
CRM(顧客関係管理)を通じた顧客へのアプローチを用い、多くの部門がさまざまなプロジェクトでデータを活用し、顧客ロイヤリティの向上と事業成長を目指します。一方で、そのようなデータ活用の民主化は、しばしばガバナンスを維持管理する上での課題を伴います。事業のスピードを維持しつつ、データ活用をスケールさせるためには、メンテナビリティやデータ品質管理などの考慮が不可欠です。
本セッションでは、メルカリがこれらの課題をどのように技術的に解決していったか、具体的な事例に基づいてアプローチの詳細についてご紹介いただきました。
登壇者紹介
田中 克季氏
株式会社メルカリ Data Manager
2006.04~: 旧UFJ銀行 システム会社のUFJ日立システムズにシステムエンジニアとして入社。
2012.05~: 株式会社サイバーエージェントにバックエンドエンジニアとして入社。2年程度の認証基盤の開発保守担当を経て、データエンジニアに転向
2019.10~: 株式会社メルペイに入社し、データマネージャーとして現在に至る
メルカリのデータ組織・体制と、ビジネスの一部を支える「TROCCO」を活用したデータ基盤
2024年6月時点で月間利用者数が2,251万人のフリマアプリ「メルカリ」。メルカリで利用できるスマート決済サービスの「メルペイ」は月間利用者数が現在1,831万人にもおよびます。より良い顧客体験を届けるため、CRMが活用されていますが、データ管理に課題がありました。
同社のCRMにおけるデータ活用の前段として、まずは同社のデータ基盤についてご紹介いただきました。
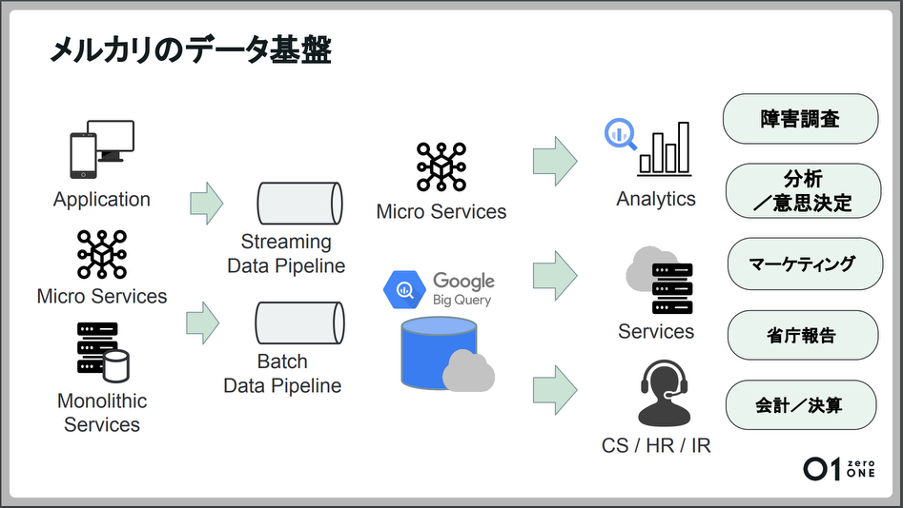
「弊社のデータ基盤でデータを収集するパイプラインは2つあります。ひとつはメルカリのアプリやサービスの機能を担う各マイクロサービスからリアルタイムにデータを収集するStreaming Data Pipeline。もうひとつが日次など一定のデータのまとまりで収集するBatch Data Pipelineです。このパイプラインが、別のマイクロサービスへのデータ連携やデータウェアハウスへのデータ集約を担っています。
データウェアハウスは主にBigQueryを使用しており、集められたデータは障害調査や分析、意思決定、マーケティング、省庁報告、会計、決算など、さまざまな用途でアナリストやマーケターなどの社内メンバーが活用できる環境になっています。
このデータ基盤の構築を担当したのが弊社のData Platformチームであり、私が所属するData Managementチームではデータを整理し、管理する役割を担っています」(田中氏)

同社のデータ基盤では、各種SaaSとデータウェアハウス(BigQuery)のデータ連携に「TROCCO」を活用いただいています。人事や財務などのプラットフォーム上で管理しているデータ、営業や顧客管理を支援するSaaS上の取引先に関するデータ、社員のプロジェクト管理の作業タスクデータなどを「TROCCO」によるパイプラインを活用してBigQueryに統合し、BIツールへ出力することで分析や可視化に役立てています。
