
前職では商品企画やマーケティングに従事し、Sansan株式会社に入社後は名刺アプリ「Eight」のプロダクトマーケティングおよびデータアナリティクスに取り組んだのち、現在は採用マーケティングと人事本部全体のデータ活用を進める石橋 政幸氏。
部署内に充分なデータはなく、自身もデータエンジニアリングのバックグラウンドがない状況でも、「データドリブンな体制は作れる」と石橋氏は強調します。本セッションでは、主に採用領域においてデータ活用を始めていくにあたり、どのような課題を乗り越えて、現状どのようにデータ活用を進めているのかについてご紹介いただきました。
登壇者情報
石橋 政幸 氏
Sansan株式会社 人事本部 CHRO室 戦略人事グループ
新卒で大手自動車メーカーに入社し主に量販車種の商品企画・マーケティングに従事したのち、2021年にSansan株式会社へ入社。名刺アプリ「Eight」のプロダクトマーケティングおよびデータアナリティクスを担当しユーザー基盤拡大に貢献。2023年に人事本部へ異動し現在は採用マーケティングを主としつつも、人事本部全体のデータ基盤構築のプロジェクトをリード。
人事がデータ基盤構築に至るまでの背景と課題
気合と経験に頼り気味な採用に課題感。「属人的」「コスト依存」「人力」の課題解決へ

従業員数の増加に応じて人事の人員数も増加するなか、多大なカネ・ヒト・時間を投入することで採用数の拡大を維持していたSansan社。効率的・戦略的な採用活動が行えておらず、そうした状況を石橋氏は「気合と経験に頼り気味な採用だった」と当時の課題を振り返ります。
「当時の採用活動における課題は、『属人的』『コスト依存』『人力』の3つでした。データを用いて定量的に採用戦略を立案するのではなく、リクルーターの経験則・経験談で『属人的』な意思決定を下すことが習慣化していました。
『コスト依存』とは、人材紹介会社・転職エージェントに頼りきりだった状況を指しています。転職の市場感の把握から、求人に対して応募数を集める母集団形成までお任せしており、人材採用後の成功報酬のコストが膨らんでいました。
そして、採用活動全般におけるテクノロジーの活用が限定的であり、人員不足への解決策が『人力』しかなかったのです。その結果、自分自身でデータを活用できておらず、人事人員の気合と経験でなんとか採用活動を進めていました」(石橋氏)
データマネジメントを難しくする「存在しない」「汚い」「揃わない」のないないづくし

