
アドホックな依頼から解放されるために
ビジネス部門から届く「この数字を今すぐ出してほしい」という要望。これに応えるためにデータ担当者がSQLを書き続ける運用は、組織の時間を奪い続けます。
この停滞を打ち破るには、AIが担当者の代わりに回答できる環境を作らなければなりません。COMETAは、Redshift上の膨大なデータにビジネス上の意味を紐付け、AIが独り立ちして集計できる状態を整えます。
Amazon Qがソリューションとなるか
Amazon Redshiftを利用していれば、Amazon Qをはじめとする生成AIツールを試したことがあるかもしれません。しかし、実際にSQLを生成させてみると「意図した集計結果にならない」「微妙にカラム名が違う」といった壁に突き当たり、結局は手動で修正しているケースも少なくありません。
AIが正確な答えを返せないのは、AIの性能不足ではなく、AIに渡している情報の質に原因があります。
Amazon Qの精度を左右する「情報の不備」
AIはナレッジが全くない状態だと、データベースに存在する物理的なテーブル名やカラム名を頼りにSQLを書こうとします。しかし、実際の業務データには「本番用とテスト用が混在している」「論理削除フラグの扱いが複雑」「売上の定義が事業部ごとに異なる」といった特有のルールが存在します。
こうしたルールをAIが知らない限り、どれだけ高度なモデルを使っても正確な集計は不可能です。RedshiftでAI活用を軌道に乗せるには、AIが迷わずに参照できる正確なナレッジをあらかじめ用意しておく必要があります。
テーブル定義を超えた「社内の暗黙知」を資産にする
「アクティブユーザー数」や「今月の売上」の定義は、テーブルの型定義だけでは表現できません。これらは特定のテーブルに縛られない、会社独自の判断基準だからです。
COMETAでは、こうした暗黙知を「用語集(Glossary)」として一元管理できます。AIはこの用語集を事前知識として読み込むため、Redshiftの物理構造とビジネスコンセプトを結びつけた、文脈に沿った回答が可能になります。
用語集の定義例

ベテランのアナリストのように「問い返す」AIの実現
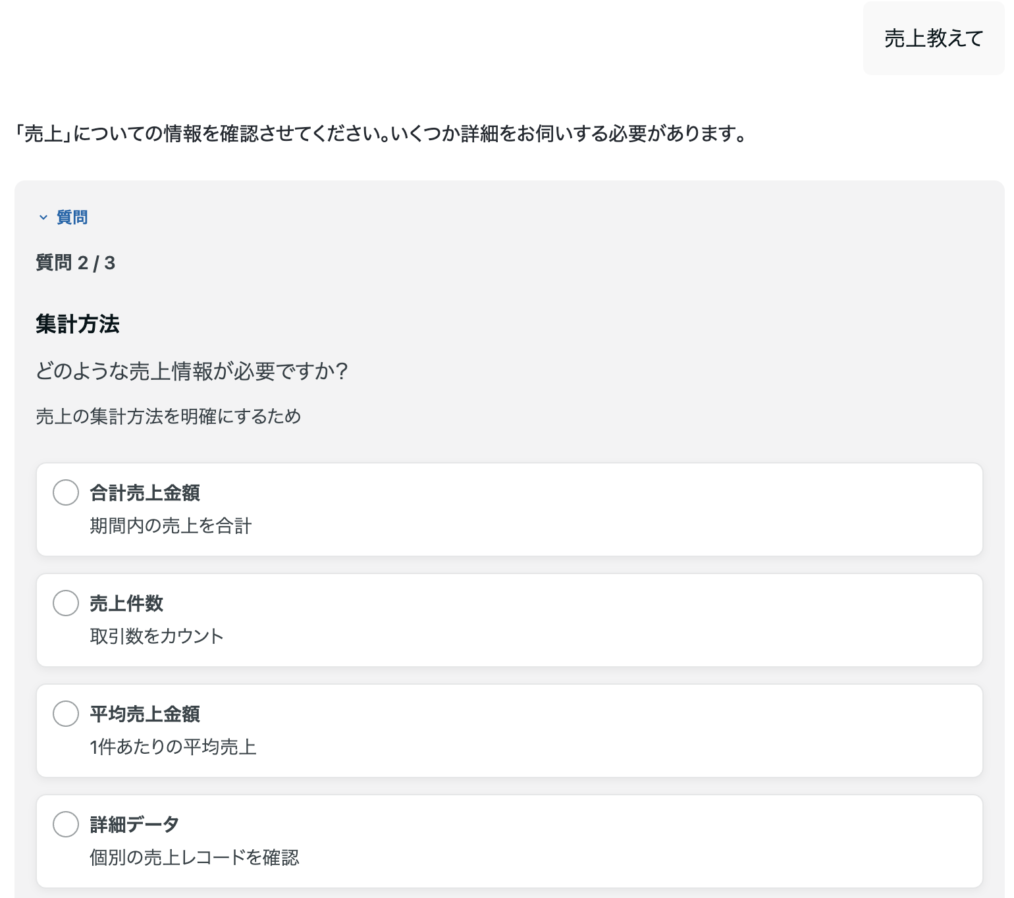
適切なナレッジが整備されると、AIの挙動は大きく変わります。優秀なデータアナリストが曖昧な依頼をそのまま受け取らず、必ず条件を確認するのと同様の動きが可能になるからです。
「売上を分析したい」というユーザーに対し、AIは「どのプロダクトの数字か」「キャンセル分は含むか」「集計の粒度は日次か」といった対話を自ら開始します。COMETAによって蓄積された用語集を基に、不足している条件をAIが問いかける。この「すり合わせ」のプロセスを経てSQLを生成するため、人間のアナリストに依頼するのと遜色ない精度で結果を出せるようになります。
使い続けられる、徹底的に磨かれたUX
どんなに高度な機能があっても、使いにくければ社内に浸透しません。COMETAは、データカタログとしての圧倒的な使いやすさにこだわっています。
直感的なインターフェースにより、データ担当者だけでなくビジネス部門のユーザーも、迷わず必要なデータや用語に辿り着けます。この「シンプルな使い心地」こそが、AIへのナレッジ入力を習慣化させ、精度の高いAIデータ活用基盤を支える土台となります。
まとめ
AIに正確なSQLを書かせる鍵は、技術的なチューニング以上に、社内のナレッジをいかに整理するかにあります。COMETAでAIに向けた道しるべを整え、アドホックな作業から解放された、本来あるべきデータ活用の姿を取り戻しませんか。
COMETAについての詳細をより詳しく知る
本記事で紹介しているCOMETAの製品資料はこちらのフォームよりダウンロード可能です。