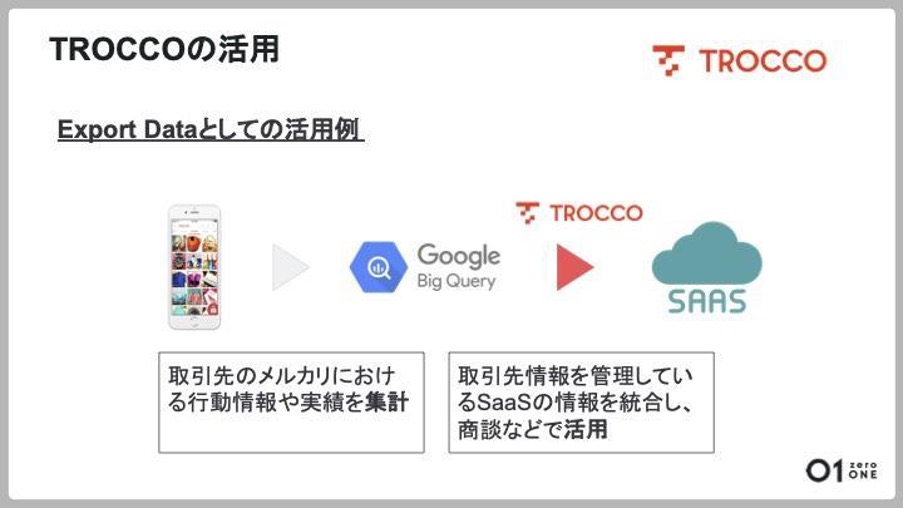
さらにメルカリ内の取引先に関する行動情報など、BigQuery上に集計されたデータを外部のSaaSに連携し、商談に活用するケースも増えているとのことです。このようにTROCCOはメルカリのビジネスの一部を支えるデータ連携に活用いただいています。
データの民主化が進んだからこそ直面した壁。データガバナンスの課題を解決し、スピード感を維持するために
エンジニアに頼らずビジネスサイド自らデータを取得し、CRMでデータを活用するメリット・デメリット
同社では、業務に活用されるデータのほぼすべてがBigQueryに集約されています。そのため、アナリストやマーケター、プロジェクトマネージャーといった非エンジニアであるビジネスメンバーでも、BigQueryのコンソールやScheduled queryを活用することで、データの参照や作成、CRMによるお客さまに向けたキャンペーンの配信などに役立てられています。
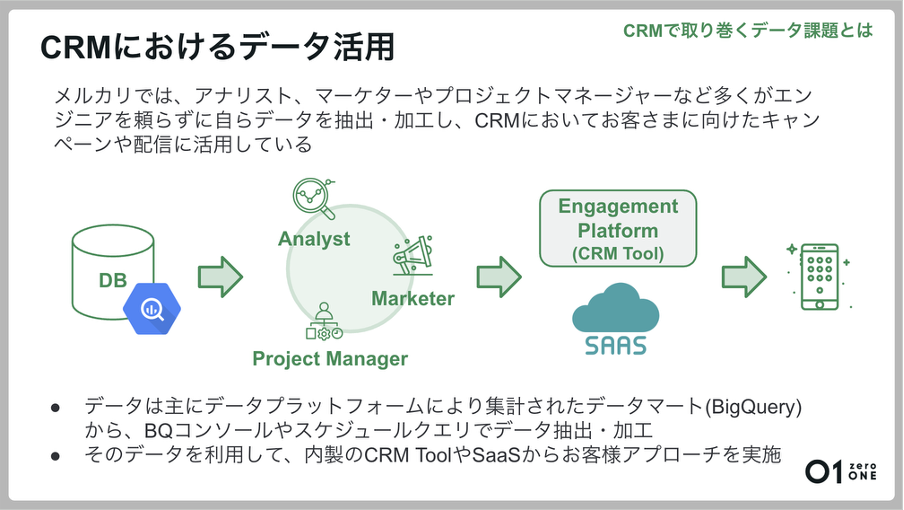
さらにBigQueryで抽出されたデータは、複数のCRMシステムを介して、さまざまなお客さまへのアプローチに役立てられています。
「弊社は比較的『データの民主化』が進んでいると思います。しかし、各プロジェクトのメンバーに裁量を委ねてデータを利活用すると、良い面だけでなく悪い面も出てきます。
まず良い面としては、プロジェクト判断でデータを活用できるため、スピード感のあるお客さま対応が可能となります。また業務要件に最も詳しいメンバーが直接データを参照するため、条件の伝達ミスなどコミュニケーションミスが発生しにくいこともメリットです。
悪い面としては、さまざまなプロジェクトでデータを自由に参照し作成するため、データ管理の統制がとりにくく、データガバナンスが行き届かなくなります。他にも、メンバーのデータ知識がそれぞれ違うため、データを作成してもデータ品質が充分に担保できないことも考えられました」(田中氏)
「データの民主化」が進んだ組織が抱える、さまざまなデータガバナンス上の課題とは
「データの民主化」が進んだ組織におけるデータガバナンス上の課題について、より具体的な例が5つ紹介されました。
① データ担当者の離職などによるクエリ実行の失敗
クエリのオーナーが切り替わっていないことで、定期的に実行するクエリの認証が切れる。そのためクエリに失敗し、データが作成できない事象が発生する。
② 類似の定義のデータが複数存在する
それぞれのプロジェクトで必要な範囲のデータを作成し参照する際に、他のプロジェクトと似たような定義のデータを抽出してしまい、知らないうちにデータの重複が発生する。冗長なデータが増えることで、データの容量やランニングコストの負担増といった問題につながることも。
③ データオーナーが分からない
データを作成した担当や関係者を記録しておらず、時間が経過すると誰がデータを管理しているのか分からなくなり、データのメンテナンスが不可能に。
④ データの利用用途が分からない
データを利用した経緯やその用途を記録しておらず、利用用途が不明になる。さらに今も利用しているか分からないため、メンテナンスが困難に。