採用活動における課題を解決し、同社の事業拡大を支える人事戦略を描くため、まずはデータの整備から着手されました。同社における「採用のデータ」は大きく4つです。
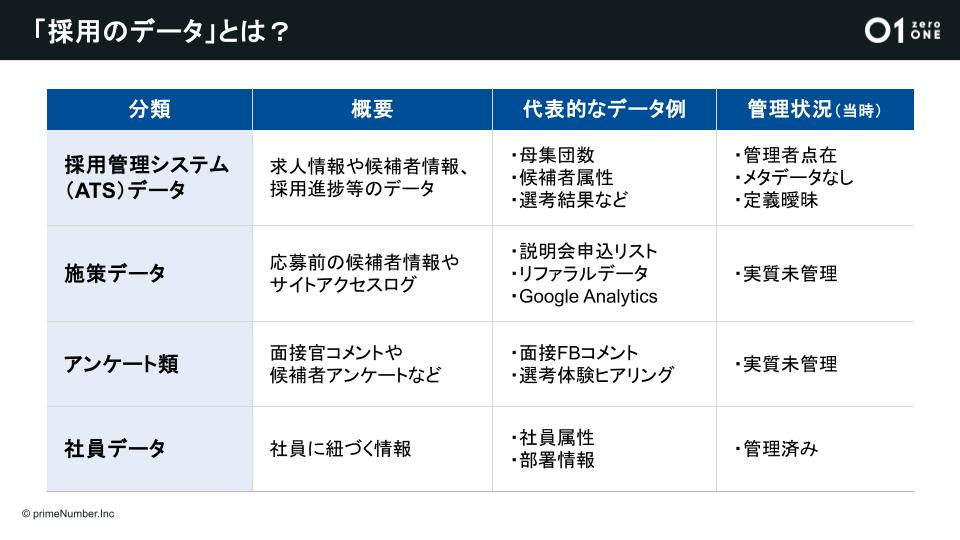
- 採用管理システム(ATS)データ:求人情報や候補者情報、採用進捗等のデータ
- 施策データ:応募前の候補者情報やサイトアクセスログ
- アンケート類:面接官コメントや候補者アンケートなど
- 社員データ:社員に紐づく情報
特に重要なのが採用管理システム(ATS)のデータです。このデータを整備することで施策データや社員データとの連携が進み、さらに加工することで月間の応募数や書類選考数、通過率まで見える化されます。

「データマネジメントを進めるにあたって『存在しない』『汚い』『揃わない』の“ないないづくし”にハマってしまいました。そもそも『必要なデータ』を定義できておらず、定義できても組織のサイロ化によって誰が何のデータを管理しているか不明で必要なデータが取れていませんでした。
また、取れていたデータも表記揺れや不整合は当たり前でした。フォーマットは統一されておらず、データの出所さえ怪しいものもあり、データを受け渡して連携できる状態ではなかったのです。メタデータはなく、採用担当者によって『応募』といった指標の定義が三者三様、見ているダッシュボードも違うので数字が合わないといった状態が続いていました」(石橋氏)
非データエンジニアが直面した“スプレッドシート地獄”。関数の多用や膨大なデータ量のため、スプレッドシートの管理に1日あたり30分〜1時間も

当時、部署内にデータエンジニアがおらず、そして石橋氏自身もデータエンジニアリングのバックグラウンドがありませんでした。そのため、まずはスプレッドシートに優先度の高いデータを落とし、使える形に加工するところからスタートしました。
採用データのほとんどが自動連携できず、手動でダウンロードしなければならなかったものの、Google スプレッドシートの関数を上手く活用することでカラムの作成やクレンジング、カテゴライズを進め、それらをもとにデータマートを作成してBIツールのLooker Studioで描画するまで実現しました。

