
課題・問題
秘匿性の高いデータの取り扱いと、事業拡大に伴うデータ連携の複雑化や保守工数の増大が課題に

元々データ基盤を構築されていたとお聞きしました。以前は、どのようなデータ基盤の課題を抱えていらっしゃいましたか。
用害:私はアナリストと経理部門を兼務しており、会計ツールの「freee」やバックオフィス用ツール「バクラク」といった秘匿性が高く、管理者以外による閲覧を禁止する必要があるデータを取り扱っていました。
当時はGoogle Apps Script(以下、GAS)を使ってスプレッドシートに反映させ、関数で加工し、それを元データとして別のスプレッドシートが参照するという多段的な構造になっていました。データの更新に時間がかかる上、データ構造の変更などが発生した時のメンテナンスコストの高さが課題でした。
小野:合わせて、社内ではさまざまなSaaS製品の導入が進んでいました。SalesforceのデータをBigQueryに転送したいという要望が出てきたのも同時期でした。その頃はエンジニアが作ったスクリプトをワークフローエンジンで実行し、データを連携していました。この運用には高度な専門知識が必要なため、保守・運用もエンジニアに依存してしまいます。新しい連携要望が出るたびに開発工数が発生し、リードタイムの長期化が大きな課題でした。
具体的には、既存項目の追加・削除に伴うソースコードの修正やSaaS側APIの仕様変更への追従、コンテナ上で使用しているライブラリの脆弱性に対するメンテナンスといった保守作業のコストが継続的に発生していたのです。
また、新しいSaaS製品のデータ取り込み要望が出た場合にも、API仕様の調査やスクリプトの実装・テストといった工程が必要となり、データエンジニアの作業がボトルネックになっていました。そこで、専門知識が不要で簡単にデータが連携できる環境を作れないかと検討しました。
ビジネスサイドの方も当時の業務で課題を抱えられていたとお聞きしました。BPR本部ではどのような課題を抱えていたのでしょうか。
内田:BPR部門では、「STORES 決済」の利用を開始する事業者様へ決済端末を配送する業務を担っています。当時、手作業によるオペレーションの限界を感じていました。
事業規模の拡大に伴って、「A店舗には送付するが、B店舗には送付しない」など要望が多様化し、従来のスプレッドシートによる手動運用では対応しきれなくなってしまっていたのです。
佐藤:BPR部門やセールス部門などの事業部サイドでは、それまでもSalesforceやkintoneをはじめとしたSaaS製品とスプレッドシート間の連携がGASを使って広く行われていました。
しかし、GASがチームや担当者ごとに作られていたため一元管理されておらず、どこでどの処理が動いているのか把握しづらい状態でした。また、GASの開発・保守にも一定の工数が発生しており、本質的な課題解決には至っていませんでしたね。
なぜ「TROCCO」を選んだのか
国内SaaSへの幅広い対応とサポート体制の充実、チーム機能によるガバナンス向上を高く評価