⑤ データの品質が一定ではない
承認されたクエリやテストされたデータではない場合、データ品質を一定に保つことができず、障害が発生するリスクにつながる。
これらのデータガバナンス上の課題に対しては、社内のデータ基盤を利用することで、データ管理を統制できるかもしれません。しかし、システム関係者との調整などのコミュニケーションがボトルネックとなるため、スピード感が求められるCRMでのデータ活用には適さない状態になり得ます。さらに『データの民主化』を損なう恐れもあります。
そこでデータガバナンス上の課題を解決しつつもスピード感を維持するため、データ抽出要件からデータ作成まで、ビジネスメンバーに委ねるべきところは委ねる方針を選択されました。その上でデータガバナンスを保つべく快適なデータの集計環境と、自動化の仕組みを提供し、データ管理の統制に取り組まれました。
GitHubによるクエリ管理とBigQueryによる技術的なアプローチ。ガバナンスの課題を解決するためのデータ管理と活用
データ管理上の解決すべき6つの事項と、ユーザーであるビジネスメンバーからの3つの要求

データガバナンス上の課題に対応するため、データ管理上で解決すべき事項が以下の6つに整理されました。
- オーナー管理
- データオーナーの明記
- クエリ管理と変更管理(バージョン管理)
- どのようなクエリが登録されたか
- どのようにクエリが変更されたか
- 承認プロセス
- クエリの品質を担保するために、作成者だけではなく別の担当者によるダブルチェックを可能にする
- メタ情報管理
- データの更新頻度や保存するテーブルの形式などのメタ情報を管理し、データの詳細情報を知ることができる
- 持続可能なクエリ実行
- 個人の認証での利用を避けて退職などで継続した実行ができなくなることを防ぐ
- データの状態監視
- 作成されたデータやデータ量を監視、可視化し、データの健全性を確認できるようにする
データ管理上で解決すべき事項に加え、データの使い勝手をさらに向上するためには、ユーザーからの要求も実現する必要があります。データ利用者のほとんどがエンジニア以外のロールであるため、エンジニアスキルをできるだけ必要とせず、簡単に利用できるものである必要があります。

「まず簡易的なデータ集計を行い、データ作成に高度な専門知識は不要にすべきです。弊社ではこれまでも担当者レベルでGUIでのBigQueryのデータ抽出や、Scheduled Queryを利用したデータ作成は利用していた。そのため、馴染みのあるBigQueryのScheduled Queryをベースとした集計を構想しました。
次は直感的なクエリ管理です。クエリはGitHubリポジトリで管理するようにし、GUIでの修正や登録ができるように操作を簡易化することを検討しました。
最後は安定したクエリ実行です。弊社はBigQueryをフラットレート料金モデルで利用しています。これは、あらかじめ決められた上限内で利用できる定額制のプランです。そのため、使いすぎるとリソースが足りなくなる可能性があり、利用量を意識する必要があります。特にCRMのデータ分析をする際は本番環境を利用するため、リソース不足に陥らないように本番用Reservationで実行をできるようにしています。また、安定してクエリを実行するために、個人アカウントでのクエリ実行ではなく、サービスアカウントでの実行で実現しました」(田中氏)