「しかし、そこから先は“スプレッドシート地獄”だったのです。本来Google スプレッドシートは『表計算ソフト』であるため、処理スペックとボリュームで問題が発生しました。関数を多用しているので処理待ちや処理落ち、Looker Studioとの連携エラーが頻発。さらにスプレッドシートは1,000万セルという上限があるため、定期的にスプレッドシートを差し替えねばなりません。
企業が大きくなるほど抱える人事データは膨大になり、7〜8万人分の候補者データを150〜300列も保存することになるため、すぐにパンクしてしまいます。また、データの加工用に子・孫シートも管理していたため、スプレッドシートの管理だけで1日あたり30分〜1時間も無駄に費やしていました。
こうした“スプレッドシート地獄”は、データエンジニアではない私でさえも『おかしい』『なんとかしなければ』と考えるようになっていました」(石橋氏)
たまたま出会ったテックブログがきっかけに。データ基盤で重視された「真正性」「拡張性」「簡便性」

「自社のエンジニアに相談しても理解が難しく、どうしたらいいかわからないと困っていた頃に運命的に出会ったのが、エンジニアがいない組織で1からデータ基盤を構築した話という私にとっての“救いのテックブログ”でした。
過去に01も登壇されたことがある非エンジニアの方が書かれたブログで、データ基盤の構成やETLツール、そして『TROCCO』を知りました。候補者の個人情報といったセンシティブデータの権限問題や、データ取得のための採用オペレーションとデータは密接におくべきと判断し、社内エンジニアを介さずにデータ基盤の初期要件を固めました」(石橋氏)
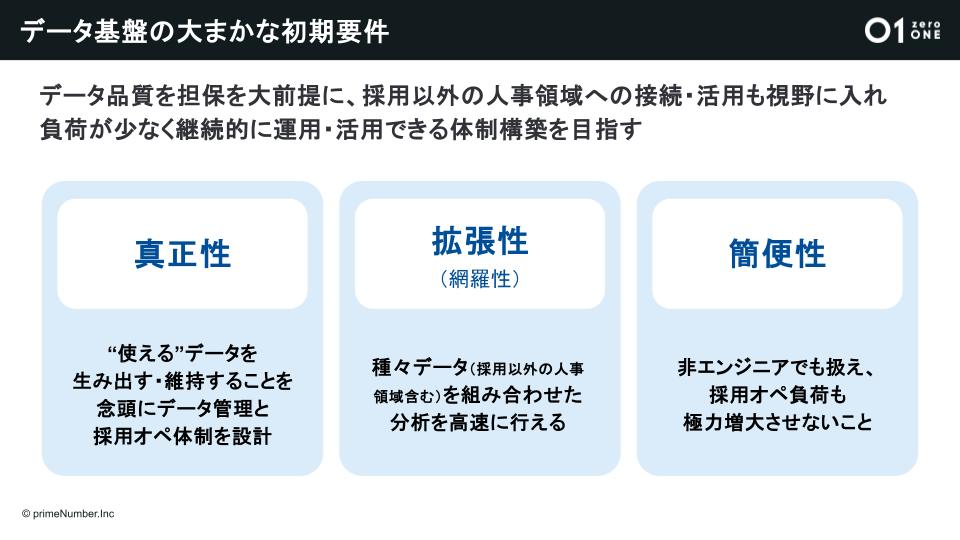
データ品質の担保を大前提に、採用以外の人事領域への接続・活用も視野に入れ、負荷が少なく継続的に運用・活用できる体制構築を目指すため、初期要件では『真正性』『拡張性』『関連性』の3点が重視されました。
- 真正性:“使える”データ、つまり信用できるデータを生み出し、維持することを念頭にデータ管理と採用オペレーションを設計する
- 拡張性:採用以外の人事領域を含むデータを組み合わせた分析を高度に行える
- 簡便性:非エンジニアでも扱えるツールを採用し、人事の通常業務を圧迫しないように採用オペレーションの負荷を抑える
導入の決め手は簡便さとコネクタ数の多さ。「TROCCO」を活用したデータ基盤構築の実務
「TROCCO」のカスタマーサクセスがサポートしながらデータ基盤を構築。並行して採用管理システムをリプレイス
