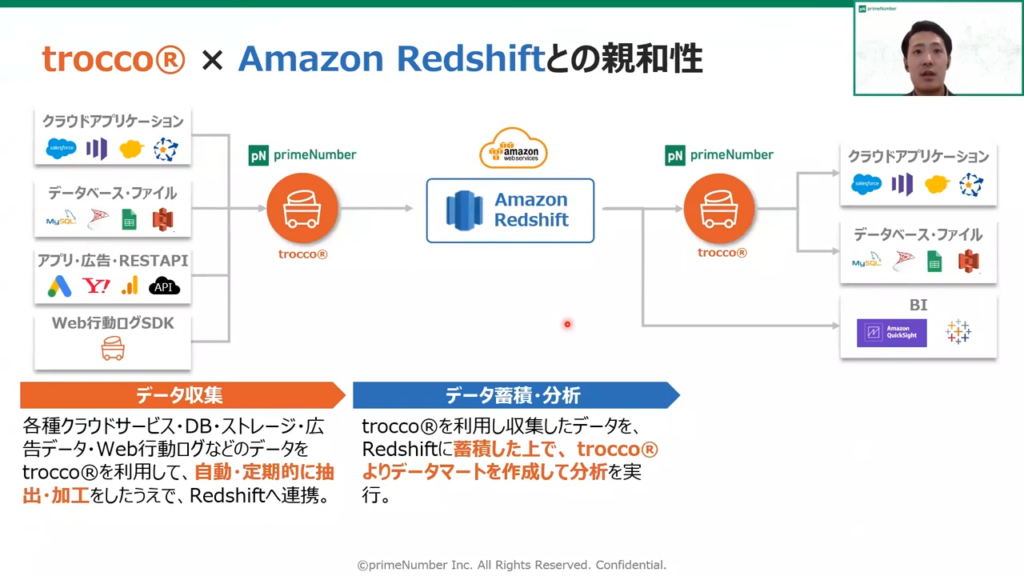
薬丸:「TROCCO®は各種クラウドサービスやデータベース系、ストレージ系、Web行動ログ等のデータを利用して、自動的かつ定期的に抽出・加工した上でRedshiftに連携可能です。
その後、TROCCO®に収集したデータをデータマート機能を用いて分析のテーブルを作成し、データ分析が可能です。
最終的には、Amazon Redshiftへの分析結果を、TROCCO®の利用により自動的かつ定期的に外部サービス連携・可視化が可能です。」

薬丸:「TROCCO®とAmazon Redshiftの親和性には、大別して4点の特徴があります。
1点目は、外部サービスとのデータ連携が容易ということです。
これにより、スピーディなデータ分析基盤の立ち上げが可能となります。また、新しいデータパイプラインの構築も、非常に簡単になります。
2点目は、分析基盤の構築と運用を少しの工数で大幅に削減できることです。
保守やメンテナンス、データソースの更新やAPIの更新は弊社のエンジニアが日々対応しているため、トータルの構築運用保守の工数が削減されます。
3点目は、Web行動力の収集ができることです。
この特徴により、Web行動ログと売り上げ等の各種データを突合した分析が可能です。
4点目に、セキュアな接続ができることです。
よりセキュアな接続として、お客様のAWS環境とのプライベートリンクが提供できます。」
Amazon RedshiftとTROCCO®を組み合わせたセキュアなデータ基盤の構築方法について
詳しく知りたい方は、primeNumberまでお問い合わせください。
▶セキュアなデータ基盤の構築方法について問い合わせる
TROCCO®の活用イメージ
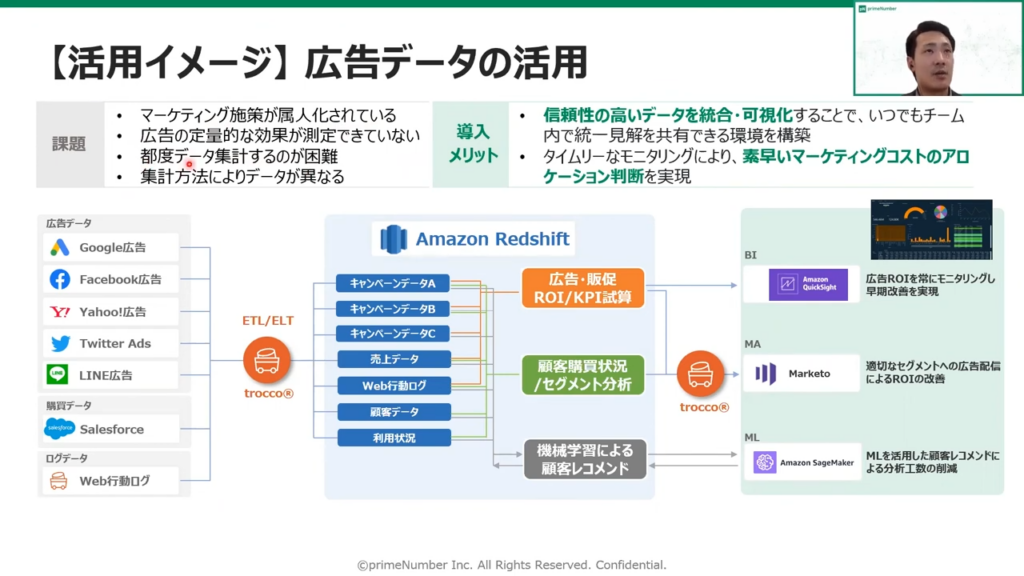
薬丸:「例として、広告データの活用のケースをご紹介します。
広告データの活用の課題としては、以下のようなことが考えられます。
- マーケティング施策の属人化
- 広告の定量的な効果測定ができていない
- データ集計に時間がかかる
- 集計方法によりデータが異なる など
これらに対し、TROCCO®とRedshiftを組み合わせたデータ分析基盤を構築すれば、以下のようなことが可能となります。
- 信頼性の高いデータを常に統合・可視化する