クエリとデータ作成情報を管理するGitHubと、データを保管するBigQueryで構築した新しい環境
実際にどのようなシステム構成と仕組みでデータが作成されるかを解説いただきました。
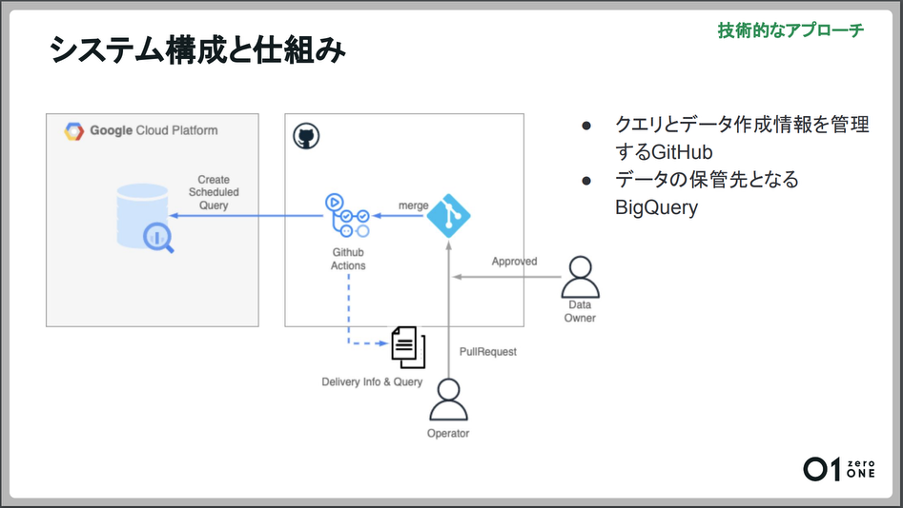
まずGitHubにPull Requestを作成し、担当者がデータ抽出するためのクエリと、データ作成情報の登録を依頼します。次に対象のクエリやデータ作成情報が問題ないか、GitHubのレビュープロセスを介して、データオーナーや業務要件が分かる別の担当などがレビューします。
レビューが承認されると、Pull Requestがマージされます。Pull Requestがマージされたタイミングで実行されるGitHubアクションにより、プッシュされた内容に従ってScheduled Queryを登録します。このようにして担当者によるクエリ登録とクエリの定期実行を一連のプロセスにしています。

GitHubにプッシュされるファイルは、クエリとデータの作成情報の2つです。クエリはScheduled Queryに登録されるデータ抽出クエリで、「.ql」のファイル形式で保存されます。
データ作成情報とは、yamlで記述されるファイルになっており、実行スケジュールやデータオーナー、出力テーブルの基盤形式などの、データを作成するためのメタ情報を記述します。
これらのファイルをGitHubリポジトリで管理するようにします。
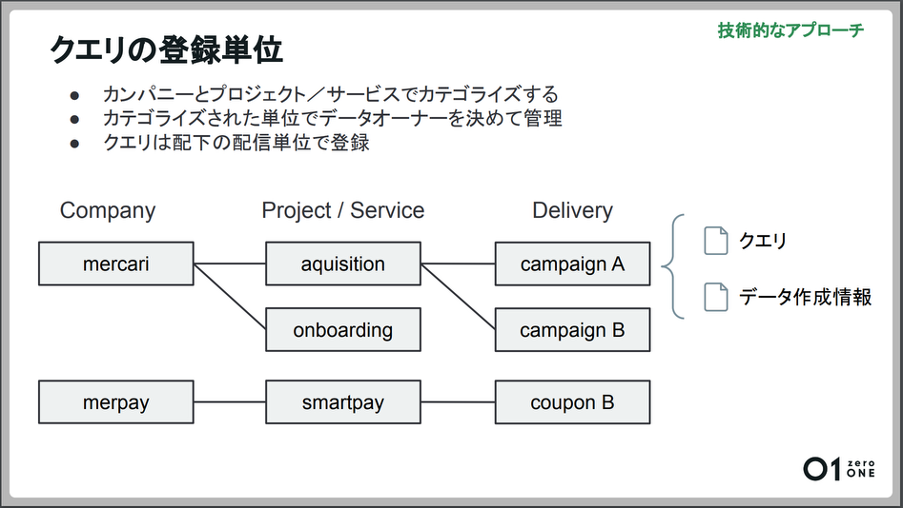
クエリは、基本的に配信やキャンペーンごとに登録しています。登録する際は検索性が良くなるように、メルカリやメルペイといったカンパニー単位に加えて、プロジェクト単位・サービス単位でもカテゴライズしています。
クエリとデータ作成情報は、その配下に配信単位で管理します。クエリごとにデータオーナーを決め、責任を持って管理するようにします。
データを作成する際に登録されるメタ情報には、以下2つの項目が設けられています。この項目を利用し、データを保存するテーブル名が決められます。
- Delivery_type:キャンペーンやクーポンなどの配信種別
- 例: campain, incident, coupon
- Delivery_name:配信を特定するための名称
その他に登録されるメタ情報は以下の通りです。ingestion_time_partitioned/partition_fieldは競合するため、どちらか一方を設定するようにします。
- schedule:データの作成スケジュールを設定。設定内容には、Scheduled Queryを登録する時の形式をそのまま記述
- description:どのキャンペーンの配信かなど、データを利用する目的などを記述
- write_disposition:データの書き込み方法。テーブルへの上書きか、データ追加かを設定