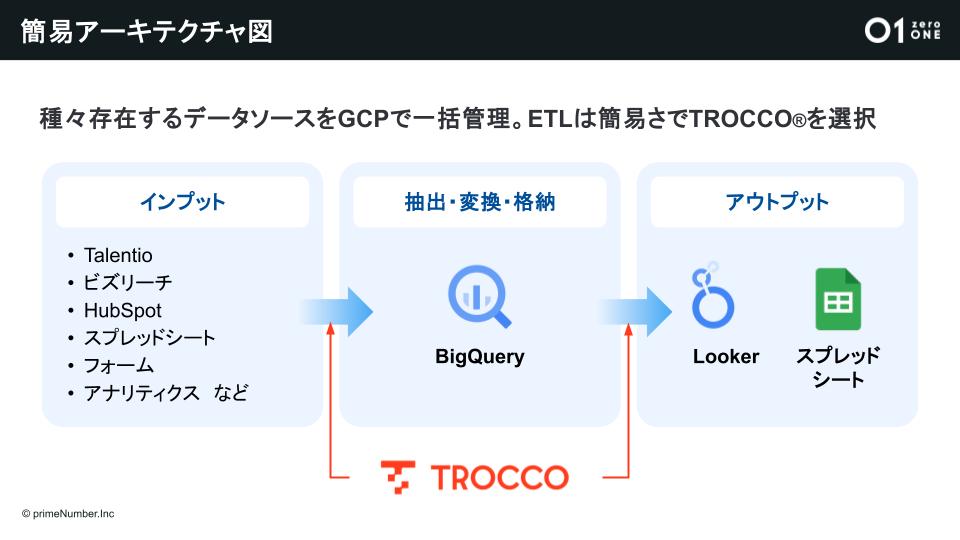
先述のテックブログの記事を参考にデータ基盤を設計しました。ETLツールには操作における簡便さ、コネクタ数の多さから「TROCCO」が採用されました。
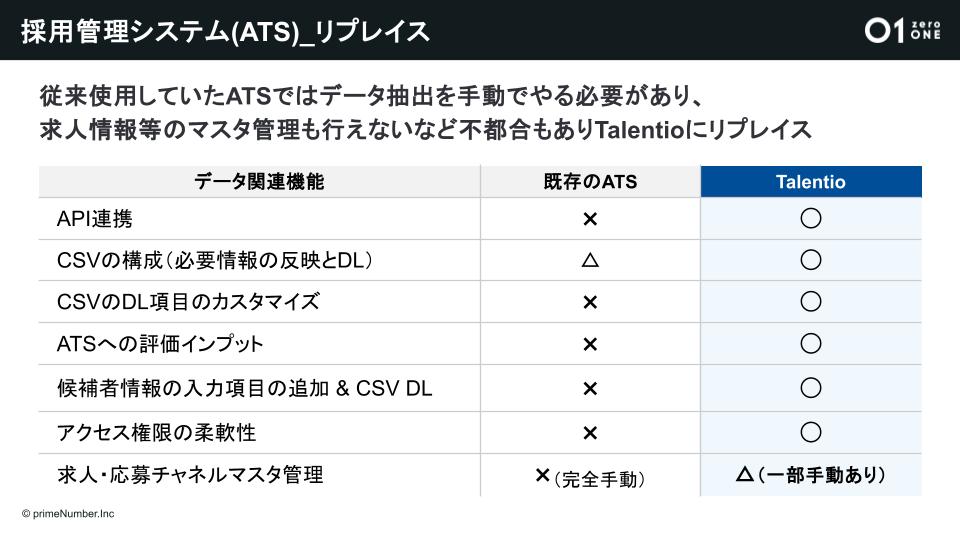
データ基盤の構築と平行して、API連携ができる採用管理システム(ATS)にリプレイスしました。既存のものも使いやすいツールでしたが、データドリブンな採用を実現するためにはAPIの連携やダウンロードするCSVのカスタマイズ性など、データ基盤との相性が優先されました。APIを使うことでデータは高品質でミスがなく、きちんと転送されます。
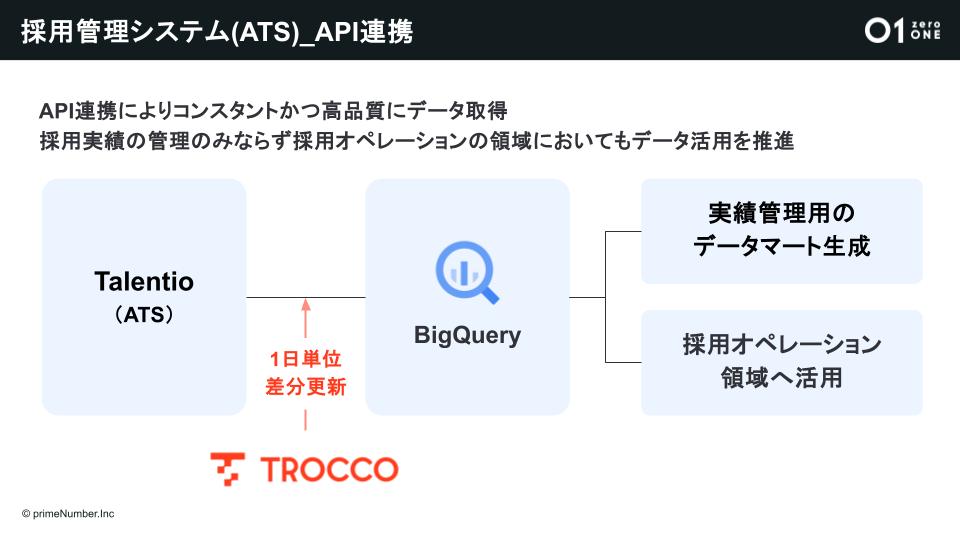
「データ基盤構築では、前回転送時からの増分データのみを転送する差分転送を設定しました。その際には、primeNumber社のCSの方に手厚くサポートいただきました。さらに実績管理用のデータマート生成や採用オペレーションへのデータ活用も進んでいます」(石橋氏)
「TROCCO」のデータマート生成を活用。観測すべき指標を整理し、必要なデータを定義・取得

データ基盤の構築後も依然として人事担当者ごとにデータの解釈が異なる状況を受け、観測すべき指標を整理した上で必要なデータを定義・取得するためのデータマート作成をスタート。
データマート作成の3つのステップとして、まずは「どの状態の候補者を『応募』とみなすか」定義を決め、Notion上で管理することで指標定義をすり合わせることから始めました。次に現状把握やPDCAを回す際、どのようなデータの、どのような切り口が求められるかを担当者とすり合わせ、ダッシュボード設計に落とし込んでいます。
最後のステップとして、『TROCCO』のデータマート生成にあるSQLエディタで定義・処理・結合しました。関数で一つひとつ定義していた“スプレッドシート地獄”の頃と比べて作業が楽になっただけでなく、漏れがなくなり、データ品質も向上しました。
「人事データはオペレーションの賜物」。データ活用を支える採用オペレーション設計

「人事データはオペレーションの賜物」と話す石橋氏が特に重視していたのが、データ入力・取得に関する採用オペレーションの業務設計です。同社の採用組織には、アシスタントを含め約30名の採用オペレーション専任の人員が在籍しており、主に以下の2つのデータ関連業務を実施しています。