「TROCCO」の導入の決め手は何だったのでしょうか。
佐藤:海外製のデータ転送ツールも候補に挙がりましたが、その中で「TROCCO」を選んだ理由は、大きく3つあります。
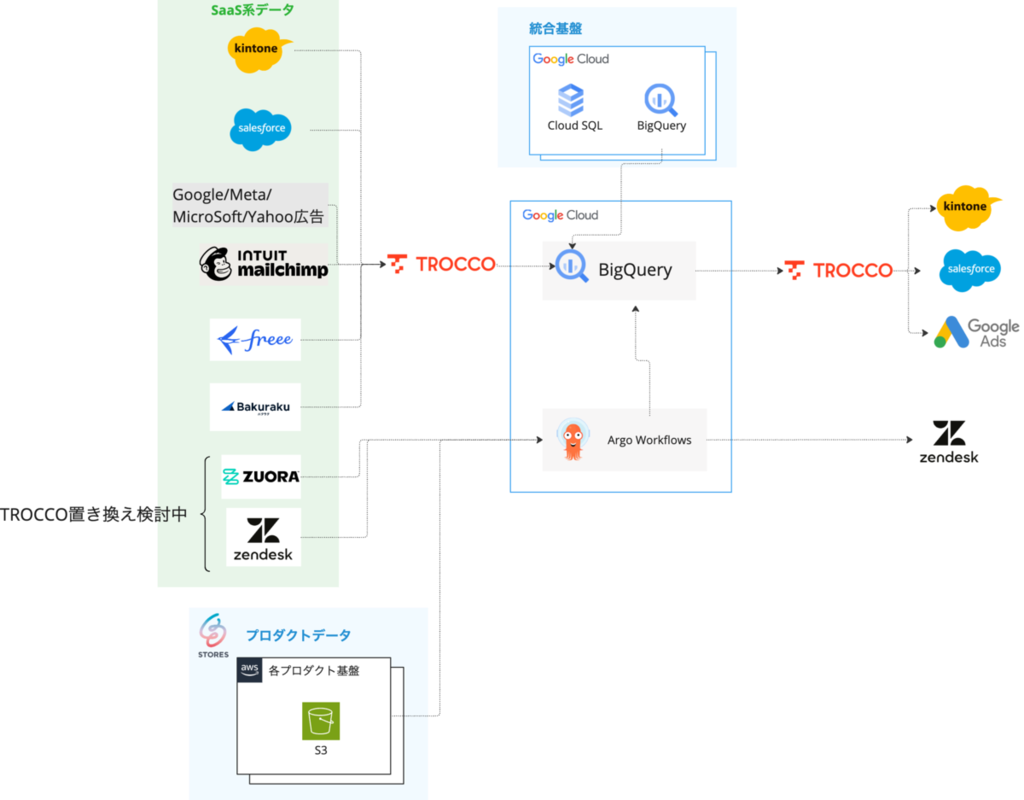
1つ目は、STORES で利用している国内SaaS向けのコネクタが充実していることです。kintoneやfreee、バクラクなど、弊社が利用しているサービスにも幅広く対応している点が魅力的でした。
2つ目は、SaaS側からのデータ転送だけでなく、BigQueryからkintoneへデータを書き戻すリバースETLといったデータ追加・更新が標準機能として提供されていることです。
3つ目は、ビジネス部門での利用も想定し、日本語中心でエンジニア職種以外のメンバーでも理解しやすいGUIである点です。データチームだけでなくビジネス部門での利用も見据え、サポート体制も含めて使いやすい点が決め手となりました。
小野:実は前職でも「TROCCO」を利用しており、全社的なETLツールとして営業やマーケティングの担当者が自分でデータ転送を行っている環境がありました。そのため、以前から「TROCCO」には、専門知識を持っていない事業部側のメンバーでも使いやすいというポジティブなイメージを持っていました。
また、freeeとバクラクのデータに関しても「TROCCO」のチーム機能を活用することで、データ転送処理自体の操作権限を限定して安全に管理できそうだと感じた点も、導入の後押しになりました。自分たちで実装することも検討したのですが、閲覧権限の切り分けなどの実装コストがかなり高く、「TROCCO」で解決できるのではないかと問い合わせさせていただきました。
活用までのスケジュール・過程
エンジニアを介さずビジネス部門のみで「配送自動化システム」を構築。ビジネス部門が自らデータを動かす文化の醸成

導入後の具体的な運用体制について教えてください。
佐藤:2025年7月から「TROCCO」を導入し、基本的にはSaaS間の連携を「TROCCO」に置き換える方針で進めました。直近でCRM環境を統合した新しいSalesforceを構築した際も、マネージドデータ転送機能により1〜2日でBigQueryへの連携を完了できました。
ただし、各プロダクトからの日次データ転送については、事業者様向けのデータ分析機能にも利用されていて社外への影響も大きいため、引き続き既存のワークフローエンジン上で実行し、STORES 内で品質を管理できる構成を維持しています。
小野:「TROCCO」導入時は、freeeの仕訳帳のデータを取得するためのコネクタがなく苦労した場面もありました。しかし、「TROCCO」のカスタムコネクタ機能を活用して上手く対応することができました。決まったことしかできないようなツールではなく、エンジニア自身で自由にカスタマイズできる点も魅力でしたね。
BPR本部ではどのようにシステムを構築されたのでしょうか。
内田:AIを活用しながらkintoneにJavaScriptを組み込む方法を学びつつ、エンジニアの工数を使わずに決済端末の配送データ作成システムを半年ほどかけて構築しました。
「TROCCO」の導入によってデータ連携の仕組みが整ったことで、BPR部門が自分たちだけで業務システムを作り上げられる環境が生まれたのです。UIの使いやすさとコスト面から選んだkintoneに全データを集約し、配送オペレーション全体の自動化を実現しました。
現在は「TROCCO」が決済DBからBigQueryにデータを引き込み、加工したデータをkintoneの配送データアプリにリバースETLで連携してくれています。さらに発送処理後の管理画面へのステータス反映も自動化され、手作業の負担が大幅に解消されました。
ビジネス部門へのさらなる展開も進められているとお聞きしましたが、具体的にどのような取り組みをしているのでしょうか?
佐藤:primeNumber社にご協力いただき、Salesforceおよびkintoneを題材としたレクチャー会をビジネス部門向けに開催しました。
主にスプレッドシートとの連携を題材にレクチャー会を実施したのですが、参加者からは「現在GASで実行している処理を「TROCCO」で代替できないか」など、具体的な質問が多く寄せられました。
内田:「TROCCO」を使うことで日々の業務でできることが増えるため、普段kintoneを使っているメンバーからも非常に前向きな反応が多かったですね。私自身も、普段使い慣れているkintoneやSalesforceとそのまま接続できる安心感があり、直感的に操作できることに手応えを感じています。
特にkintoneのフィールドコードの取得が自動化されている点は、以前は手作業で対応していた部分だったので、非常に便利だと感じました。
導入後の効果
日頃の運用・保守からの脱却で、エンジニアはAI活用に向けたデータ活用推進の施策へ注力