- ingestion_time_partitioned:取り組み時間をパーティションにするかしないかを設定
- partition_field:パーティションを作成する場合の対象フィールド
- owner:クエリとクエリで作成される配信データのオーナーを設定
他にも、開始・終了日時といったスケジュール実行の詳細情報も記述されています。
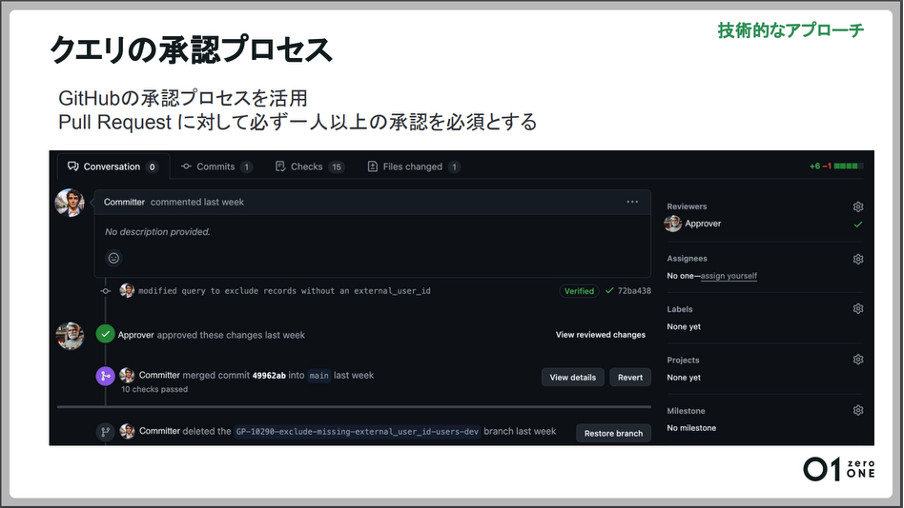
クエリの承認プロセスは、GitHubの仕組みをそのまま利用しています。Pull Requestを確認し、データの作成内容が業務要件に合っているのかチェックし、問題なければ承認します。担当者以外で少なくとも1人の承認が必要です。
GitHubに詳しくないメンバーでも利用できる「GitHub Issue Form」を社内に提供
同社のシステム構成と仕組みのご紹介を受け、「GitHubの知識がないと難しい」と感じてしまう方も多いでしょう。しかし同社にも「Pull Requestの上げ方が分からない」といったGitHubの使用に慣れていない社員も珍しくないそうです。
そうした社員でも簡単に利用できる仕組みとして、社内にGitHub Issue Form(データ作成依頼フォーム)が提供されています。
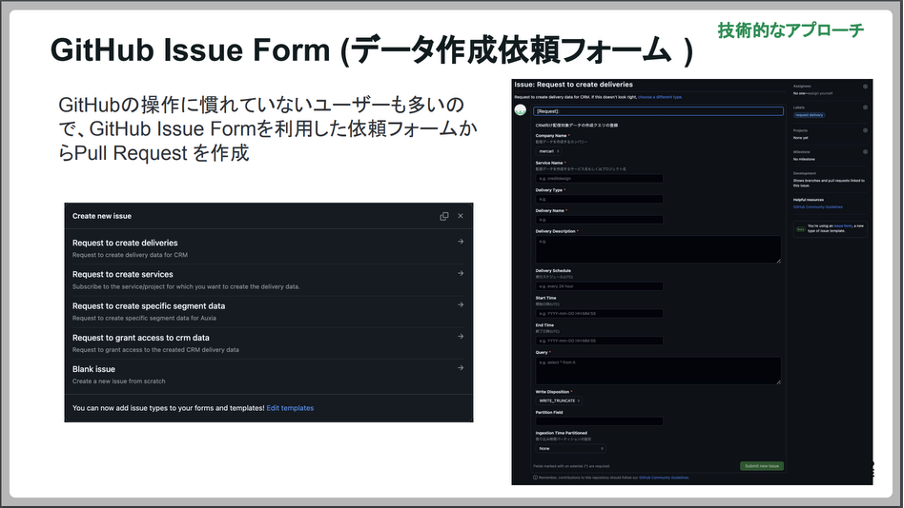
「担当者が入力フォームから必要な項目を入力して申請すると、Pull Requestを自動作成してくれる機能を提供しています。入力する項目は、データ作成情報の各項目やクエリです。GitHubのIssue Form上で簡単な入力チェックもできるため、記述漏れもある程度は防ぐことができます。」
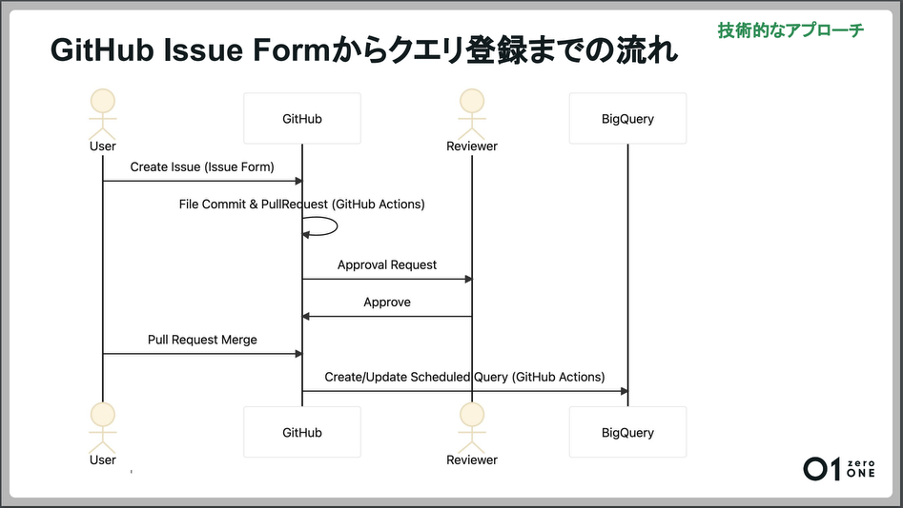
「GitHub Issue Formからクエリ登録までの流れをご紹介します。まず担当者がIssue Formに入力・申請することで、Issueが作成されます。それをGitHub Actionsのワークフローでパースして、自動でPull Requestが作成されます。
Pull Requestに対して担当者以外のメンバーに承認されると、Scheduled Queryが作成されます。BigQueryではScheduled Queryの定義にしたがってクエリが実行され、データが作成されるという流れです。」
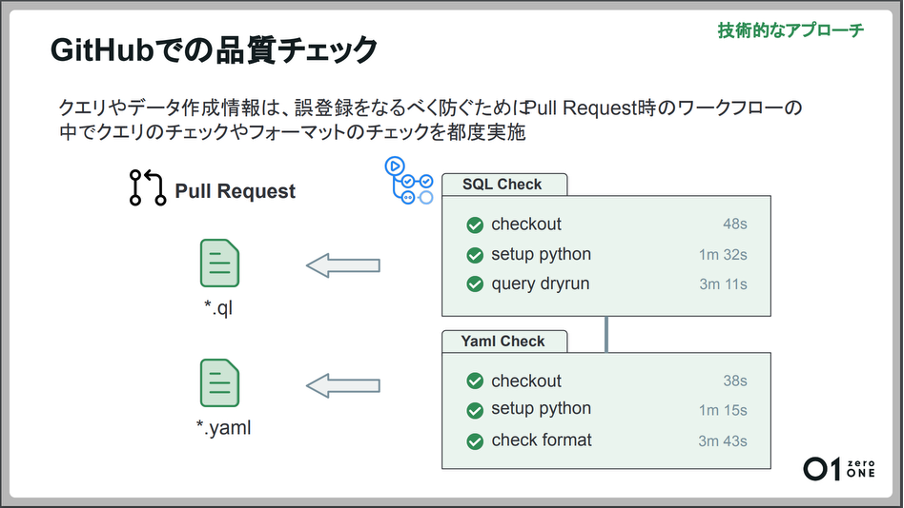
「担当者が作成するクエリやデータの作成情報は、誤登録をなるべく防ぐためにクエリの実行チェックと、フォーマットチェックをPull Request作成時に実施しています。クエリの実行チェックでは『文法に間違いがないか』『実行可能か』とチェックを実施します。
フォーマットチェックでは『各項目の値の検証や日付フォーマットが間違っていないのか』『選択できない文字列が入力されていないか』とチェックを実施しています。これにより、登録されるファイルの品質を一定担保するようにしています。」