- チーム内で統一したデータを確認するところも構築可能
- タイムリーなモニタリングが可能
- 素早いマーケティングコストのアロケーション判断ができる
具体的には、Google広告やFacebook広告などの広告データをTROCCO®を経由し、Redshiftに転送します。
また、購買データや顧客データについては、SalesforceなどのSaaS系のサービスからTROCCO®を経由してデータを連携します。
それ以外にも、Web 行動ログを連携することで、キャンペーンデータと売上データ、そしてWeb行動ログを突合し、広告・販促のROIやKPIとできます。
また、機械学習によるレコメンドを通じて、人手による分析工数の削減が可能になります。」
TROCCO®の充実したサポート
薬丸:「我々はTROCCO®のトライアルからお申し込みまで、さまざまなサポートを提供しております。
具体的には、無償のトライアル期間が2週間あり、このトライアルではSlackチャンネルや、オンライン設定サポートも提供しています。
有償契約に移行した場合でも、定期的なオンラインミーティングを通じてお客様のデータ活用の自走をサポートいたします。
サポートの充実さに関してはお客様から反響をいただいており、問題解決や期間の大幅な短縮に貢献しております。」
まとめ
この記事では2022年6月に行われた「AmzonRedshift×TROCCO®でセキュアなデータ分析基盤構築」と題したセミナーの要点と、Amazon Redshiftを用いたデータ分析基盤構築のメリット、手法について深く掘り下げました。
特に、データ分析を始めたい方や、データウェアハウス(DWH)の導入を検討している方にとって、Amazon RedshiftとTROCCO®を組み合わせることで、どのようにセキュアで効率的なデータ分析環境を構築できるのかがお分かりいただけたのではないでしょうか。
データを有効活用しビジネス価値を最大化するためには、適切なデータ分析基盤が不可欠です。Amazon Redshiftはその強力な選択肢のひとつといえます。
また、TROCCO®との組み合わせることで、さらに効率的でセキュアな環境が実現可能となるでしょう。
TROCCO®はクレジットカード登録不要・無料のフリープランを提供しています。まずはどのようなことができるのか知りたいという方はまずはフリープランをお試しください。