「TROCCO」とkintoneの連携によって、どのような効果がありましたか?
佐藤:技術面での最大の効果は、新しいデータ連携の構築スピードが大幅に上がったことです。以前は仕様確認から実装・テストまで2〜3日かかっていましたが、現在は半日ほどで完了できるようになりました。
既存項目の変更にも画面上で柔軟に対応でき、エンジニアの作業工数が大幅に削減されています。さらに、ワークフロー機能により、BigQueryからkintone更新後のGCS連携などにも迅速に対応できるようになりました。
用害:既存のGASを使った手動オペレーションが「TROCCO」に置き換わったことで、処理のロジックが可視化されメンテナンスコストが下がりました。
また、導入前に課題としていたfreeeやバクラクの経理データについても、「TROCCO」のチーム機能を活用することで閲覧・操作権限を適切に限定でき、セキュアな管理体制を実現できました。今後は集約したデータを活用した分析に、本格的に取り組んでいきたいと考えています。
内田:ビジネス面では、kintoneと「TROCCO」の連携により、データ作成の工程が自動化され、大幅な工数削減につながっています。特に、エンジニアに頼らず業務システムを構築でき、長年の手動運用による負担が解消された点は大きな成果です。
小野:定量的な工数削減に加え、データエンジニアが本来注力すべき業務に集中できるようになった点も大きな変化です。
正直AI時代になったからこそ、自前でスクリプトを組むなど、データソースの取り込み自体は誰でもできるようになったと思っています。しかし、人間が同時に検討できるリソースには限界があります。
これまでは常にデータ取り込みの保守対応が頭の片隅にあり、並列して抱えるタスクが多い状態でした。しかし、データを取り込むことは私たちデータエンジニアのメイン業務ではなく、活用できる形にして届けることが最も重要です。「TROCCO」にその役割を委ねることで、そうした負担から解放されました。
その結果、AI活用に向けたデータ整備やモデリング改善など、より本質的なデータ活用推進の施策にリソースを集中できる体制が整っています。
今後の展望
ガバナンスを維持しつつ、AIを活用して誰でもデータ取得ができる環境の構築を目指す

今後のデータ活用について、どのような展望をお持ちですか?
内田:BPR部門としては、社内に散らばっているNotionやスプレッドシートなどのさまざまなツールやデータを、まずはSalesforce等に集約していきたいと考えています。そのうえで、より誰もがデータを取りやすく整理された状態に整備し、全体最適化を進めていくつもりです。そして最終的には、顧客体験の向上を実現できる環境を作っていければと考えています。
佐藤:データ本部として、データ基盤側にガバナンスを効かせながら情報を集約し、適切な場所へ再配信する仕組みを強化したいと考えています。
「TROCCO」を活用してSaaSのデータを引き込みつつ、kintoneを連携したデータ利用への対応やデータマート機能の適用を進め、ビジネス部門への「TROCCO」展開を加速させていきます。また、データ連携が複雑化するなかで適切なシステム構成への移行も進めたいです。
小野:今後はSlack botやAIエージェント、「TROCCO」のTerraform Providerを活用し、誰もがSlack上での対話で自律的にデータを入出力できる環境を作りたいと考えています。ただし、混乱を防ぐためにも統制を取りながら、PDCAを回せる仕組みを模索していく予定です。
現在、社内ではAI活用が非常に活発で、多くの成功事例が生まれつつあります。単にデータを管理するだけでなく、安全な「ガードレール」を整備することで、誰もが迷わずデータを使える土壌を整えることが、今の私たちの仕事における最も面白い挑戦だと感じています。
最後に、これからデータ活用に取り組む企業へメッセージをお願いします。
小野:データ基盤の保守に負担を感じている小規模なエンジニアチームにとって、「TROCCO」は非常に有効です。特定のツールに縛られるベンダーロックインを懸念されるかもしれませんが、TROCCOは極めてシンプルなツールです。そのため、ツールに依存しすぎず、組織の成長フェーズに合わせて柔軟な戦略が立てられる点も大きな魅力です。
エンジニアとして本来向き合うべき時間を作りたいと考えているチームには、ぜひ一度導入を検討してみてほしいです。そうした環境づくりこそが、結果として組織全体のデータ活用を次のステージへと押し上げるきっかけになると思います。
佐藤:「TROCCO」がデータの土台をしっかりと作ってくれることで、心理的な安全性が担保されています。データのデリバリースピードが劇的に上がり、できることの幅が広がるため、データ活用の基盤を次のステージへ引き上げたい企業にはぜひお勧めしたいです。
お問い合わせ
導入やデータ基盤に関してお困りごとがあればお気軽にご相談ください。