「データ作成ですが、GitHubリポジトリ上でカテゴライズしたカンパニー✕プロジェクトの単位でデータセットが作成されます。プロジェクト配下にあるクエリやデータ作成情報に対応するScheduled Queryが実行されると、データセットの中にテーブルが作成されます。
また、データアクセスもデータセット単位で制御しています。データアクセスは不要なデータにアクセスできないようにするために、必要最小限にする必要があります。
そこでカテゴライズしたプロジェクト単位でユーザーリストを作成し、対応するデータセットの単位でユーザーリストにある該当ユーザーに対し、データのアクセス許可設定を入れるようにしています。
ユーザーリストは、データオーナーの承認をもって登録されるようになっており、登録されたタイミングで該当データセットにData Viewerの権限を付与します。誰がどのデータセットにアクセスできるのかを、この仕組みの中で制御していることがポイントです」(田中氏)
作成されたデータの顧客アプローチ施策での活用。監視や可視化の強化も実現
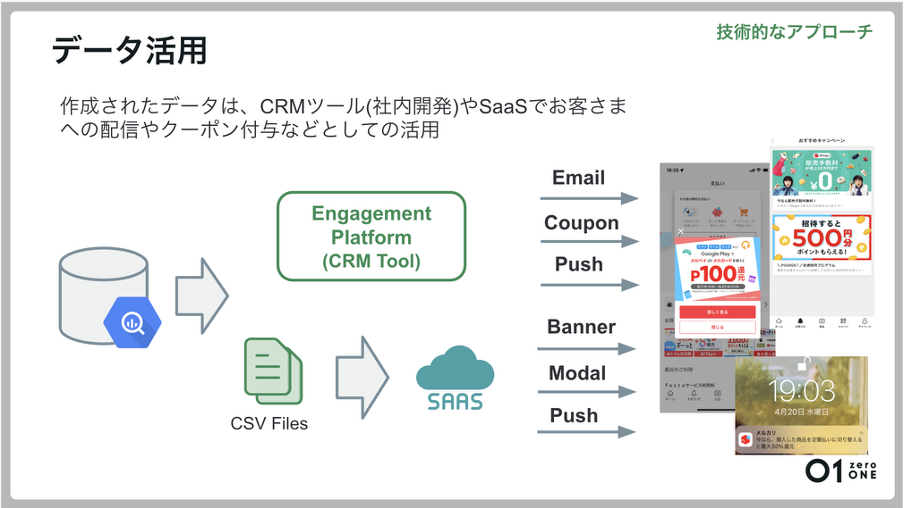
作成されたデータは、CRMツールやSaaSを介し、Eメール通知やクーポン付与、プッシュ通知、キャンペーン配信など、CRMの顧客アプローチに活用されています。
例えば、CRMツールへ連携するデータソースとして利用されています。作成したUser Attributeやイベントのデータを、CRMツールを経由してプロダクトに連携し、お客様への配信やクーポン付与などの用途に役立てています。
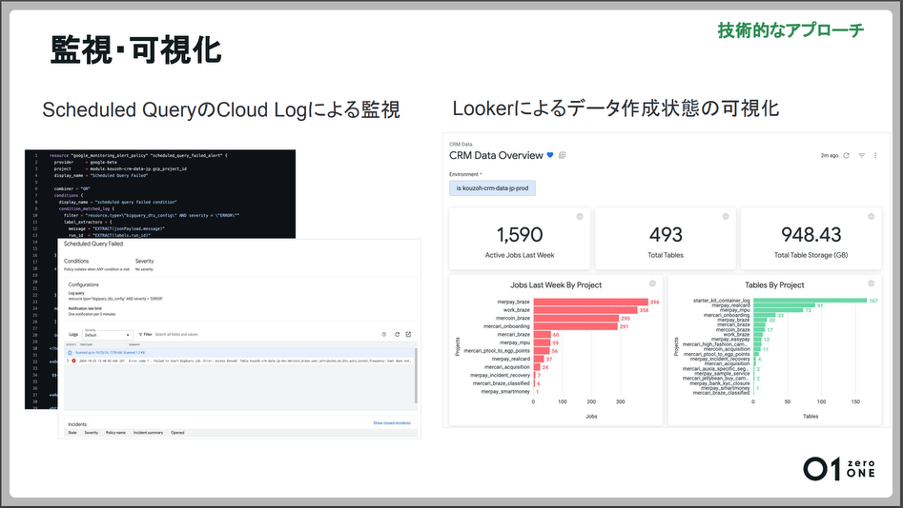
また、同社では監視や可視化についても同じ環境で実現しています。
「Scheduled QueryのログをGoogleのCloud Logで監視し、エラー時にはSlackに連携するようにしています。データの作成状況を可視化し、ジョブの実行状況やテーブル作成状況をダッシュボードで確認できるようになっています。ストレージされているデータ量やクエリの負荷はコストに返ってくるため、これらの可視化は非常に重要です」(田中氏)
向上したデータガバナンスで得られた5つの成果。改善したデータ作成環境に残る3つの課題
データガバナンスは大きく向上。5つの定性的な成果が得られ、データ品質、障害における予防・対応も改善
今回のセッションで紹介されたシステム構成と仕組みによって、定量面、定性面の両側面で効果がありました。
2024年11月現在で登録されたプロジェクトサービスは23、クエリの登録数は493。1週間に実行されるジョブは1,500になります。新しい配信の設定や既存のデータ作成クエリの修正を含めると、1週間で平均20数個のPull Requestが作成されています。また、SaaSへの連携数は、147にも及びます。

さらにデータガバナンスの側面でも大きく5つの定性的な効果が得られました。
① データオーナーの明確化
データオーナーが定義されるようになったことで作成されたデータに関する問い合わせや連絡が容易に
② 整備されたクエリ管理
GitHubでクエリやメタデータの管理ができ、どのクエリで、どのメタが、どのように作成されているのか検索が容易に