- 採用管理システム(ATS)へのデータ入力:各選考の日程調整から結果入力までを実施。未入力を検知したらSlack上でアラート
- 追加データ手動取得:特にスカウト媒体はAPI連携できない場合が多く、スカウトの送信数・返信数を取得するオペレーションを構築。さらに候補者からのヒアリング情報も取得している
各媒体のスカウトの送信数・返信数を取得することで、採用の母集団形成におけるPDCAを回すことができます。応募数の少なさはスカウトの数の少なさが起因しているのか、そもそもスカウトに返信が来ていないのかなど状況を把握し、次のアクションを起こすことができます。

その他にも、構築したデータ基盤を活用する意識を醸成する施策として、BIツールのLooker Studioで自由分析用ダッシュボードの公開や、社内向けにグラフやピボットテーブルを作成する講座を開催しています。
採用領域のデータ活用で得られた成果と今後の展望
採用プロセスを改善し、戦略構築にデータを活用。通過率や採用コストを改善し、採用要件の見直しも

採用領域におけるデータ活用の取り組みによって、同社では現在どのような形でデータを扱っており、どのような成果が得られているのでしょうか。採用データの活用シーンとして石橋氏が最初に挙げたのは「採用プロセスの改善・戦略構築」でした。
「ATSデータや施策データ、コストデータなどを組み合わせ、採用における母集団形成から内定フェーズまでさまざまな用途に活用しており、その事例をご紹介します。
1つ目の活用方法は、面接通過率や内定承諾率の改善です。たとえば特定のポジションにおいて二次面接への通過率が低くなれば、その異常を検知して採用基準の再伝達といった対策を講じます。また、特定の職種における内定承諾率が低ければ、候補者の情報なども参考にしながら応募者の方専用のオファーレター作成も行います。
2つ目の活用方法は、採用活動のコスト改善です。ATSデータからスカウト媒体ごとにポジション別の反応率を見ていき、スカウト媒体ごとの傾向や適した職種を分析していきます。さらには媒体ごとの内定承諾数とコストデータをかけ合わせ、1件の内定承諾にかかるコストを横並びで比較し、母集団形成に最適な媒体を選定しています。