③ 承認プロセスの一元化
変更管理がGitHubのコミット履歴で確認可能に。データ作成に関する承認プロセスが一元化され、運用フローも統一することで誰が、いつ承認したのか、履歴で確認できるように。
④ データ作成状態の監視/可視化
CRMでどのようにデータが作成されたのか、全体の俯瞰が可能に
⑤ アクセス制御
データオーナーの承認のもと、データセットごとに必要最小限に権限が付与できるようになり、統制がとれるようになりました。
その他にも良かった点がいくつかあり、特に障害における予防や対応が改善しました。
① 未然の障害防止
自由な環境から統制され、管理された環境になったことで、障害における予防や対応が強化されました。データやクエリの品質が向上したことで、障害発生リスクを抑えることができたのではないかと考えています。アプローチの前のデータ作成時点で事前に失敗を検知できるので、お客さまへの影響が出る前に、未然に防ぐことができています。
② 障害発生時の調査
データオーナー、クエリ作成者、その承認者、クエリの変更内容など、GitHubリポジトリで管理され、すべて履歴で追跡できるようになっています。データも構造化され、対象のデータをすばやく見つけられるようになりました。同様に検索性が上がっており、クエリ修正やデータ再作成のプロセスも確立しているため、障害復旧時にも対応しやすくなっています」(田中氏)
新しい環境構築の全体を振り返り、当時躓いたポイントやシステム上に残る課題
定量面、定性面の両方でさまざまな効果を得られた一方で、現在地から振り返るといくつか躓いたポイントもあったと田中氏は振り返ります。
「1つ目の躓いたポイントは、新しい環境が構築され、以前の環境から移行する際に何ヶ月もかかってしまったことです。利用している組織が多岐に渡り、広い範囲で利用者に移行をお願いしないといけなかったこと、一部データのオーナーが不明であるにもかかわらず業務で利用されているケースがあり、移行できるかどうかのジャッジが下せなかったことの2点です。
時間はかかりましたが、データの利用状況等で利用者を整理、管理し、個別に調整することで移行を促しました。まず、新規の利用を止めて既存のデータ作成から移行し、最後にデータの参照切り替えという流れで進めました。オーナーが分からないものについては、今日までの利用を洗い出し、利用が分かりそうな関係者にヒアリングして、ひとつずつ根気強く対応することで障害など発生することなく、安全に移行を完了できています。
その他の躓いたポイントには、データ生成はユーザー側で任意実行できない点です。Scheduled Queryは一度登録されるとスケジュールにしたがって実行されますが、時として任意のタイミングで実行したいケースもあります。ジョブの実行権限をユーザーに付与すれば可能ではありますが、GUI上からScheduled Queryを手動で登録することもできてしまい、管理の抜け穴になってしまいます。
クエリの更新時に一度動かしたいという要望が強かったことから、環境のいち機能として設定を入れると、Pull Requestをマージした際に、ワークフロー内で即時実行する機能も提供しています。
最後にデータ品質を担保することには限界があるということです。以前の環境からすると間違える要素が格段に減り、品質が大きく改善しました。しかし人のオペレーションにはどうしてもミスが起こります。現在重要なデータ作成にはテスト環境を設けているので、そこで入念にテストすることを促進しています。また、システムチェックを強化することで、クエリの登録時にできるだけ気づけるようにしています。
ユーザーのデータ作成環境は改善した一方で、システム上の課題もまだ残っています。
1つはScheduled Queryの限界です。BigQueryのScheduled Queryは、クエリの定期実行においては非常に使いやすく安定しています。しかしScheduled Queryに関するメタ情報の保存や、失敗時の自動リトライがないなど、機能的に足りないところを感じています。
ユーザーは今回の環境によりGitHub上の設定だけでデータ作成までをすべて済ませることができるようになりました。そのため将来的には定期実行の仕組みだけをユーザーへの影響は少なく、Dataformなどの別の仕組みに差し替えることができるかもしれないと考えています。
2つ目はクエリ負荷の監視とアラートです。クエリ負荷が高くなった時の検知が、現時点では不十分だと感じています。想定時間内でクエリの実行が終わらない場合に、スケジュールごとのSLAを設定できることが理想です。
3つ目はデータ生成時の通知です。Scheduled Queryの通知機能があるので、そういうものを用いて実装することが可能だと考えています」(田中氏)
今後は機能的な課題を一つひとつ解決し、ビジネスサイドのデータ活用にもっと貢献していきたい

最後に今後の展望についてお話しいただきました。
「データの作成状況やデータ容量に関しては、Cloud Logやダッシュボードにより監視できています。しかし課題にも挙げた通り、クエリの負荷の監視や負荷高騰時のアラート、データ作成完了時の通知など、できることはまだまだ残っています。
さらにCRM関連でよく使われる属性情報などのデータを中間データ化してデータの冗長性を排除し、再利用性を向上させることにも取り組んでいきたいです。また、データのメタ管理をさらに改善し、データの検索性も高めていければと思います。
「今回のセッションでは、メルカリにおけるCRMへのデータ活用についてご紹介させていただきました。弊社では、ビジネスサイドのメンバーの多くがData Pratformに集計されたデータを自ら抽出、作成し、データを活用しています。
また内製のCRMツールやSaaSを使って、お客さま向けに配信しており、『データの民主化』は比較的進んではいるものの、同時にさまざまなデータガバナンスの課題も浮き彫りになりました。
今回ご紹介した『GitHubとBigQueryを中心に構築した新しい環境の仕組み』は、データガバナンスの課題に対応するものでした。実際にこの取り組みによってデータガバナンスは大きく向上し、データ品質も改善した一方でまだ機能的な面での課題も残っています。今後さらに改善し、ビジネスサイドのメンバーのデータ活用にもっと貢献していきたいと考えています」(田中氏)