3つ目の活用方法は、採用要件の見直しです。弊社では面接官のコメントを積極的に収集し、面接を通過した候補者の傾向を掴む参考にしています。特に候補者に対する評価のコメントを重視し、面接官が面接の場で重視している要素と採用要件を照らし合わせます。現場が求める人材像のイメージを正しく汲み取れているかを把握し、採用要件の見直しも行っています」(石橋氏)
給与水準の競争力維持・向上や、採用オペレーションへのフィードバックにもデータを活用

採用領域におけるデータ活用事例として、同社では給与水準の競争力維持、向上にもデータを役立てています。ATSデータや候補者の現年収データ、弊社から提示した給与と条件といった自社データと、外部のサーベイを掛け合わせた分析をボジションごとに行うことで、自社の給与水準の競争力を把握し、実際に給与の改定にも繋がっています。
また、調査データから候補者が選考を受けている競合他社ごとの勝敗数を集計・分析し、競合他社と比べて正しい給与を提示できているかを判断しているそうです。実際に特定の職種において、給与の改定が内定承諾率の改善につながっています。
その他に採用オペレーション業務へのフィードバックに役立てている事例もご紹介いただきました。内定承諾後の入社手続きは、人事以外にも総務や経理、情報システム部、そして受け入れ先部署と、複数の部署をまたぐために情報が混線しやすくなります。そこで確定した入社日やスカウト媒体へ支払う採用fee、給与、入社時の準備物などの情報を採用データベースから必要シートに転送することで、入社後のスムーズな手続きを実現しています。
データを活用した採用マーケティングによって、タレントプールによる「農耕型」の採用を実現
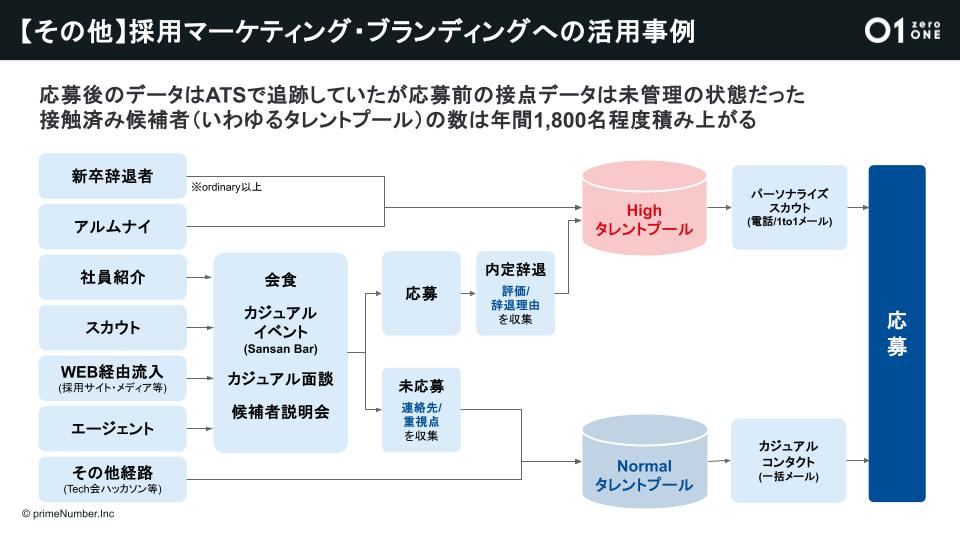
「以前は人材紹介会社・転職エージェント、スカウト媒体などにコストを集中し、一気に候補者を獲得して採用を進めていく『狩猟型』の採用活動が中心でした。こうした採用活動は今後も続けていくものの、採用データを活用できるようになったことで『農耕型』の採用活動も行っていきます。
選考に参加いただけなかった方や内定を承諾いただけなかった方のデータをしっかりプールして数年単位で接点を維持し、獲得までナーチャリングし続けていく『タレントプール』による採用が可能になったのです」(石橋氏)
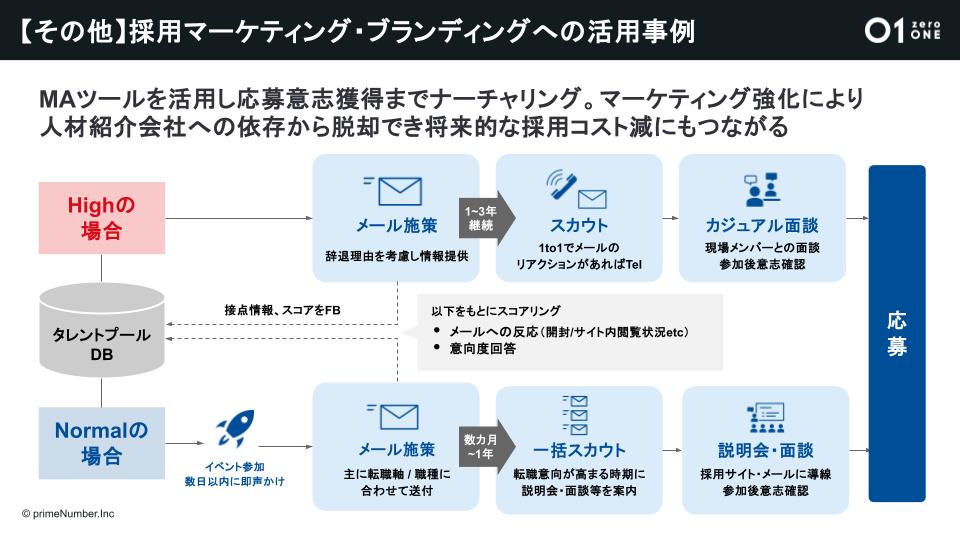
タレントプールを活かした採用マーケティングでは、MAツールの活用とメール施策が中心です。定期的に接点を作りながらメールの開封やリンククリックといった反応をスコアリングし、急にスコアが上昇したら転職への興味・関心が高まったと判断。カジュアル面談の案内をお送りして応募意思の獲得につなげています。
また、接点を作るためにコンテンツは重要です。コンテンツやイベントを企画するブランディング担当の部門に、施策に合わせたイベント開催の打診や、メールへの反応からコンテンツやイベントのフィードバックを実施しています。
こうした施策の結果、採用競争力の向上や採用コストの圧縮といった効果が見込まれます。たとえば、採用数全体の1%でも採用マーケティング経由で獲得することができれば、年間で400万〜600万ものコスト削減につながる計算になります。
バックオフィスも収益貢献。企業のDXには「気合い・経験・度胸」が大事

同社では今後の展望として、採用だけでなく人事全体の生産性向上を目指していくとのこと。たとえば経費データや部署データは社内に点在・サイロ化しており、無駄な業務プロセスも少なくありません。そこで現在構想が進んでいるのが、全データにマスターIDを付与し一元管理する『マスターID構想』です。
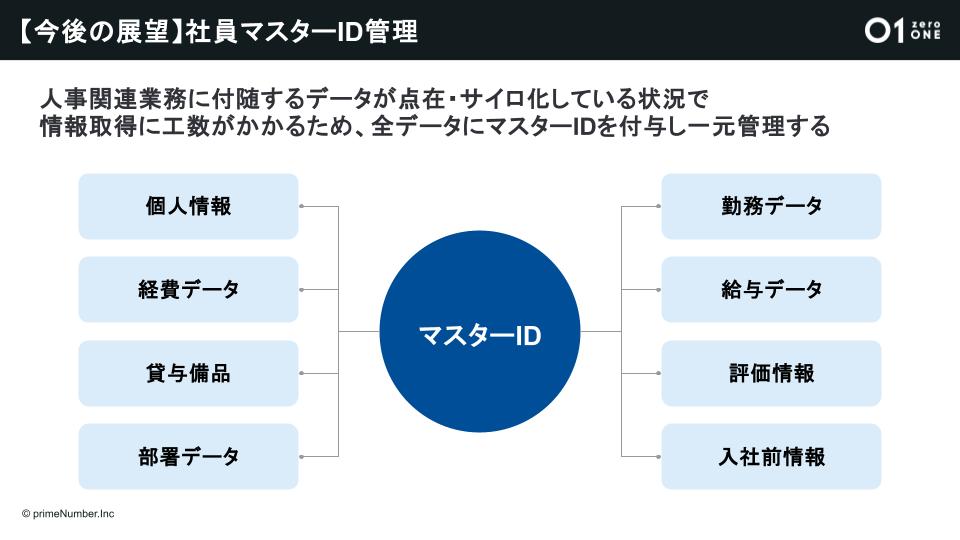
この構想を実現できれば、部署の垣根を越えてスムーズに情報を取得できるようになり、業務効率とスピードの向上が見込まれます。入社前の応募や採用データから、新しい採用につながるアクションをできるケースもあり、今後人事として更なるデータ活用に取り組まれるそうです。
「採用領域のデータ活用を進めたことで『バックオフィスも生産性貢献という観点から収益貢献ができる』と意識が大きく変化しました。そして、企業のDXではHow(進め方)だけでなく、KKD(気合い・経験・度胸)も実は大事だったのだなと実感しています。IT企業はなんとなくクールでドライ、粛々とデジタル活用を進めるイメージがありますが、旗振り役の人が全体を巻き込むような熱量を持って取り組んでいくことが大事だと考えています。
今回のセッションの内容は、まだまだ入り口に立ったレベルです。これからも私たちは力を入れていきますので、データ活用に取り組む企業・担当者の方はぜひ一緒にがんばっていきましょう!」(石橋氏)
Sansan社の人事領域のデータ活用を進められるきっかけとなったTROCCOに興味を持ってくださった方は、ぜひお気軽にお問い合わせください。
[service_banner]





